前言
本篇作为AFL源码分析的最后一篇,完成了对fuzz执行过程中的核心函数fuzz_one及其辅助函数(均位于文件afl-fuzz.c中,上一篇分析的主要是该文件中的fuzz初始化部分)的分析。在完整跟完一遍AFL源码后,不禁感叹于作者在代码设计上的巧妙以及将遗传算法应用在fuzz领域的绝佳构思。相信读者在阅读完这部分源码分析后也会有着相同的感受。
关键变量
c
1 | EXP_ST u32 exec_tmout = EXEC_TIMEOUT; /* Configurable exec timeout (ms) */ |
核心函数
main(fuzz主循环部分)
c
1 | u32 seek_to; |
sync_fuzzers
c
1 | /* 这个函数的主要作用是进行queue同步,先读取有哪些fuzzer文件夹,然后读取其它fuzzer文件夹下的queue |
save_if_interesting
c
1 | /* 检查mem映射的这个case是否是interesting的,如果是,则将其保存到queue中,并返回1;否则返回0 */ |
simplify_trace
c
1 | /* 用0x80/0x01表示替换原本tuple中表示路径是否被命中的信息,进而简化跟踪;这么做是为了在每次crash |
trim_case
在fuzz_one中(5119行)被调用
c
1 | /* 在进行确定性检查(deterministic checks)时,修剪所有新的测试用例以节省周期。微调器将使用 |
calculate_score
在fuzz_one中(5143行)被调用
c
1 | /* 根据queue entry的执行速度、覆盖到的path数和路径深度来评估出一个得分,这个得分perf_score在后面havoc的 时候使用 */ |
common_fuzz_stuff
在fuzz_one中(5188行)多次被调用,首次出现在5188行
c
1 | /* 编写修改后的testcase,运行程序,处理结果以及异常情况。如需退出,则返回1,这同样是fuzz_one中 |
choose_block_len
在fuzz_one中多次被调用,首次出现在6352行
c
1 | /* 该函数用于帮助fuzz_one中的块操作选择随机块的长度,会返回一个大于0的值 */ |
fuzz_one
AFL中最长的函数(4999~6690),也是fuzz执行流程中最核心函数。这里按照阶段分布展开分析
初始化阶段
这部分主要是fuzz前最后的一些准备。包括了一些变量的初始化,映射case等,以及CALIBRATION阶段、TRIMMING阶段和PERFORMANCE SCORE阶段这三个比较简短的准备阶段
c
1 | /* Take the current entry from the queue, fuzz it for a while. This |
SIMPLE BITFLIP (+dictionary construction)阶段
在比特反转,根据目标大小的不同,分为了多个不同的阶段:
- bitflip 1/1 && collect tokens -> 按位取反 && 搜集token
- bitflip 2/1 相邻两位进行取反
- bitflip 4/1 相邻四位进行取反
- bitflip 8/8 && effector map -> 按字节取反 && 构建effector map
- bitflip 16/8 连续两byte翻转
- bitflip 32/8 连续四byte翻转
c
1 | /********************************************* |
ARITHMETIC INC/DEC 阶段
c
1 | /********************** |
INTERESTING VALUES阶段
c
1 | /********************** |
DICTIONARY STUFF阶段
c
1 | /******************** |
RANDOM HAVOC(随机毁灭)阶段
c
1 | /**************** |
SPLICING阶段
c
1 |
|
交互运作
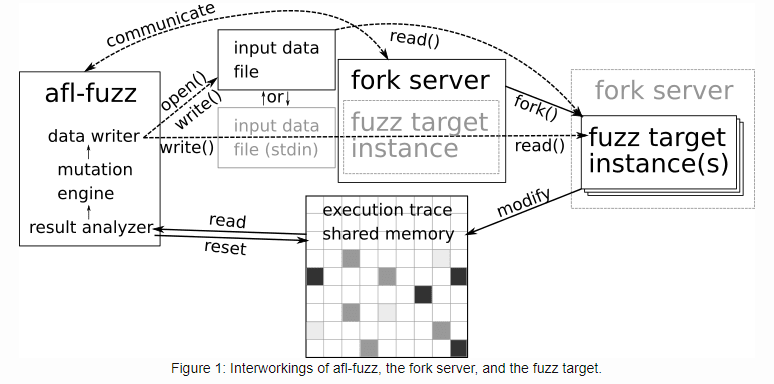
文章的最后,附上一张AFL执行时的交互工作图: