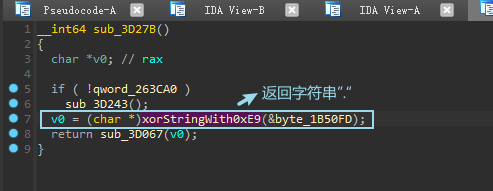
分析环境
- 操作系统:Win10 20H2
- 分析工具:IDA 7.7
注意事项
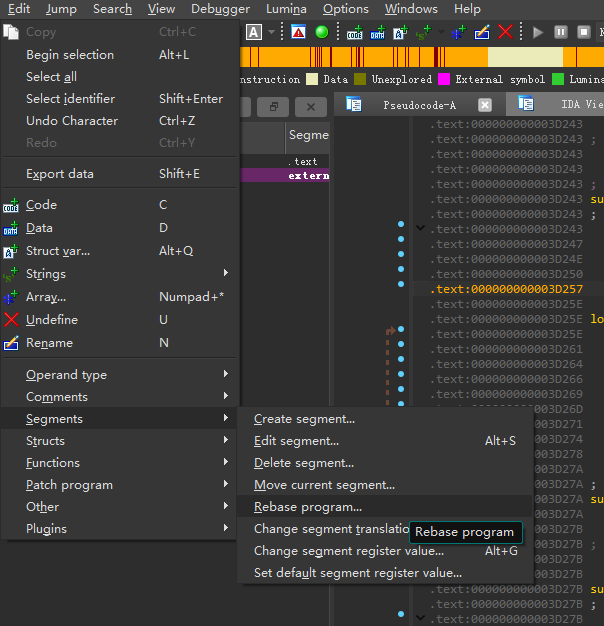
实际分析时函数名以及变量可能与我的不同,由于IDA对未导出的函数是通过偏移地址进行命名,故可以通过Rebase的方式来实现函数名同步,方法如下所示:
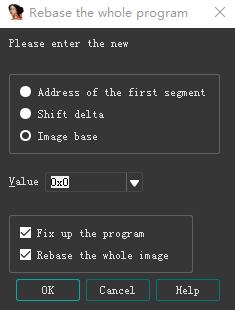
Edit -> Segments -> Rebase program
![]()
Value设置为0,这样就可以使得未导出的函数名一致了,但是变量名仍然不同,需要根据实际情况进行判断
![]()
分析过程
main部分
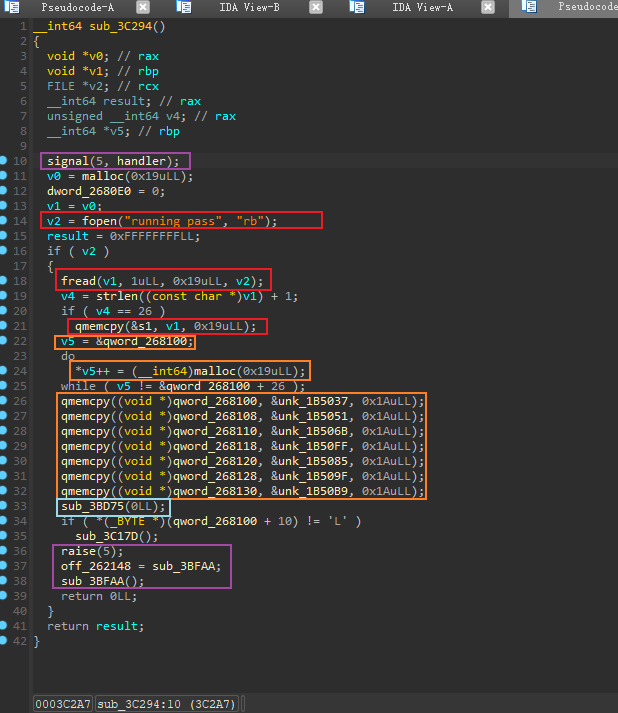
首先搜索并进入main函数,F5进入伪代码,发现下方有一个死循环,无用;因此只关心上方的
sub_3C294![]()
进入
sub_3C294,这部分按照不同颜色的方框归类进行分析![]()
红色方框:读取running_pass这个文件的前25个字节,存储到未初始化的全局变量s1中
橙色方框:
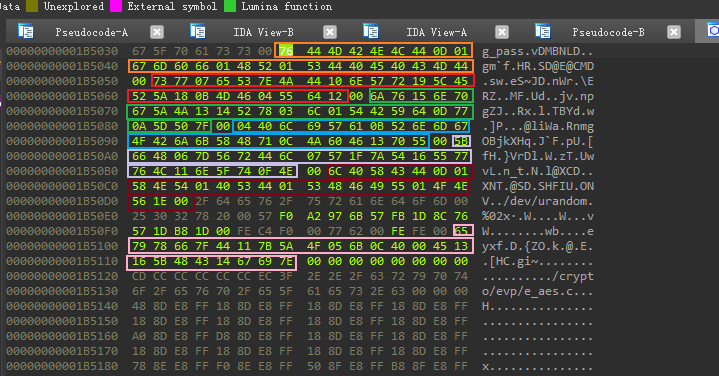
首先初始化一个指针数组,这个指针数组包含7个指针,每个指针指向一块大小为25字节的内存空间;指针数组的首地址为0x268100,由于encrypt程序是64位的ELF,因此每个指针都是8字节
接着,将这7个指针指向的缓冲区,分别用从地址0x1B5037开始(如下图所示)的大小为25字节的字符串进行填充,通过Hex View可以查看这些字符串
![]()
蓝色方框:进入
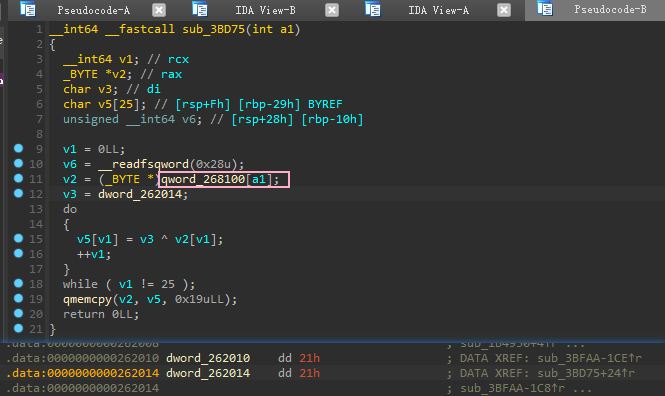
sub_3BD75,这个函数会传入一个参数,通过该参数选择上述7个指针中的某一个,取出其中的字符串,用0x262014地址处的值与字符串中的每个字符进行异或运算。此时地址0x262014保存的值为0x21(这个值后期会被修改)。取出的是第一个指针指向的字符串内容,经过异或运算后可得到新的字符串 “Welcome, FLAG is readable”。为了方便分析,我们可以通过快捷键”N”,将sub_3BD75重命名为initStringViaXor![]()
紫色方框:在程序一开始,就调用了signal函数,将信号5的处理函数设置为了handler,进入handler我们可以看到,这个处理函数就是
sub_3BFAA;所以后文处的raise(5)其实就是调用sub_3BFAA,当然这里IDA也帮助分析了出来。至此sub_3C294的主体流程分析完,接下来进入sub_3BFAA继续分析![]()
进入
sub_3BFAA,这部分的逻辑从伪代码看比较乱,因此在分析时需要结合汇编追踪关注的变量是如何变化的。由于伪代码较长,这里分为两部分看,首先是第一部分,包含4个单独的循环,每个循环进行5轮。当然这部分整个都在一个大的while循环内,这个大循环也是进行5轮![]()
首先是调用了
__readfsqword(0x28),这是一个栈保护过程中获取canary的部分,其本身并不用关心,由于这个值保存在返回地址上面用于防止栈溢出(rbp-4的位置,不过汇编中通过rsp来进行寻址),因此刚好也就在该函数局部变量的后面(局部变量通常位于rbp-8开始,汇编中通常使用rsp来寻址)。因此这里IDA分析的时候使用了v22[5]来保存它,也是因为后期v22[0]~v22[4]会暂存5个字符的指针,它们作为局部变量存储在栈中,刚好在canary的前面接着调用了
initStringViaXor,也就是经过重命名的sub_3BD75,经过异或运算后生成一个字符串。注意这里传入的参数为v21,该变量在第一轮大循环时,v21被赋值为1,因此得到的字符串的值为“RV&Dr_ke1OvS8}ds{9*lg%tE3”,并且将这个字符串,赋值给v2接下来有一个操作,初始化了一个byte数组,这个数组从0x2680A8开始一直到0x2680AC,共5个字节。用来初始化这些数组的值为地址0x2680BB+0x5(即0x2680C0)开始的连续5个字节的值。但是进入后发现,0x2680C0位于
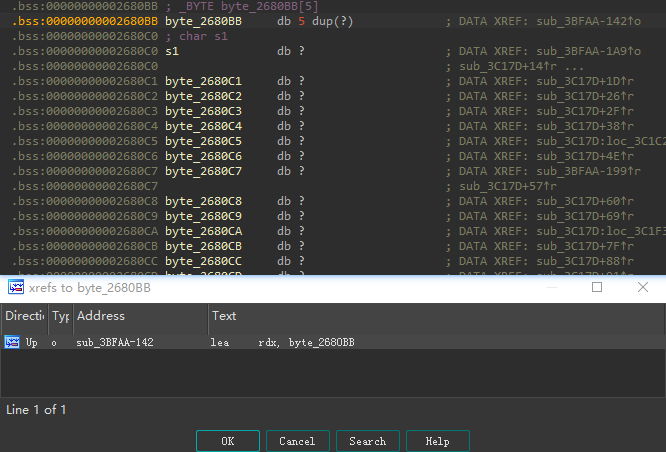
.bss段,并且发现刚好是字符串s1的地址开始处,根据前面的分析,我们知道字符串s1存储的是running_pass文件的前25个字节。所以这一步,就是将这25个字节的前5个字节,赋给数组0x2680A8开始的5个字节地址空间中![]()
接下来进入一个循环,依次从0x2680A8开始,也就是上面被初始化的这个数组中取一个字符,赋值给v5,然后在字符串”RV&Dr_ke1OvS8}ds{9*lg%tE3”中找到字符v5第一次出现的位置,并将这个位置记录在数组v22中(v22是一个char类型的指针数组,指针指向字符串中字符的位置);若未找到,则保存一个指向截断符00的指针,这个指针位于字符串+0x25偏移处
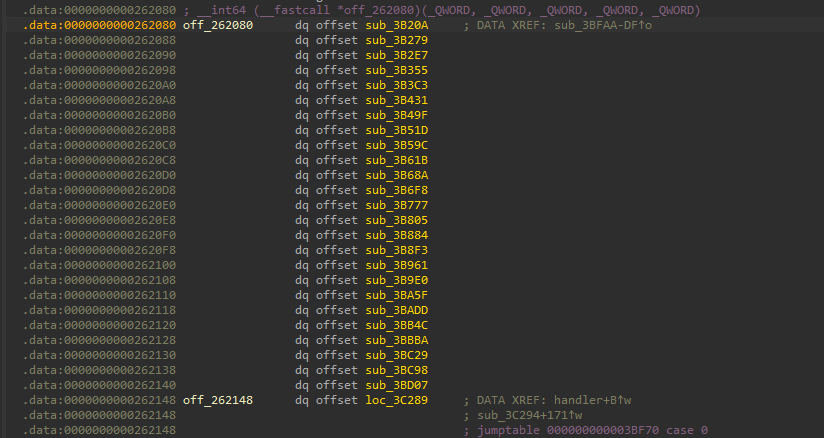
接下来是第二个循环,这个循环非常关键。这次将v22数组中存的值(字符的位置),依次减去字符串的首地址,得到一个偏移量,这个偏移量就是字符在字符串中的偏移量。然后根据这个偏移量调用不同的函数,调用的函数通过0x260280加上一个偏移获得
![]()
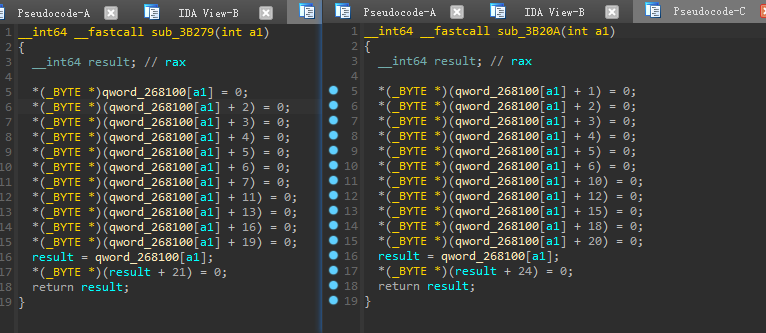
进入前两个函数查看其伪代码
![]()
如上图所示,0x268100正是指针数组的首地址,a1指定了指针指向的字符串,这里是第一个字符串,其值为”RV&Dr_ke1OvS8}ds{9*lg%tE3”,将这个一维数组看成一个5x5的矩阵,那么这两个函数的作用如下:
![]()
可以看到,前两个函数,根据传入的下标,将除下标外,其对应位置所在的横行、竖行、对角线的其他元素全部清零。由此可以发现,这是五皇后算法中的一步(具体可以参考八皇后,本题降低难度选用了五皇后算法,只有10种可能的解),因此可以知道,这个循环,就是根据筛选出的下标,对其他横行、竖行、对角线的值进行清空的操作。
第三个循环用于将根据char类型指针数组v22中保存的指针,将对应的字符存到数组0x2680A8里;这里和先前将s1字符串中的字符保存到数组中不同的是,如果这些字符不在字符串”RV&Dr_ke1OvS8}ds{9*lg%tE3”中, 那么存到数组0x2680A8中的值为0
![]()
接下来继续细看第四个循环,这里我把前后对变量的处理也截图进来了,因为它们都很关键。这个循环,将数组0x2680A8中保存的字符对应的ascii值依次进行异或运算,得到一个值保存到变量v16中。然后将v16与3进行与运算,得到一个0~3范围的值,再将这个值与地址0x262014处保存的值(在第一轮大循环时,这个值为0x21)进行异或运算,结果保存在地址0x262014
![]()
接下来进入switch语句,循环开始前,有几个赋值语句,对应了函数开头几个未知的赋值语句,这个其实就是push和pop的对应,用于变量的存储与恢复,没有意义,不用关心。
然后我们具体来看switch语句,这里伪代码不清晰,咱们直接看汇编。从汇编中可以看到,switch用于条件判断的值受到寄存器r12影响,r12寄存器的值仅在函数开头被寄存器rdi赋值,整个函数流程中没有再发生变化,再往上跟,可以发现rdi的值,在程序开头被设置为了1!这个rdi,也就是伪代码中定义的变量v21。
![]()
因此,我们可以把这里的v23改成v21,很明显,IDA分析错了!实际上这里的switch语句,就是让v21的值在每轮循环递增,所以我们直接看case5的情况。
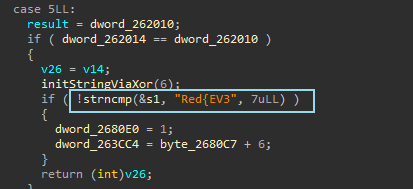
首先要判断dword_262014与dword_262010的值是否相等,这里实际上是判断是否满足五皇后达成的条件,因为前面会根据每个字符的值进行异或,并最终修改全局变量dword_262014的值(初始为0x21)。如果所有字符串达成了五皇后条件以后,走到这一步的时候,dword_262014的值会被修改回0x21,dword_262010只是做了一个备份,用于后期判断
接下来的判断很关键,会判断字符串s1的前7个字节,与字符串”Red{EV3”是否相同,如果相同,则会修改位于地址0x263CC4的全局变量的值,这个全局变量影响后面的加密算法的选择,这里也是main部分中唯一对解密过程产生影响的地方。至于为什么是用s1进行比较,而不是用数组0x2680A8的值进行比较。是因为数组0x2680A8中只暂存5个字符。它是在对s1字符串进行一次次筛选重排中的一个步骤。
![]()
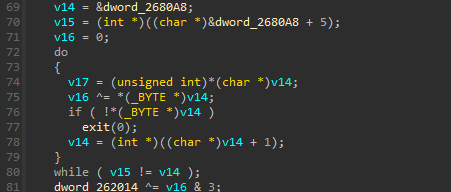
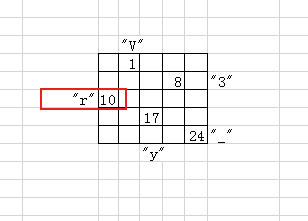
接下来我们来看字符串中的前5个字符”Red{E”,它们在字符串”RV&Dr_ke1OvS8}ds{9*lg%tE3”中的下标分别为[0,7,14,16,23],换算在5X5矩阵中如下:
![]()
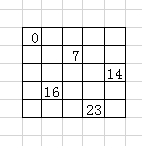
此时,打住,在前面第4个循环的时候,做了这样一件事,就是将5个字符进行异或,然后和3进行与运算,再去异或dword_262014的值。我们做这个5个字符做如下操作,得到0x20。也就是说,此时dword_262014的值被修改为0x20
![]()
这个时候,我们把新的dword_262014的值代入到下一轮大循环,此时v21的值已经变为2
![]()
接下来,我们0x268100这个指针数组中第二指针指向的字符串,再进行一次运算,得到了新的字符串为”JV5NPGzj34rX#L!tbyD-W*}p_”
![]()
这个时候我们回到switch语句这里,因为它总共会进行5轮大循环,由于每轮循环v21的值会增加,因此每轮循环选择的字符串也有所不同。因此我们刚刚计算出的字符串”JV5NPGzj34rX#L!tbyD-W*}p_”用于计算s1字符串中第5~9个字符的值。
![]()
目前,已经显示了两个字符,也就是“V”,”3”,这俩字符在字符串”JV5NPGzj34rX#L!tbyD-W*}p_”中的下标分别为1和8。我们在5X5矩阵的图中先标记出来。
字符串”JV5NPGzj34rX#L!tbyD-W*}p_”
于是我们自己编写一个五皇后的代码,算出所有的可能性,代码如下:
python1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43class NQueens:
def __init__(self, size):
self.size = size
self.solutions = 0
self.solve()
def solve(self):
positions = [-1] * self.size
self.put_queen(positions, 0)
print("Found", self.solutions, "solutions.")
def put_queen(self, positions, target_row):
if target_row == self.size:
self.show_full_board(positions)
self.solutions += 1
else:
for column in range(self.size):
if self.check_place(positions, target_row, column):
positions[target_row] = column
self.put_queen(positions, target_row + 1)
def check_place(self, positions, ocuppied_rows, column):
for i in range(ocuppied_rows):
if positions[i] == column or positions[i] - i == column - ocuppied_rows or positions[i] + i == column + ocuppied_rows:
return False
return True
def show_full_board(self, positions):
for row in range(self.size):
line = ""
for column in range(self.size):
if positions[row] == column:
line += "X "
else:
line += "0 "
print(line)
print("\n")
def main():
NQueens(5)
if __name__ == "__main__":
main()列出所有的可能性后,刚好找到一个可以匹配当前情况的五皇后状态,如下图所示:
![]()
此时补充完此图的全部位置,并标注其对应字符,可以得到,因此我们可以补全s1字符串为”Red{EV3ry_}”
![]()
接下来关注对全局变量0x263CC4的设置:
![]()
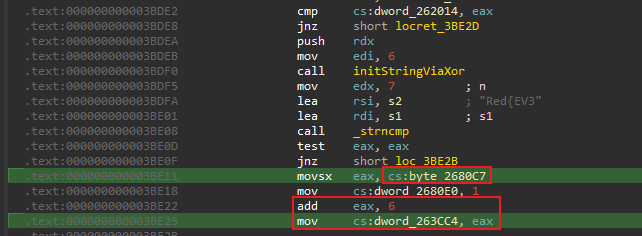
由图所示,可以很清楚的看到,这里将0x2680C7这个地址处对应的值(一个字节大小),经过符号扩展后赋值给了eax,再对eax+6,赋值给了全局变量0x26CC4,因此这里的0x2680C7就显得很重要。
![]()
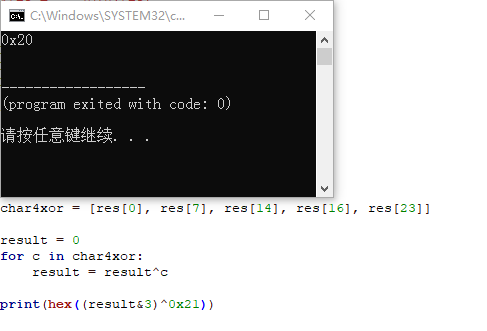
进入查看,发现又位于.bss段,往上看刚好是s1字符串的起始处,又因为只有满足前7个字符相同这个条件才能走到这一步,因此可以直接拿7个字符先匹配过来,刚好对应地址0x2680C0~0x2680C6处的值,接下来的0x2680C7的值,根据前面推算,即字符”r”,其对应的十六进制值分别为0x72,再进行加6,可以确定全局变量0x263CC4地址处的值为0x78中的一个。至此
sub_3BFAA函数部分分析完成,其核心功能是通过五皇后算法,设置了一个全局变量的值为0x78










init部分
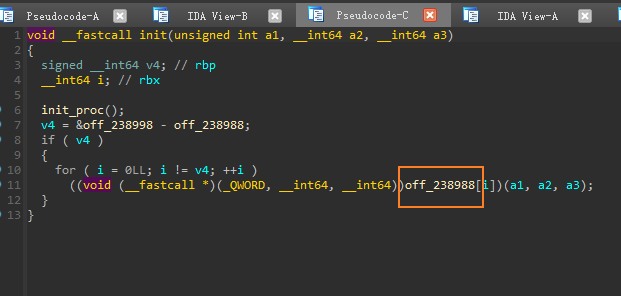
由于main函数中并没有实现对文件加密的功能,目光只能聚集到先于main调用的init和init_array,在执行ELF文件时,会优先调用init函数,以及init_array数组中的所有函数。下面开始分析init函数的部分:
通过对
main函数进行xref(快捷键”X“),可以找到其上层函数_libc_start_main,这里可以看到init函数![]()
进入
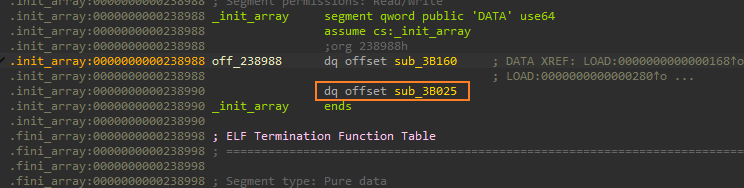
init,前面是init_proc用于初始化进程没什么用;接下来是调用偏移0x238988处的一系列函数,实际上就是遍历init_array数组中的函数,依次进行调用。进入init_array数组,一共两个函数,依次点进去,发现sub_3B160没有做什么操作,因此只能关注函数sub_3B025了![]()
![]()
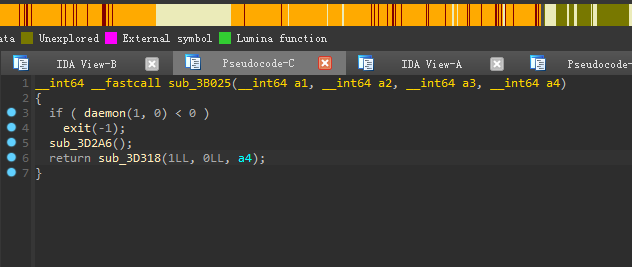
进入函数
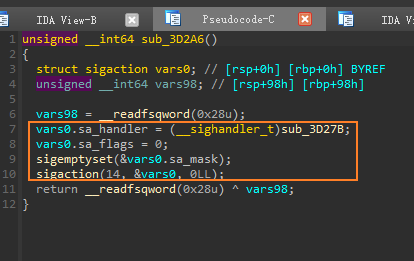
sub_3B025,这里一共有2个函数,首先来看sub_3D2A6,该函数只做了一件事,设置sigaction结构体,将信号14的处理函数设置为sub_3D27B。两个__readfsqword没什么用,读取和校验canary的值,是检查栈溢出的。![]()
![]()
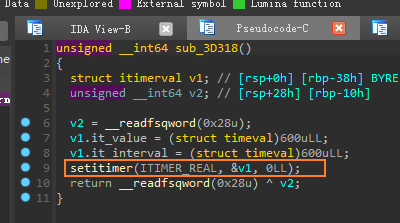
再看
sub_3D318,这个函数也只做了一件事,调用setitimer设置超时时间为600s,ITIMRE_REAL按实际时间计时,计时达到将给进程发送SIGALRM信号,即信号14。而信号14的回调函数在前面被设置为了sub_3D27B。所以,这个程序就会每10min调用一次sub_3D27B这个函数,重点也是这个函数。![]()
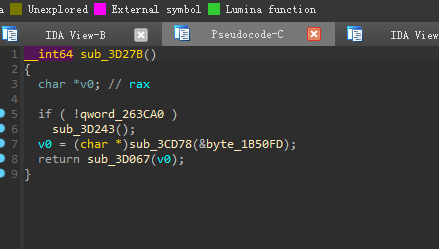
进入
sub_3D27B,情况如下:![]()
首先判断地址0x263CA0处是否为空,这个地址同样位于.bss段,未经初始化,在执行init_array数组中的函数时肯定没有初始化,因为这个函数本身就是最早执行的。
![]()
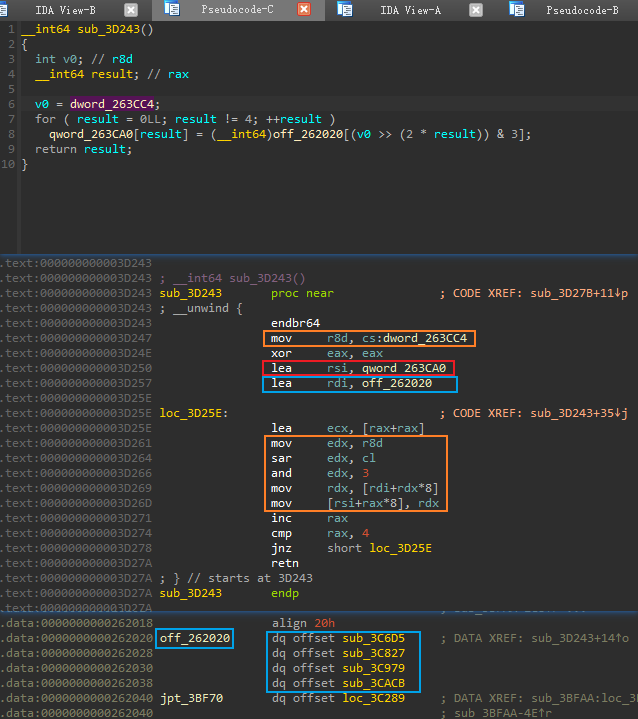
因此进入
sub_3D243查看。可以看到,这里根据先前的全局变量0x263CC4,计算出一个偏移值,这个值的范围在0~3之间,然后根据这个偏移在0x262020处的数组中(蓝色方框框出)找到特定函数地址(这是4个不同模式的AES加密函数),写入到0x263CA0开始的数组中。由于我们已经在main部分确定了全局变量的值为0x78,因此数组0x263CA0存的顺序如下:
- [sub_3C6D5、sub_3C979、sub_3CACB、sub_3C827]
![]()
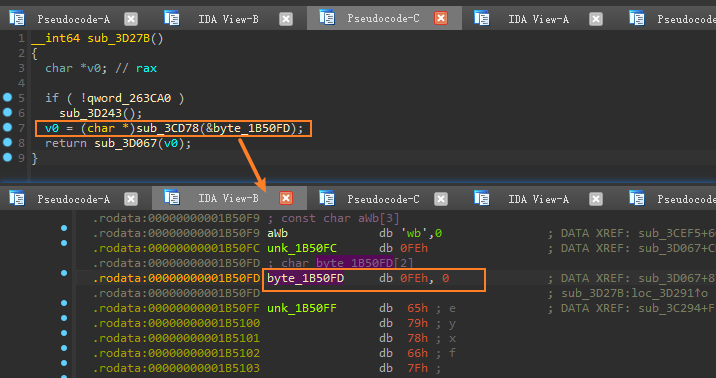
完成对数组的赋值工作后回到
sub_3D27B,接下来关注sub_3CD78,该函数传递了一个参数,这个参数的值为0xFE![]()
进入
sub_3CD78,这里先判断buf是否为空,一开始肯定是空的,所以需要调用
sub_3CCD9,进入sub_3CCD9,如果buf为空,则会先为其分配空间,然后再调用sub_3CD78,这里需要注意一点,此时参数传递的是aW,进入查看,发现是一段写死的数据。![]()
再回到
sub_3CD78,由于已经为buf分配了空间。接下来会对0x2680A0地址是否有值进行判断,这是一个临时存放解码数据的缓冲区。第一次执行时同样不会有值,走else逻辑,进入蓝色方框区域给0x2680A0开始的地址申请一块128字节的内存空间,然后将a1指向的字符串的值依次与0xE9进行乘法运算,然后再保存到0x2680A0地址开始的内存空间中。注意一点,这里的a1的值不是0xFE,而是在
sub_3CCD9中调用时传递的aW![]()
编写简单的脚本进行解析,可以得到aW传递的字符串实际是
/proc/self/exe。返回结果保存在v6,python1
2
3
4
5
6
7e1 = [0x57, 0xF0, 0xA2, 0x97, 0x6B, 0x57, 0xFB, 0x1D, 0x8C, 0x76, 0x57,
0x1D, 0xB8, 0x1D]
for x in e1:
s = str(hex(0xE9*x))[4:]
res.append(chr(int(s, 16)))
print(''.join(res))此时返回到
sub_3CCD9中,在Linux中,/proc/self/exe是一个符号链接,代表当前程序。通过调用readlink读取它的源路径就可以获取当前程序的绝对路径。然后,通过一个循环,寻找绝对路径最后一个\或者/之后的字符串,也就是程序自身的真实名字,将其保存在buf中![]()
此时,从
sub_3CCD9中回到sub_3CD78。可以发现,在buf为空的情况下,会调用sub_3CCD9初始化buf缓冲区,并赋值为当前程序名的字符串。此时,我只需要关心if部分,因为在先前sub_3CCD9中调用sub_3CD78后,地址0x2680A0处已经有值,存放的是proc/self/exe,此时,先将0x2680A0中保存的值全部清除
打开自身程序读取前4个字节,ELF文件的前4个字节为
.ELF,对应的ascii码为(0x7F,0x45,0x4C,0x46)接下来用第2~4个字节相乘,取低字节再加1(刚好又是0xE9),然后与传入的a1字符串(此时为0xFE)进行异或,得到字符串
.,也就是当前目录,然后返回![]()
![]()
回到上层调用
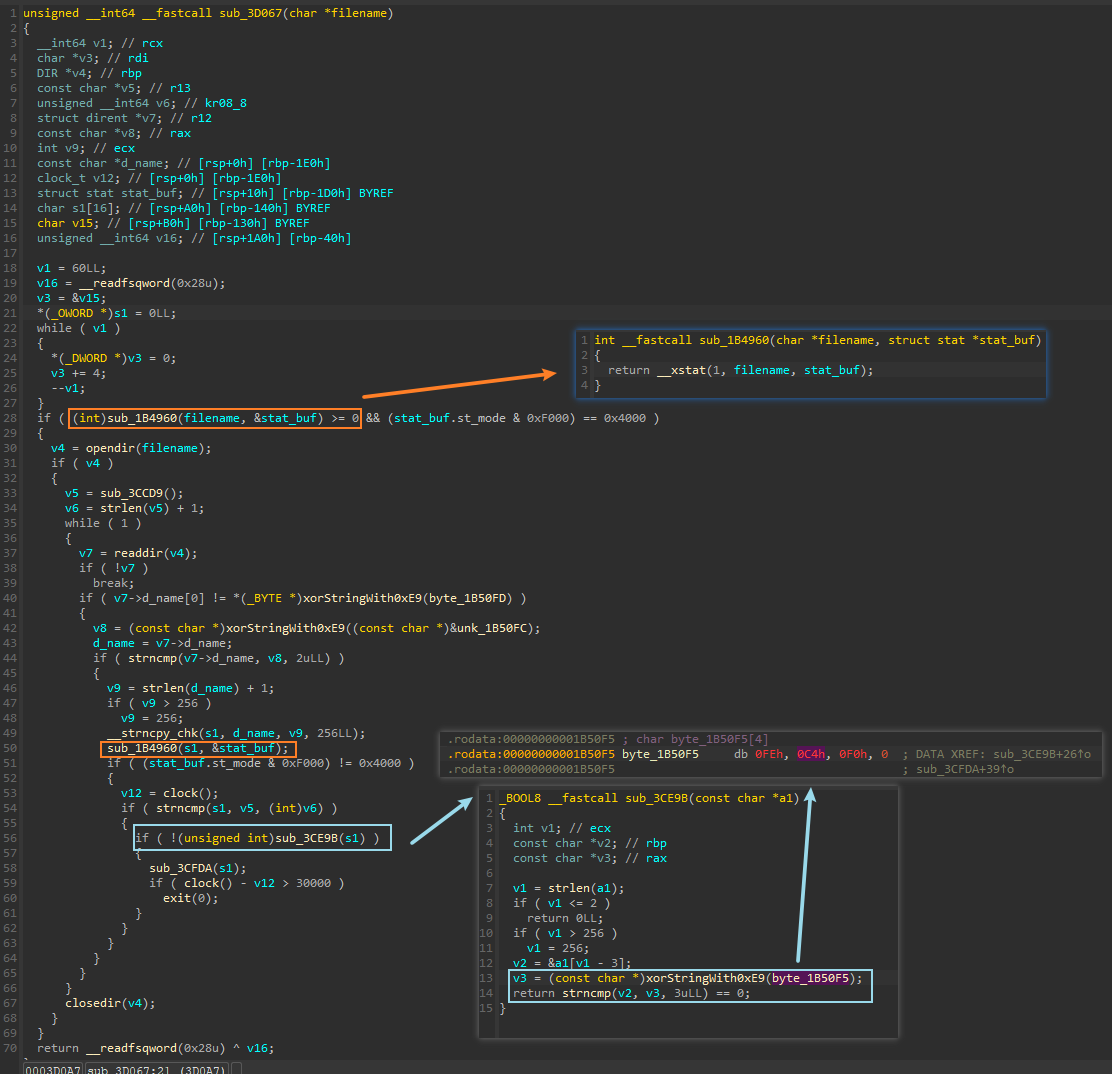
sub_3D27B,将刚刚分析的sub_3CD78改名为xorStringWith0xE9,然后进入分析sub_3D067的调用过程,参数传入为字符串"."![]()
进入
sub_3D067,这部分很简单,核心函数在后头,先梳理下流程:调用
sub_1B4960,该函数实际调用了_xstat用于获取文件属性,这些属性会保存在传入的stat_buf结构体中。然后通过st_mode字段判断是否为目录文件(第14位被置位,即0x4000)。这里传入的是字符串".",表示当前目录然后调用
opendir打开当前目录,进入循环调用readdir遍历当前目录的所有文件;获取文件名,将其存入全局变量s1中(注意这里的s1和前面main函数中出现的s1指向的不是同一个地址),并筛选掉所有目录文件调用
sub_3CE9B,这个函数会判断文件名是否是.dp后缀,如果是的话,则会返回1;否则返回0,则会进入sub_3CFDA,从而给所有不是 .dp 后缀的文件进行加密![]()
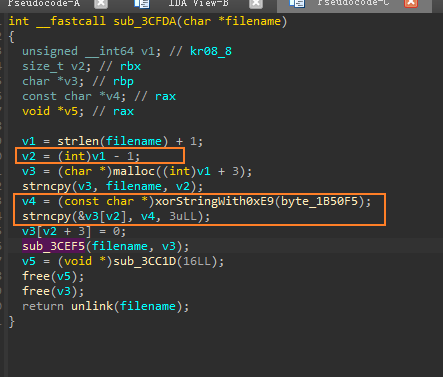
进入
sub_3CFDA,橙色方框的部分会将.dp附加到原文件名后面,然后将原文件名和修改后的文件名,作为参数传入sub_3CEF5![]()
进入
sub_3CEF5,这是最为关键的用于加密的函数,具体操作如下:橙色方框:生成一个16字节的随机字符串,赋值给变量v5
蓝色方框:打开原始文件,读取内容到变量v7中
红色方框:打开新创建的文件,用于将原文件内容加密后写入,文件描述符赋给变量v8
粉色方框:
选则随机字符串的第4个字节,加上索引i(范围0-2,从0开始,每轮循环递增),再和3进行与操作,得到一个范围在0-3之间的随机数,赋值给变量v6
将v6作为索引,选择数组中存放的加密函数,数组中加密函数的排列如下所示:
[sub_3C6D5、sub_3C979、sub_3CACB、sub_3C827]
将v7、v8、v5作为参数,调用从数组中选取的加密函数,进行三轮加密(每一轮需要重新在数组中选择加密函数,这些加密函数均为AES加密,但是加密模式不同)
![]()