前言
这是一道和第三题一样,付出了我很多心血的题目。从周六开始,一直没有思路,开始想着就这样放弃了,毕竟只有那四位做出来,但是到了周日晚上,突然打开了思路,趁着题目还有1天时间,决定周一再尝试一次,周一花了一天时间,下班时已经解出Sm4算法,回家后也找到了进行异或的位置,实际上已经分析出了全部的加密算法过程。可惜,最终败在了反调试上,周二早上一上午都没有再更进一步,遗憾没能拿分。但是这次失败,让我学习到了很多,同时也打开了一些思路,也许可以用到未来的做题或者逆向上。因此,这里把本题的做题时的思路、期间遇到的砍、最后遇到的瓶颈以及解决方案都记录一下,这也是逆向经验的一部分。希望最后两道逆向题,可以有所作为,拿到些分。
6月2日将这篇发在了看雪(花了2天才写完,5月31日中午这题结束的),同时在晚上更新到了自己的博客。6月3日一觉起来,发现这篇被设置成了精华!!!超级开心!尽管这可能是段老大看我辛苦写了这么多,给的一些激励,但我依旧非常开心,有了极大的动力!现在,此时此刻,也争取,能够在端午假期完成剩下的题目。
准备工作
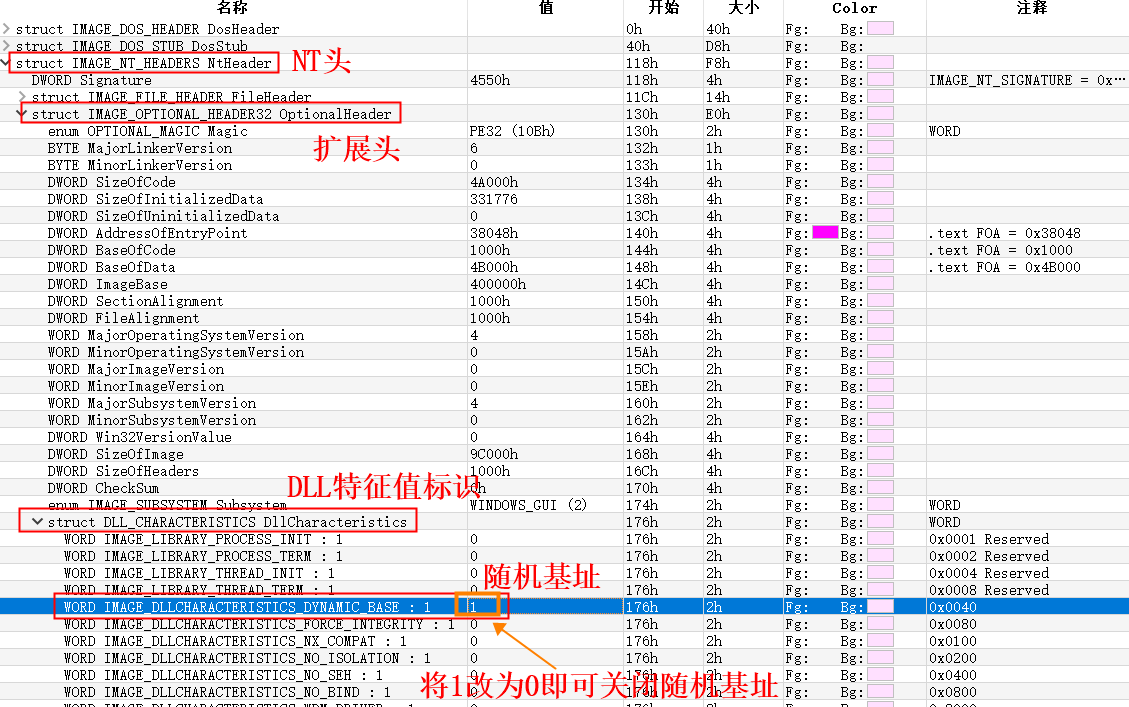
第一步,是令程序禁止地址随机化,这样程序每次从0x400000开始加载,而不是每次开机都会随机选择一个地址。虽然通过对IDA进行Segment的Rebase,也可以使其地址与OD/x32dbg一致(说起来,大佬们都是用x32dbg去做题,高博平时分析也是,看来以后做题时也得切换调试器了),但是用0x400000显然更好,并且也能与家里电脑分析时保持一致。具体手法如下图:
解题思路
试错
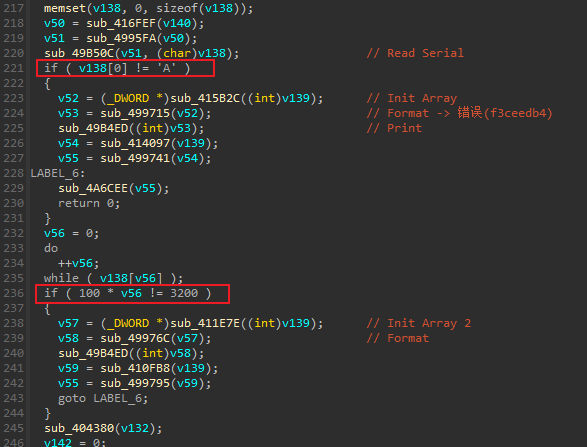
首先会判断输入的字符串首字符是否为’A’,以及长度是否为32位。
![]()
如果死在前两处校验,则会打印错误;否则会打印失败
![]()
寻找触发失败流程的代码块
![]()
- 这一步的目标是找到,执行后打印出”失败”的函数,往往这个函数,就是对变换后的字符串进行比较的函数(比如
strcmp,memcmp),确定字符串比较的位置后,再然后通过交叉引用向上溯源,就可以找到对字符串进行加密或者变换的代码了 - 首先是字符串识别,发现并没有找到”失败/错误”的字样。然后在
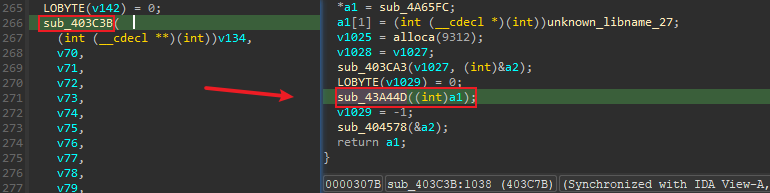
main函数中继续往后找,发现在执行完函数sub_403C3B后,就会打印失败。注意sub_403C3B是不能F8步过的,因为有反调试,F8直接就跑飞了,所以在该函数后下一条指令处下断,然后F9 - 接着进入
sub_403C3B,这是一个1000多行的函数,当然后面分析时会遇到一堆平均4000行的函数,甚至上万行无法进行F5查看伪代码的函数。我们用同样的方法定位到了sub_43A44D,该函数同样是不能F8步过,执行后打印失败,并且这又是一个1000多行的函数,这样下去就套娃了,并且会越来越难分析(我确实试图分析了几个,显然是没法达成目的的),因此这条路就走不下去
- 这一步的目标是找到,执行后打印出”失败”的函数,往往这个函数,就是对变换后的字符串进行比较的函数(比如
分析别的可疑代码
![]()
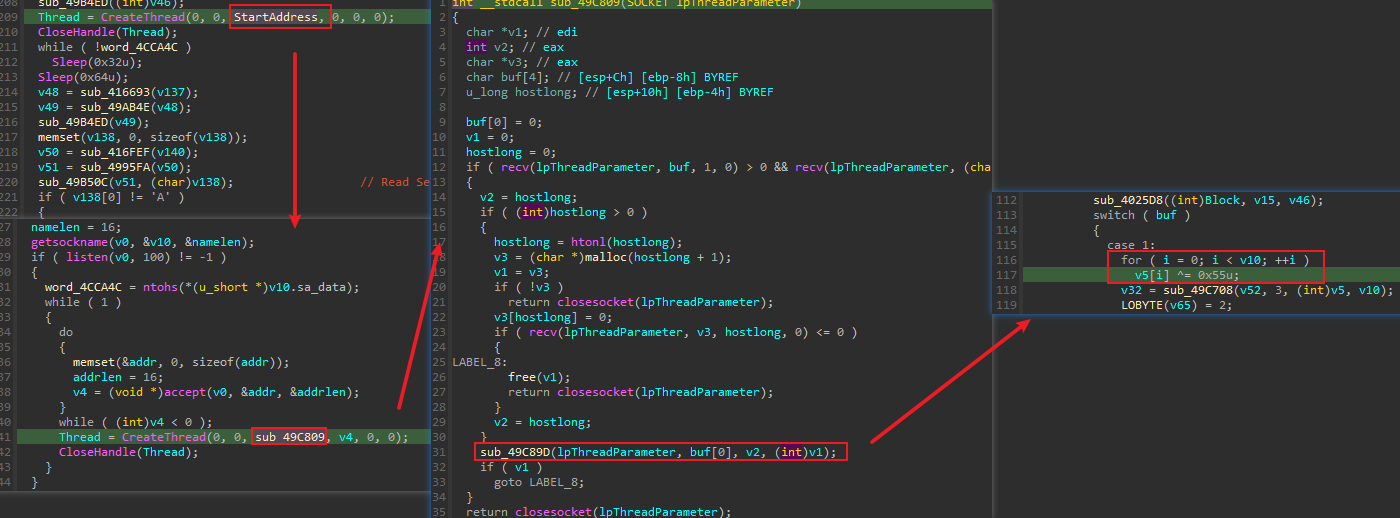
- 然后我对象发现在
main函数中的两个校验之前,有一个CreateThread,通常恶意样本就会通过此方式创建线程执行恶意行为。遂跟着她这个思路走了一遍,StartAddress指向的是一个创建socket的函数,它里面又创建了一个线程,指向关闭socket的函数。同样没有什么发现 - 接下来就是我和大佬之间的差距了,mb_mgodlfyn文章中指出,这个关闭socket的函数里有一个
sub_49C89D(他是通过对socket函数进行交叉引用+回溯找到这里的),该函数里面有一个逻辑是与0x55进行异或。虽然题目说了这里的代码确实是干扰项,但在对输入字符串进行处理时,确实有一个与0x55逐字节进行异或的操作(虽然这里的0x55异或也是干扰项),但如果很早发现这里,对解题是有一定帮助的,只能说大佬还是非常的细,这一点需要我去学习
- 然后我对象发现在
硬件断点寻找触发点
![]()
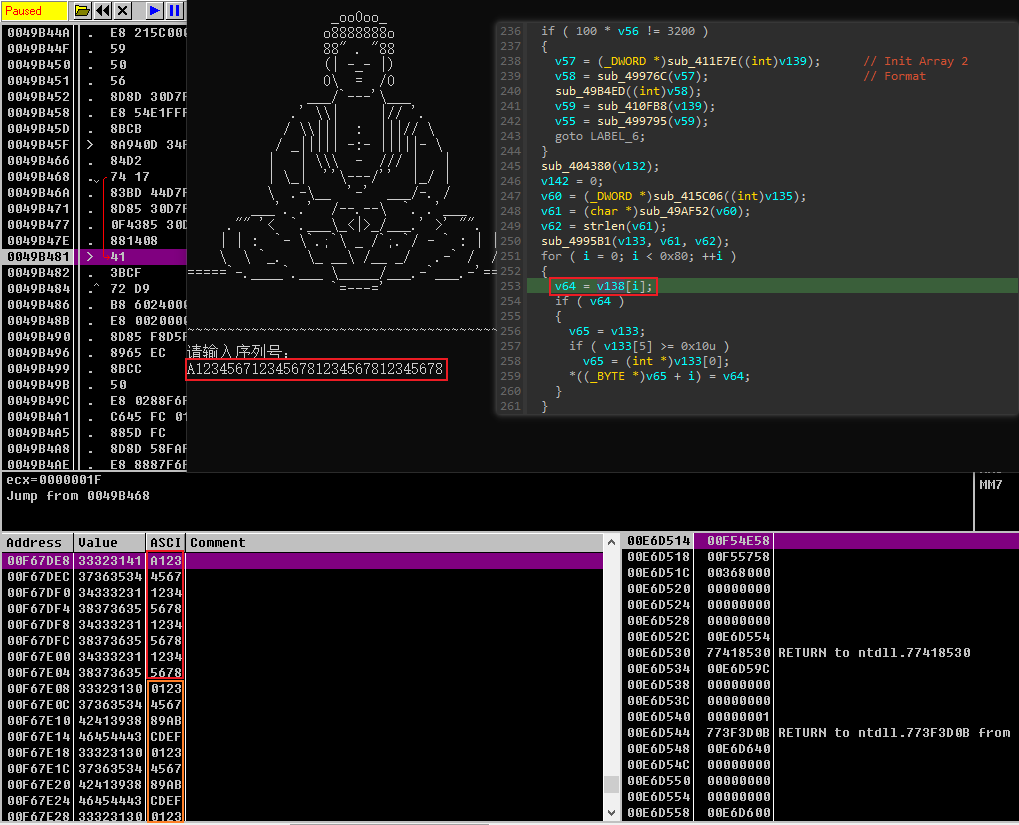
- 接下来考虑硬件断点,在main函数的后方,有一处对输入的字符串进行操作,这是能看到的最后一次对输入字符串进行操作的地方,这里会将输入字符串和内置的字符串进行一个拼接,其中开头32字节对应输入字符串的ascii码,在此下硬件访问断点即可
- 可惜,对该字符串的操作,仅仅只是被复制1次,例如从A处复制一份到B处,所以还得在B处下断,然后发现接下来又会从B处复制一份到C处,这样无线套娃,由于硬件断点只能下4个,内存断点容易不稳定。因此,最后我干脆直接F4的,在发现这个字符串至少被复制了50次后,放弃继续跟踪下去,路又走窄了
- 以上的尝试,就是从周六放题开始,至周日晚上进行的所有尝试
换思路
定位程序输出点
- 既然不能找到”失败”的字样,决定换个思路,毕竟”错误”的字样是可以找到的,只要输入的字符串长度不为32,或者第一个字符不为’A’,就会打印出”错误”
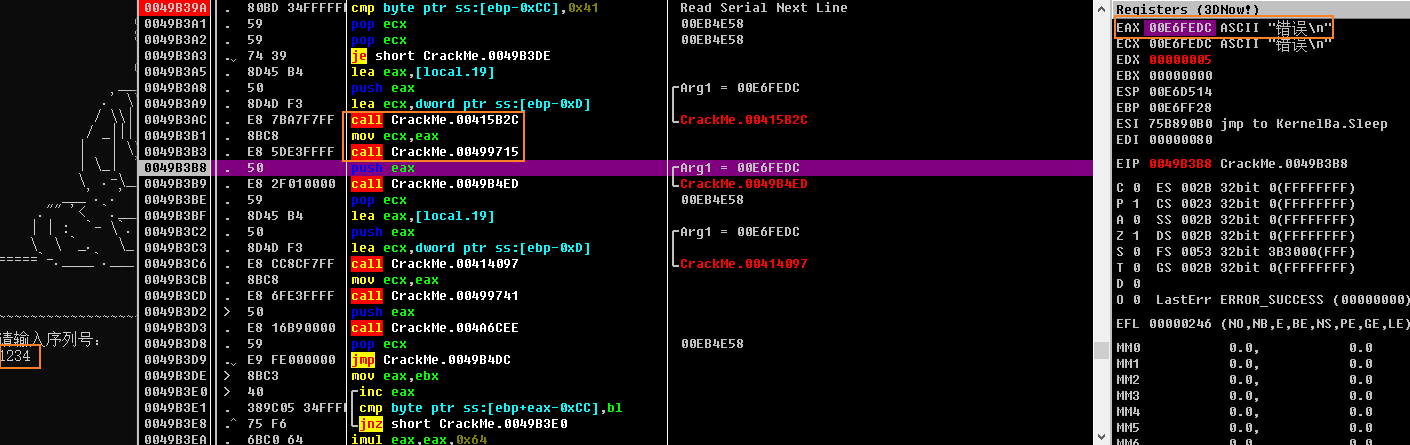
- 经过单步验证,输入字符串”1234”(符合首字符不为’A’的情况),会依次调用
sub_415B2C、sub_499715、sub_49B4ED这3个函数,其中执行完sub_49B4ED后,可以在eax指向的地址中找到中文字符”错误”,执行完sub_49B4ED后,会在命令行中打印出”错误”
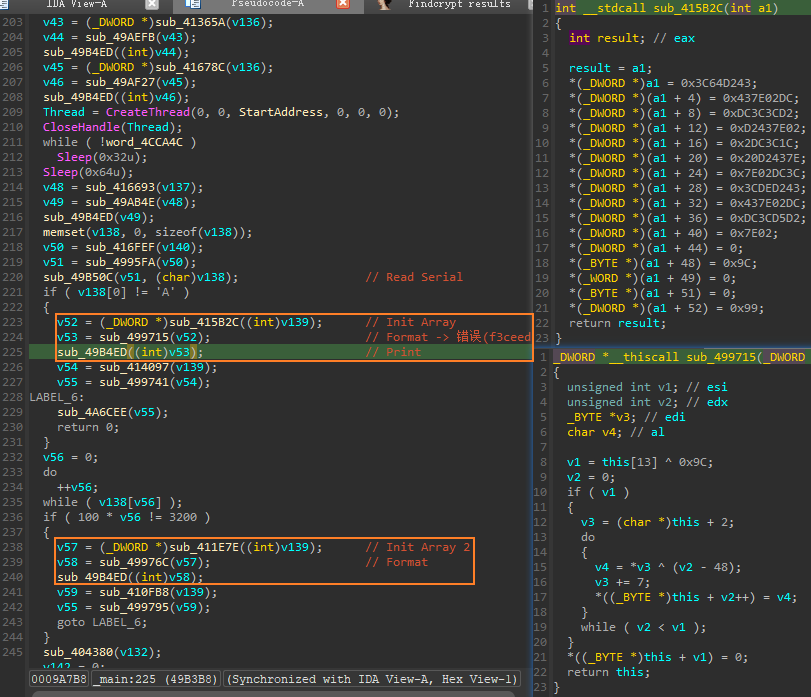
- 回到IDA中分析伪代码,通过观察可以发现,
sub_415B2C初始化了一个数组,然后sub_499715通过对数组中特定位置字符进行异或运算,解出”错误”对应的ascii码,然后再通过sub_49B4ED打印出字符 - 图中两处橙色方框,都是先初始化数组,再进行异或解密,然后打印字符;但是两处初始化数组的函数不同,解密函数也不同,用于打印字符的函数是相同的。根据这个特征,我们可以去找
sub_49B4ED这个函数的交叉引用,这样也许就可以找到打印”失败”所在的位置了
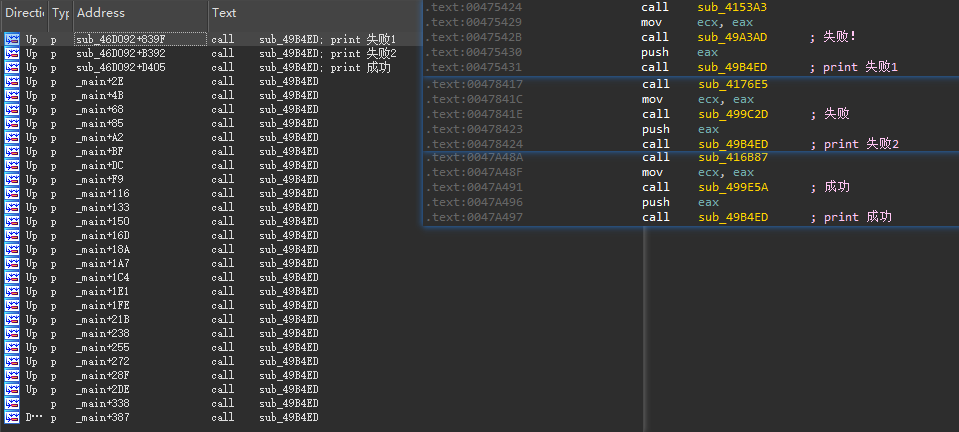
- 可以看到,在函数
sub_46D092中也有三处调用sub_49B4ED的地方。进入其所在汇编附近(这里无法看伪代码,因为函数过长,超过1w行,IDA无法解析,修改解析函数大小后,又遇到了stack frame is too big的问题,查阅资料后扔无法解决,因此只能看汇编),可以看到,在每次调用sub_49B4ED之前,都有2个call,猜测这两个call是分别用来数组初始化与解密得到中文字符用的。 - 因此只需要在OD/x32dbg中,Patch一下,直接call到这三处打印字符函数前初始化数组的地方,然后观察命令行中打印的字符。最后可以得到有两处打印”失败”,一处打印”成功”,在上图中,已经标注出
定位影响程序输出的逻辑(字符串比较)
- 在找到”失败/成功”的打印处后,我们就可以向上寻找类似字符串比较的地方。由于这三处打印所在的函数非常长且畸形,无法进行反汇编,大佬都采用Ghidra进行伪代码分析,听说Ghidra对畸形代码的支持较号,但是伪代码的效果就远不如IDA了。
- 纯看汇编肯定不行,上万行呢!好在IDA支持CFG的形式,这里需要按照上图所示,在选项中对Graph视图进行配置,调整最大结点数,然后就能够以”基本块+边”的方式对汇编进行查看,体验会稍好些
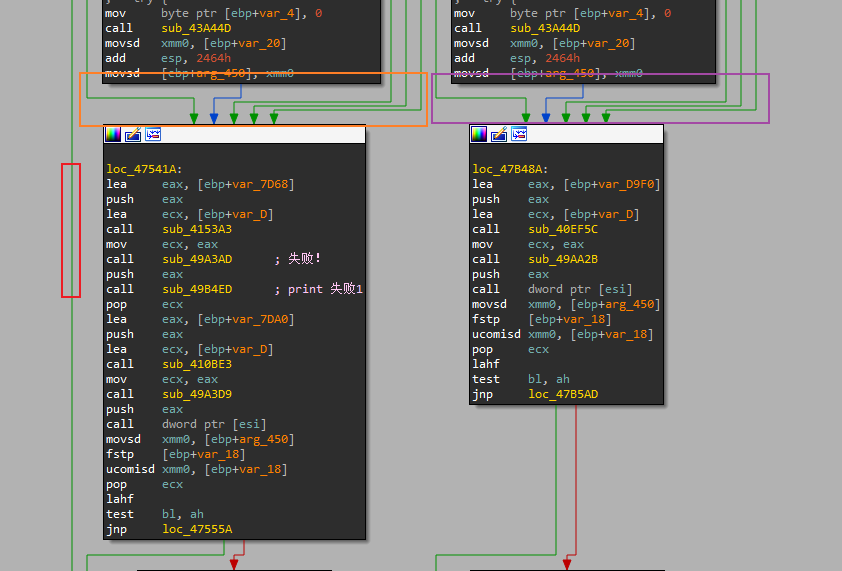
- 先找到
loc_47541A这个基本块,这个基本块里会打印出”失败”,我标记为”失败1”是因为,一共有2个失败,说明可能有2次判断,而这里打印”失败”的地址最靠前,说明会受到第一次判断的影响,因此被标记为”失败1”,也就先分析它 - 由图,可以看到,想要走到
loc_47541A这个基本块,需要经过橙色方框框出来的边;如果不走到这个基本块,有两种思路,一种是走紫色方框框出来的边,另一种是红色方块框出的这条边。经过简单的验证,可以先排除红色方框的这条边,因为这条边连接着的两个基本块,范围在打印”成功”之外,所以就不在考虑范围内了。接下来考察紫色方框框出的边 - 这里还有一点需要说明,就是图中左右两侧的边都是直上直下连接的,也就是说左侧是从上到下几乎完全线性的基本块,不会有边从左侧的基本块连接到右侧的基本块,右侧也几乎同样如此,所以此时基本可以忽略左侧的基本块,直接看右侧上方的调用链即可
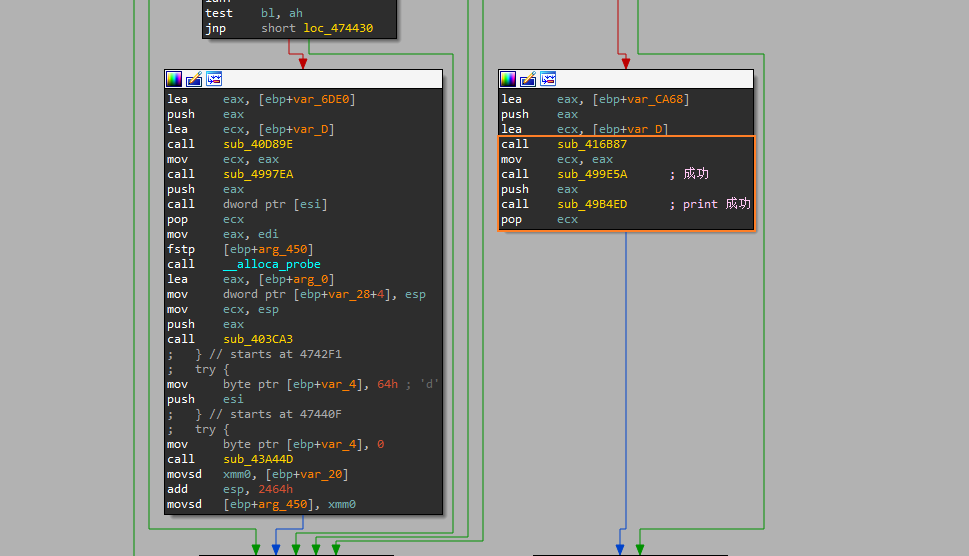
- 在往上查看右侧调用链时,可以发现打印”成功”的基本块,并且是在右侧。我们知道左侧的基本块会走到”失败”,现在我们要找到,导致走向失败或者成功的这个分支点在哪
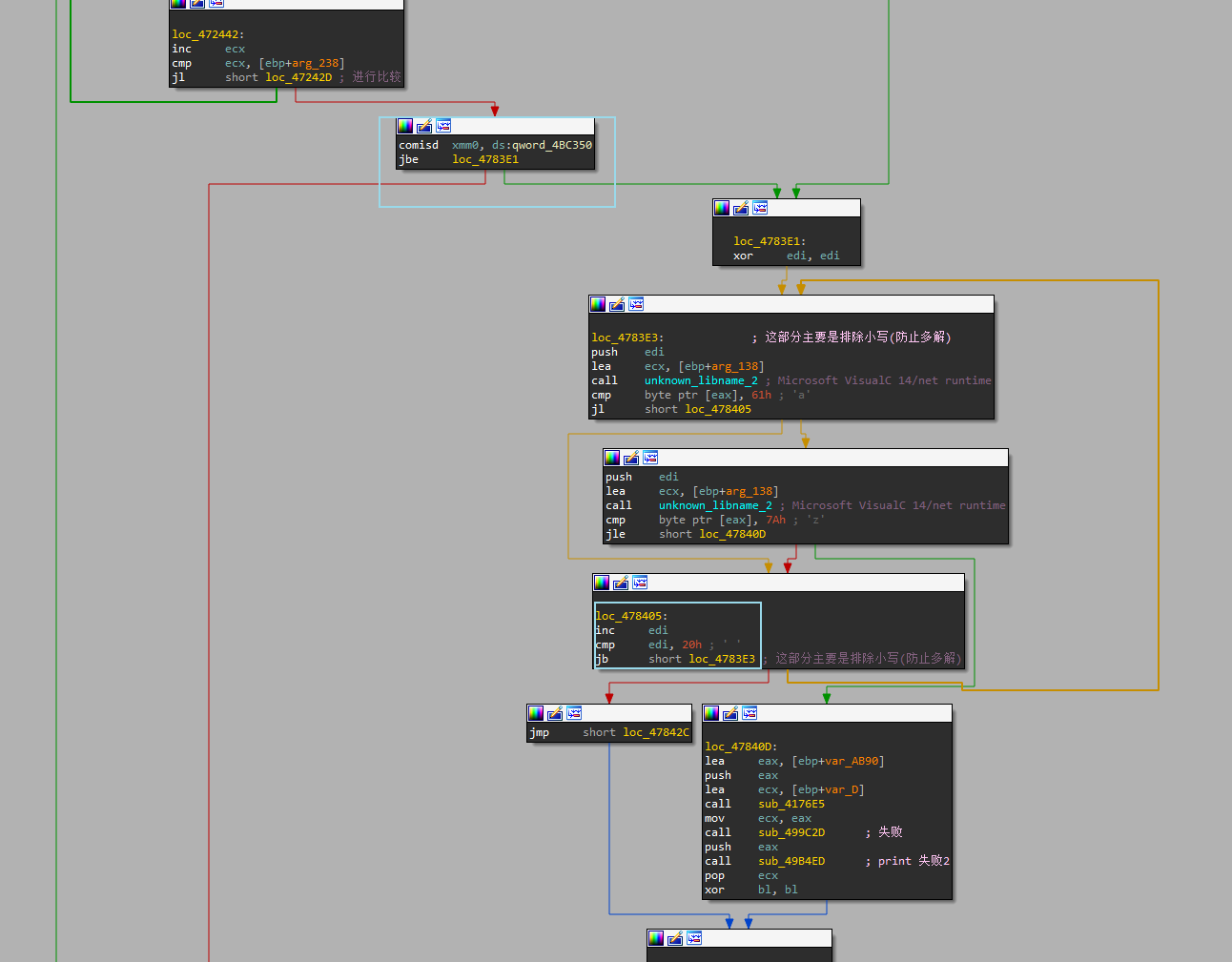
- 再往上看,就可以找到图中所示的这片代码块了,在这里,我们看到了”失败2”所在的代码块。这里重点关注两个蓝色方框
- 首先是上方的蓝色方框,这里会进行跳转,如果走了红色跳转,就会进入”失败1”,因此需要避免,需要程序走到绿色的分支
- 其次是下面的蓝色方框(位于
loc_478405),这里是一个循环,和上方的代码块loc_4783E3是关联的,IDA没有完全分析出,进入OD下断(当然先把前面的分支跳转patch掉,使之可以走到此处的代码块)可以发现,这一块是对输入的字符串进行判断,筛选出小写,即只允许输入 [0-9A-Za-z] 范围内的字符
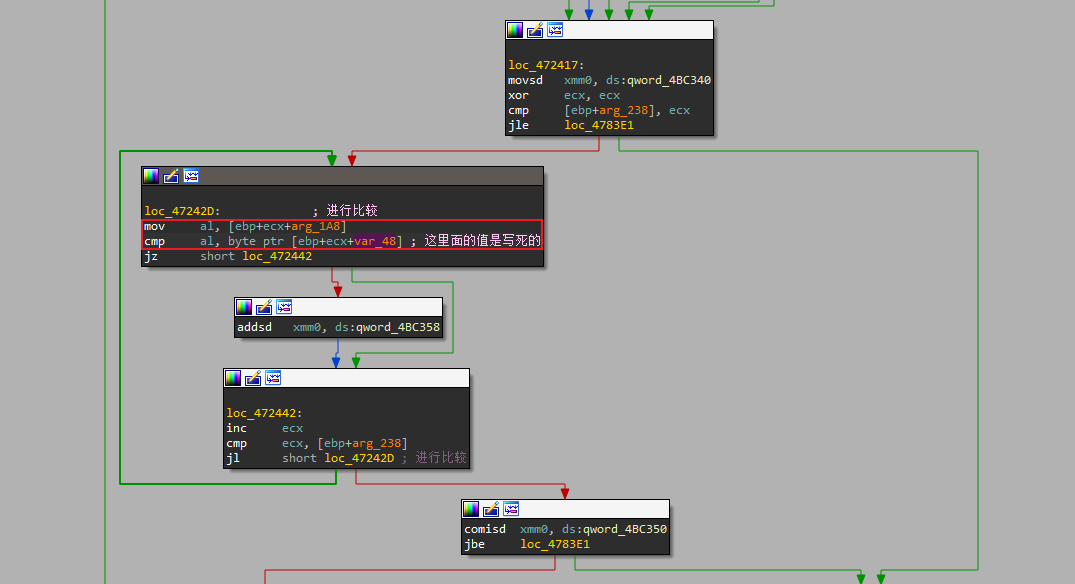
- 继续往上分析,找到导致跳转的源头,结合OD进行分析,可以得到,这里对栈中的值进行了比较,若两处的值完全相同,则会进入理想的分支中。否则会跳转到”失败1”对应的分支
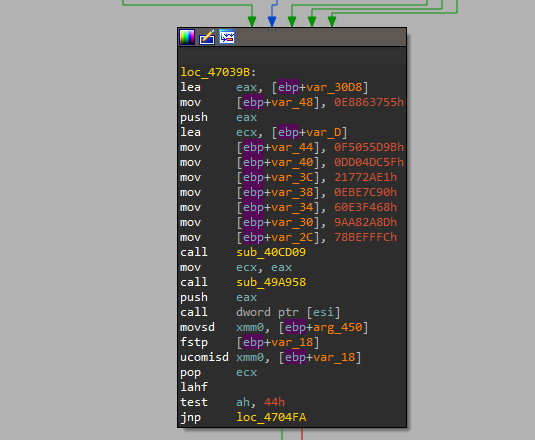
- 通过交叉引用,可以发现,其中进行比较的一个值是写死的,可以直接找到(所以另一个值就是将输入的字符串进行变换得到的了),这里可以先将其记录下
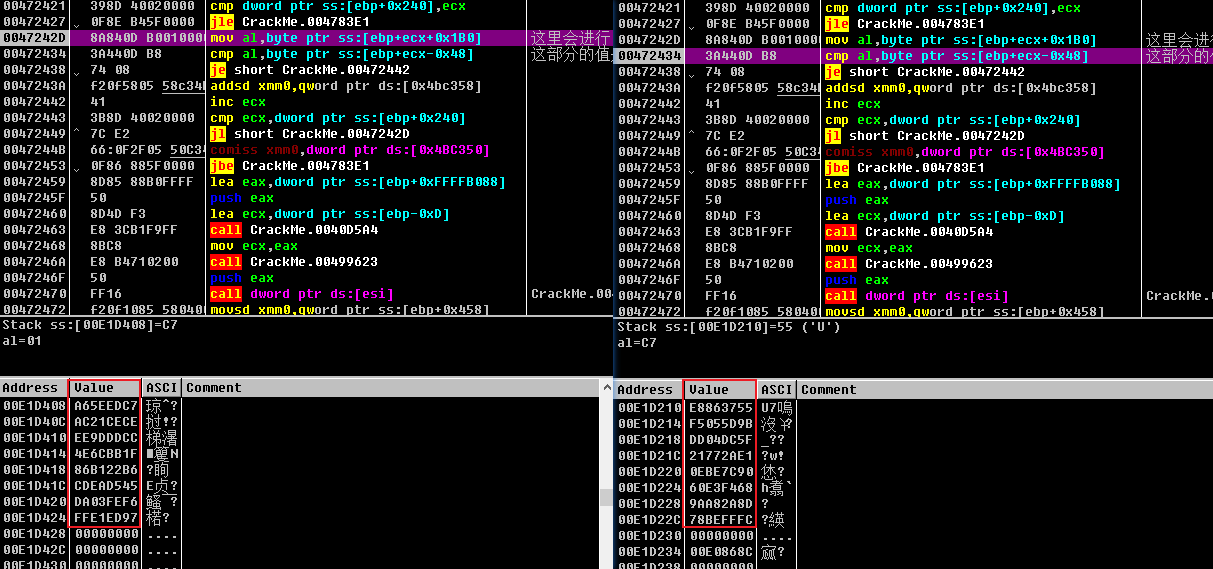
- 这里可以看到,随机输入的字符串,得到的新字符串(暂且称作其为加密字符串),和需要进行比较的结果差距还是很大的。接下来要做的,就是找出字符串是如何经过变换得到加密字符串的
定位字符串的加密逻辑
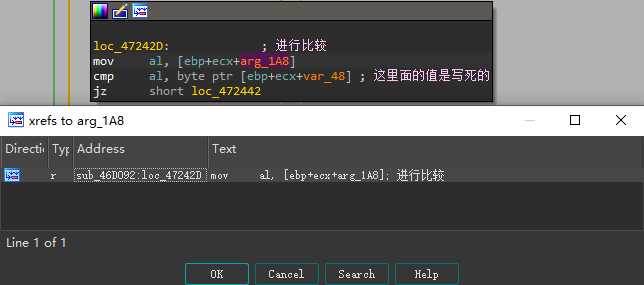
- 我们可以看到在当前函数中是没有其它位置修改了这个值,并且在上一张图中可以看到,在实际情况中,加密字符串位于[ebp+0x1B0]开始的地址处(ecx的值初始为0,每轮加1,用于遍历字符串)。所以接下来,我们就向上回溯,寻找会向地址[ebp+0x1B0]处写入值的函数
- 这里为什么要找[ebp+0x1B0]?上层调用函数栈不是会下降吗?ebp变了,为啥寻址没变?其实我也不知道为啥要这样做,我只是找规律,我通过交叉引用找到调用
sub_46D092的上层函数时,发现在该函数[ebp+0x1B0]的位置,也已经存储了加密后的字符串(这意味着还需要往上层找),尽管sub_46D092中的ebp和上层函数中的ebp值不一样,但是加密字符串都是存在[ebp+0x1B0]处,所以按照规律就这么找了,这里对这个地址下硬件访问断点也可以
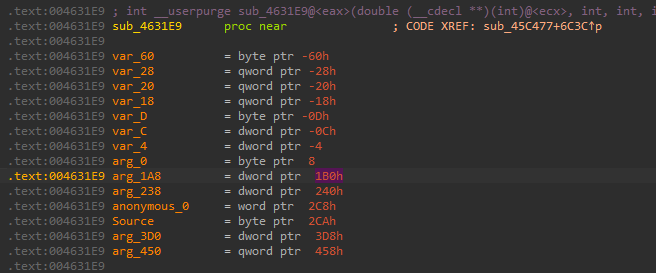
- 然后我们在
sub_4631E9中找到了,arg_1A8对应的刚好是0x1B0。这是sub_46D092上层函数的上层函数
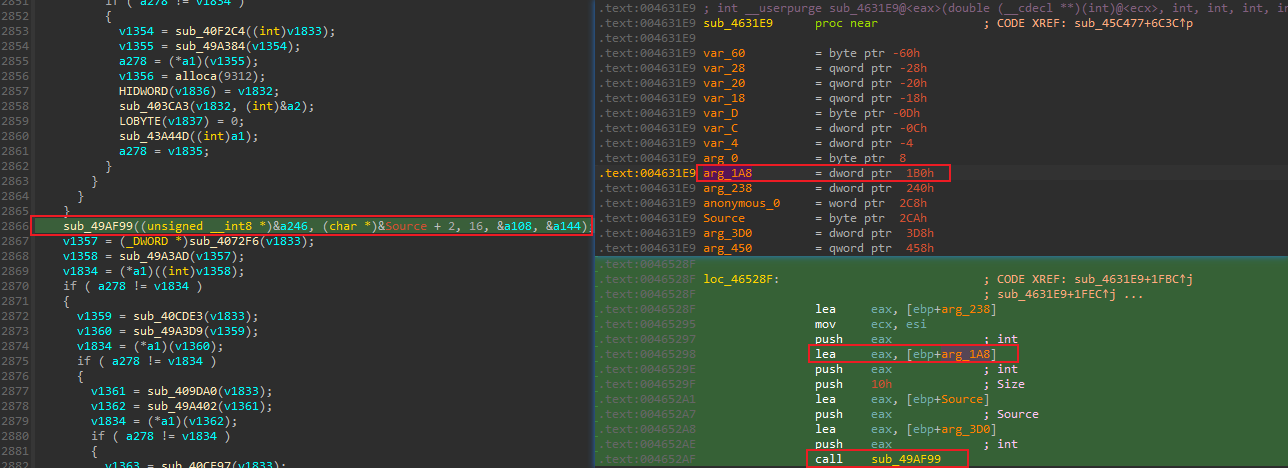
- 接下来,通过交叉引用,可以找到一个函数
sub_49AF99,它将[ebp+0x1B0]这个地址作为参数传了进去
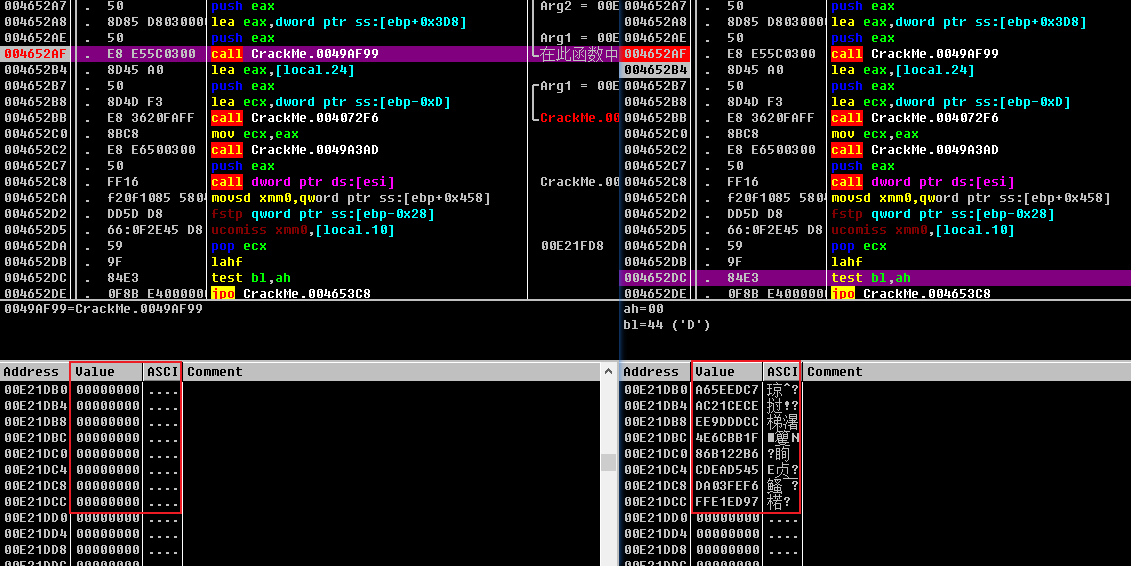
- 单步调试一下,也可以发现,执行
sub_49AF99前,会传入一个空缓冲区,执行后就填充了加密后的字符串,这下可以断定,这里的sub_49AF99就是对字符串进行加密的地方。接下来就可以针对sub_49AF99这个函数进行分析
分析字符串加密逻辑并解密
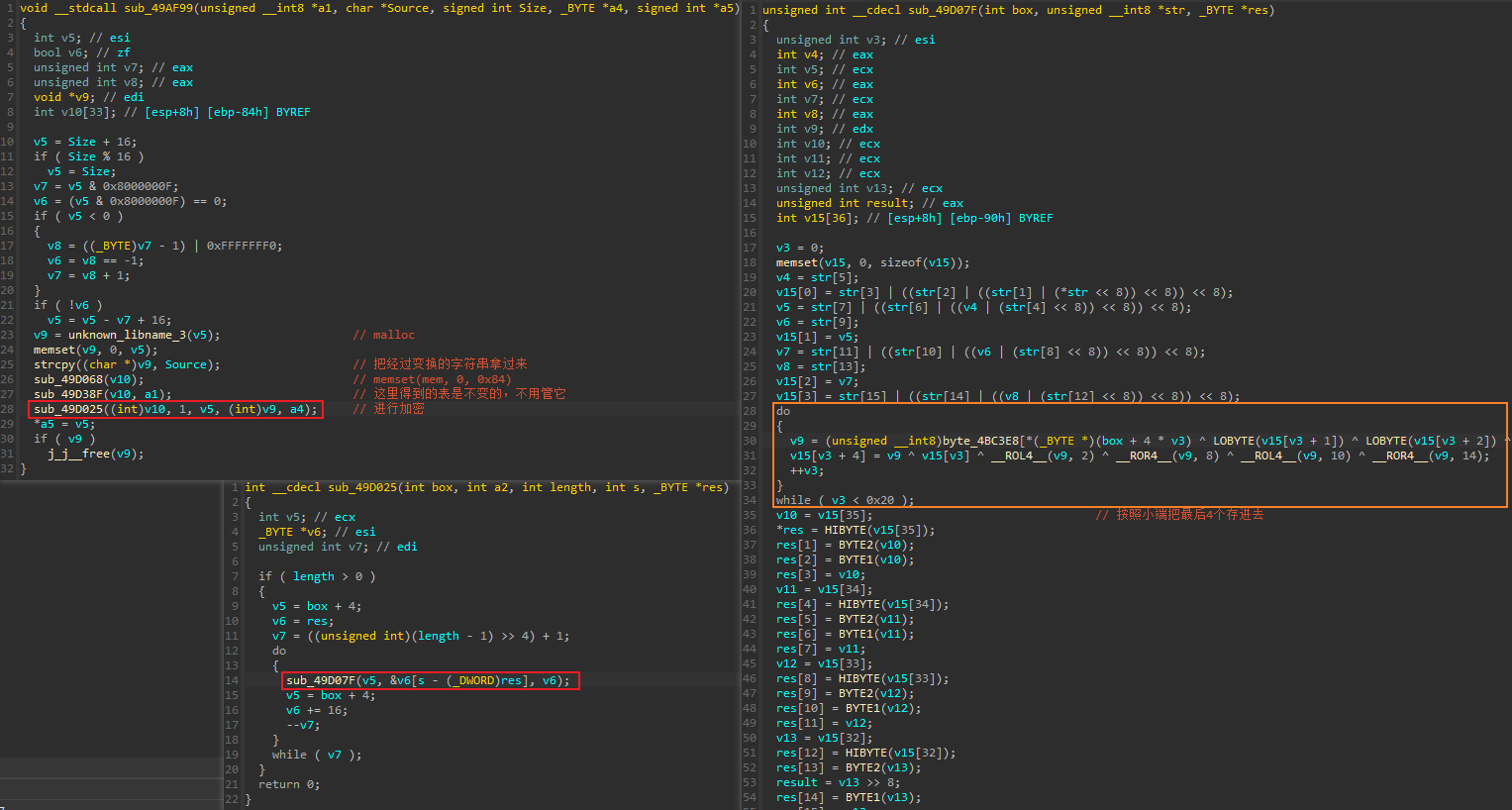
- 这部分主要就是逆向基本功,结合IDA和OD进行分析,然后还原加密的算法。因此这里仅作一些简单的描述。前面讨论的如何定位到这个算法的位置才是关键
- 首先
sub_49AF99有5个参数,a1是用于给字符串加密的密钥(我一开始分析时,没意识到这个是密钥),Source是经过一次变换后得到的字符串,Size是经过变换后字符串的大小,a4存放经过加密后的字符串 - 这里的
unkown_libname_3其实就是malloc,IDA没解析出来,然后依次调用malloc、memset、strcpy,将已经经过一次变换后的字符串,复制到一块新初始化的大小为0x20字节的堆空间中。这里需要补充一点,在单步调试时会发现,此处已经经过变换的字符串其实只有0x10字节,并且strcpy在复制字符串时遇到0x00就会截断。因此也只复制了0x10字节到这个大小为0x20字节的堆块中。那为什么要申请0x20字节的空间呢?咱接着分析 sub_49D068实际上就是memset,初始化一块栈空间,然后调用sub_49D38F,通过密钥a1,生成一个box,实际上就是进行了密钥扩展。我测试了不同的输入字符串,然后在此处下断,发现每次生成的box值是不变的,因此在分析时就直接拿来用了- 接下来调用
sub_49D025进行加密,这里有4个参数,v10为刚刚初始化的box,v5是存放字符串的堆块的大小(这里是0x20,前0x10存着经过变换的字符串,后0x10字节是0),v9是堆块首地址,指向字符串第一个字符,a4用于存放加密后的字符串 - 进入
sub_49D025,这有一个循环,v7计算出的值为2(因为length的值为0x20),所以会循环两次,分别去调用sub_49D07F去计算加密字符串的结果,一次加密16个字节。所以sub_49D025实现的是多块加密,sub_D07F实现的是单个块加密。这里也可以看出来,输入的字符串经过变换后只剩下0x10字节,但加密时仍然会分块加密,一共加密0x20个字节,并且第二次加密的0x10字节所使用的字符串全为0 - 进入
sub_49D07F,就是加密算法了,这部分可以先将功能逆出来,然后再写出解密算法,还原的代码如下:
1 | # 加密算法 |
- 在还原加密算法时,那块比较复杂的加密,实际上是IDA解析的不清晰,直接看汇编会更方便一些。并且那个循环0x20次的算法是自旋的,自旋15次就可以解密,虽然解密时不一定需要自旋,直接逆过去解密也是ok的,具体解密代码如下:
1 | # 解密算法 |
- 我们知道,加密字符串有一个比较的值是写死的,所以我们带入加密后的字符串,分别进行解密,可以得到如下的结果,
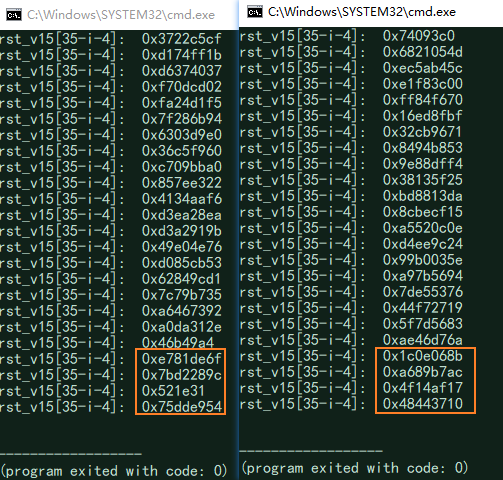
- 将图中橙色方框按照顺序,以小端方式写入那个已经经过变换后的字符串堆块(在执行
sub_49D07F之前,strcpy之后)中,然后F9执行
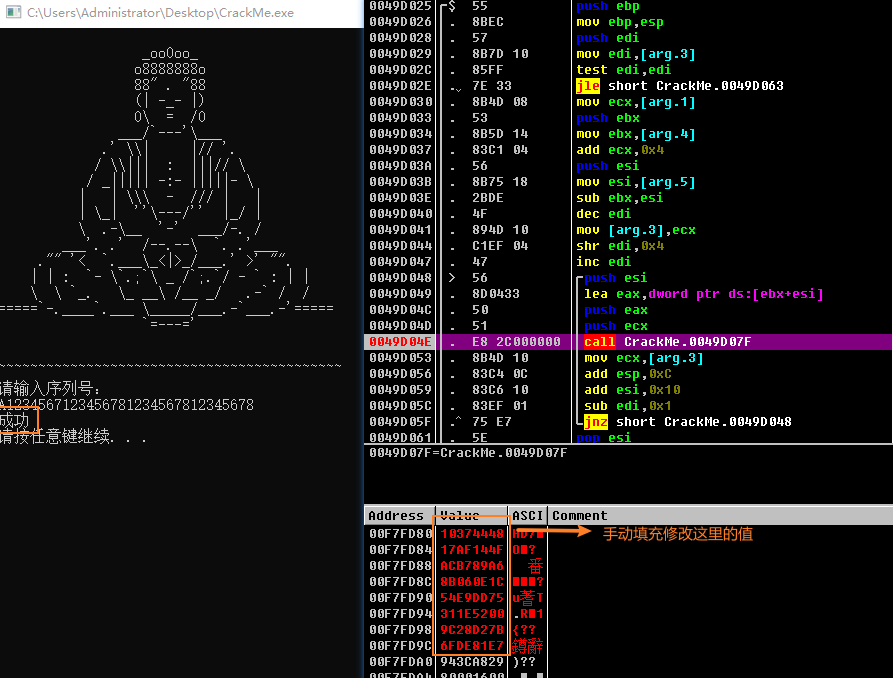
- 可以发现,这么做,进行手动修改加密前的字符串,是可以执行成功的,也说解密的程序是没有问题的,但是这里还存在两个问题
- 第一个问题,这里想要成功执行,意味着在加密前,堆块里必须是如图所示的0x20字节的字符串,然而在起初用任意字符串进行尝试时,这里仅有0x10字节的字符串,后面0x10字节都是0,经过加密后,与设定的数据无法匹配
- 另一方面,这里的数据包含了
311E5200,在先前进行strcpy时,遇到0x00就会截断,因此即使输入的字符串经过变换后,能够达到图中所示的0x20字节的字符串,但是在进行strcpy时也会进行截断,导致最终执行到这一步时,字符串已经不是图中所预测的那样,那么执行仍然是失败。此时,只能将希望寄托于字符串之前经历的次变换,但是,即使经过此变换可以做到将输入的0x10字节字符串转换为上图所示的0x20个字节的字符,仍然解决不了strcpy截断的问题,但,也只能孤注一掷了
找到其他对输入字符串的变换操作
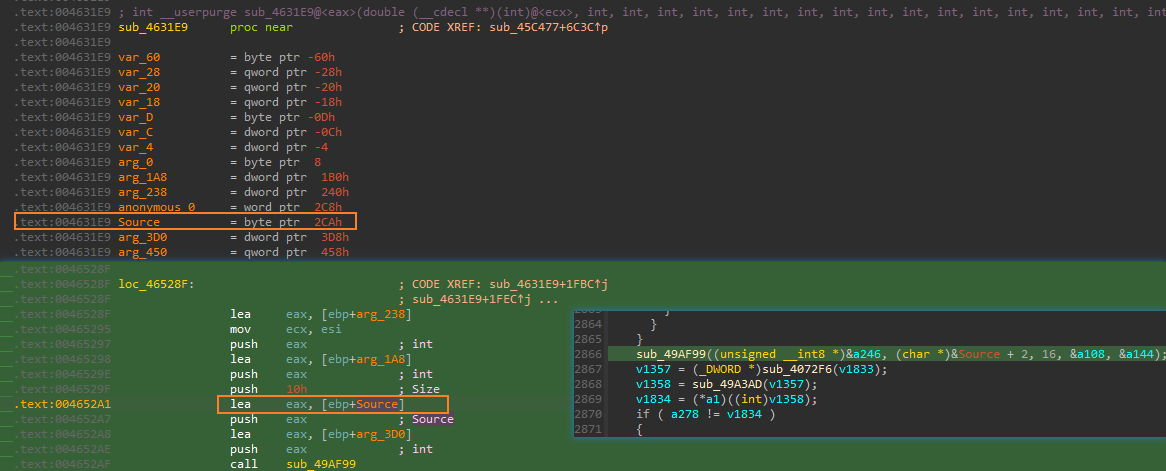
- 找字符串变换逻辑和找字符串加密逻辑一样,从这里可以看到,字符串作为参数传入
sub_49AF99时位于[ebp+Source]也就是[ebp+0x2CA],然后据此通过交叉引用向上找,看看上层函数是否有修改[ebp+0x2CA]的地方
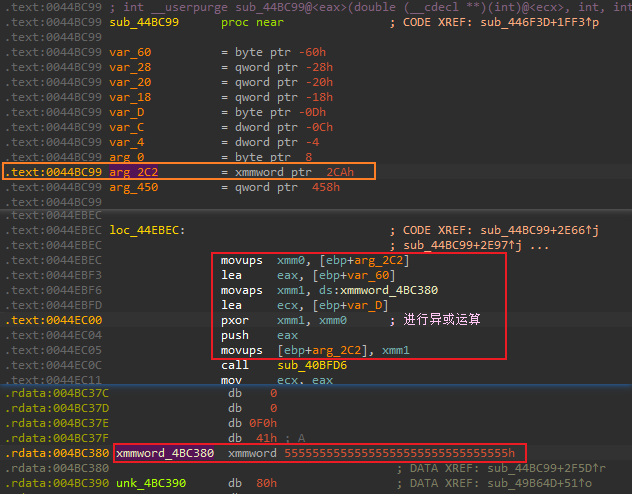
- 不断的往上找,可以发现在函数
sub_44BC99中使用到了[ebp+0x2CA]这个栈空间,在该函数的基本块loc_44EBEC中,将输入的字符串与一个写死的全局变量进行了异或运算,可以看到这个全局变量就是”55555555555555555555555555555555”
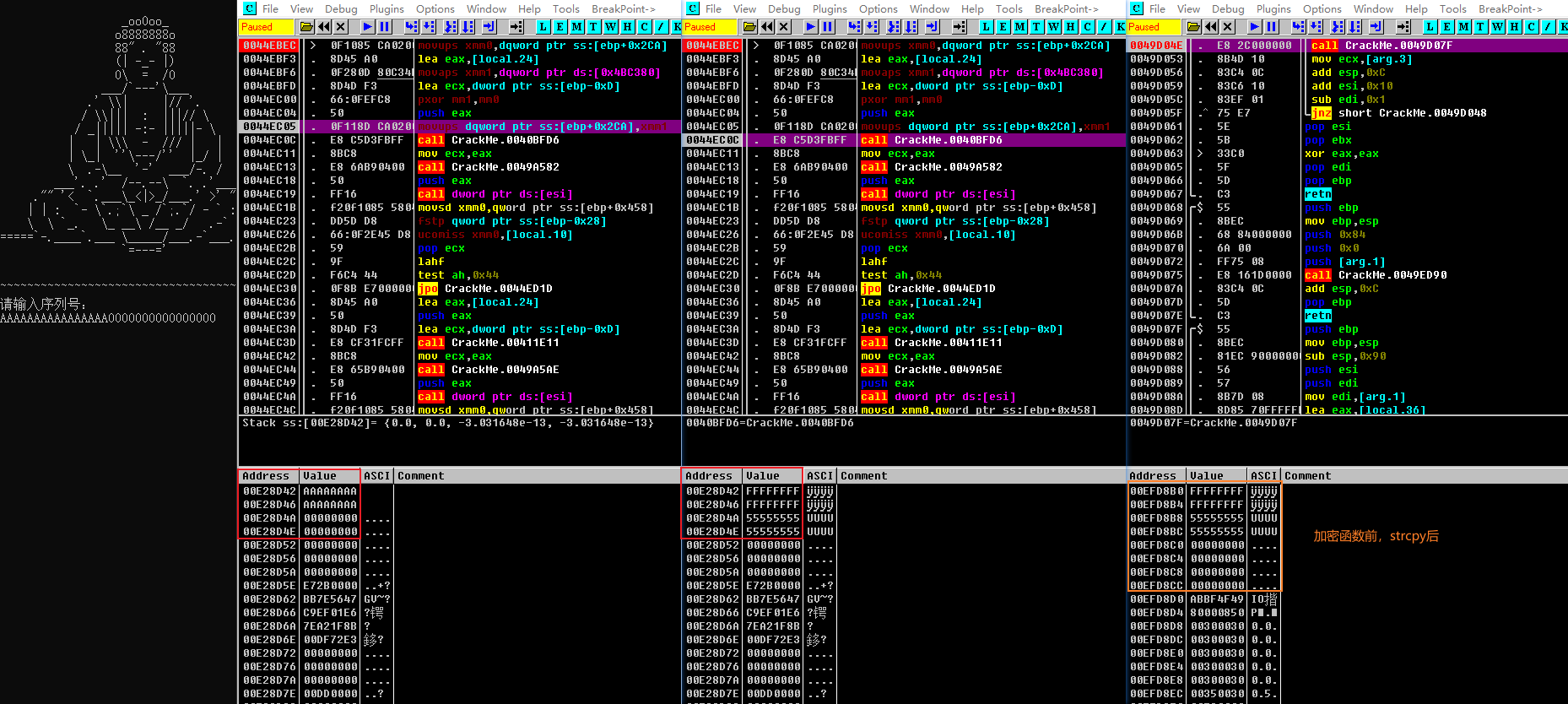
- 由上图可以看到,当我们输入”AAAAAAAAAAAAAAAA0000000000000000”后,最终被加密的字符串就是和”55555555555555555555555555555555”异或后的结果。所以,依然是没能解决之前
strcpy截断的问题,并且经过异或后,也无法解决后16个字节为0的问题
纠错
总感觉就只差一步,但最终还是无能为力,直至题目结束,看了6位大佬的wp,咨询了出题的师傅,才豁然开朗
sm4加密算法
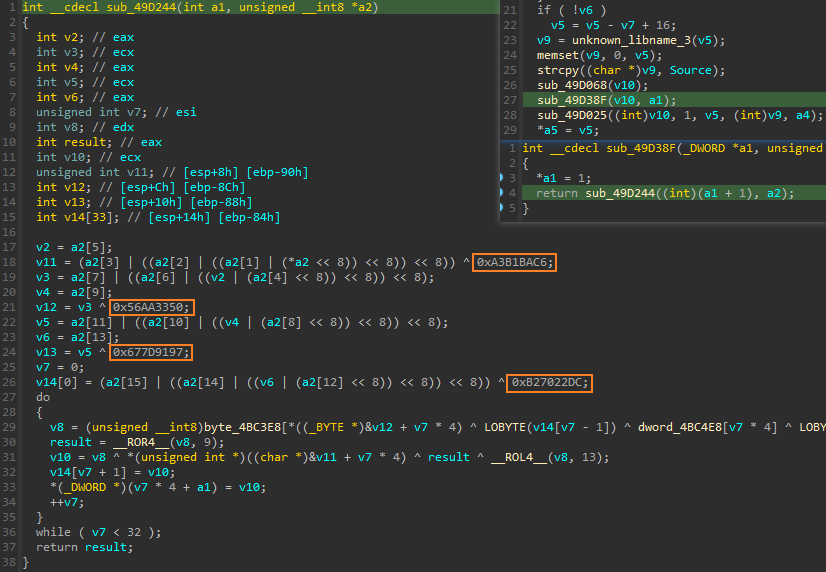
首先是对字符串进行加密的算法是SM4加密,由于自身的算法意识浅薄,看不出来(第三题的AES也没看出来),这也导致了始终发现不了最后的坑,Findcrypt也只识别出了MD5和Base64
不过还是有一些特征的,在对进行密钥进行扩展的函数里,可以找到4个常量,搜索一下这4个常量就可以发现这是一个SM4的加密算法。这一点在mb_mgodlfyn的文章中有提到
反调试机制
- 这道题涉及到多种反调试手法,这一点在深山修行之人在他的文章进行总结,其中一种,就是修改SM4的密钥key
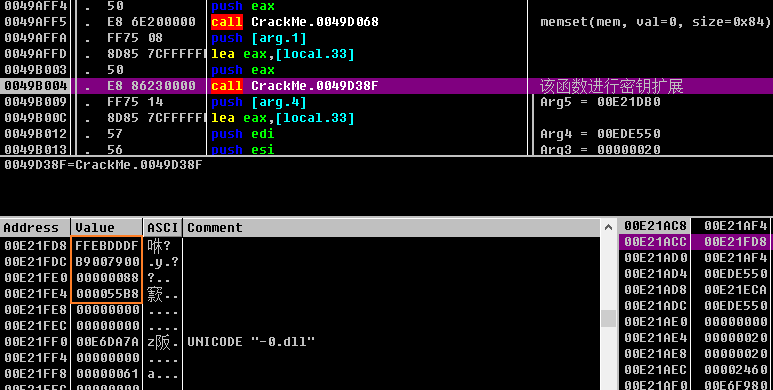
- 在使用调试器的情况下,用于进行函数扩展的密钥如图中橙色方框所示,此时按照mb_mgodlfyn大佬的思路patch在这个基本块Patch一个死循环,然后再附加(这样就可以过掉反调试了,或者像中午吃什么大佬那样,注入自己的Dll,在算法前后打印出相应的参数值),然后比较一下密钥的值
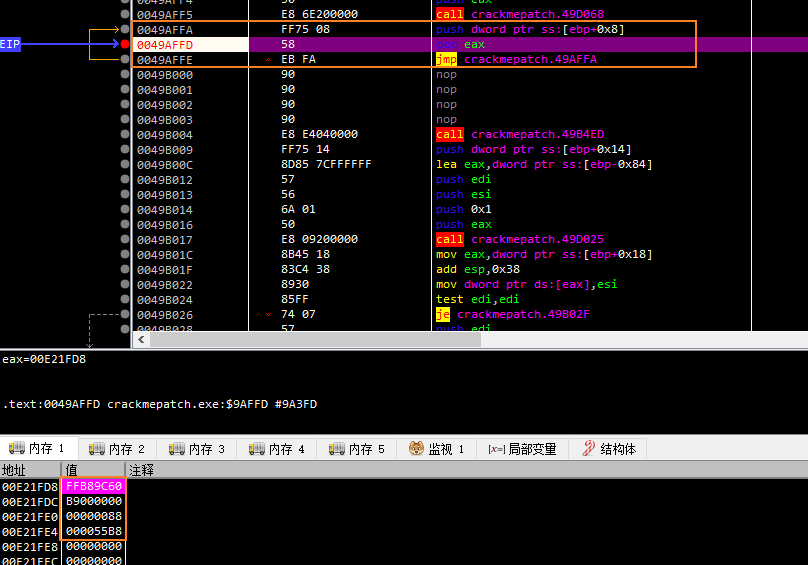
- 这里OD附加不了Patch的程序,所以用了x32dbg,可以看到,Patch后停下来得到的密钥确实和原先的不一样。或许这就是真实的密钥
更新解密算法
- 有了真实的密钥,我们可以再跑一遍程序,用真实的密钥替换被修改的密钥进行运算,重新计算出box:
1 | # 更新后的解密算法,这里更改了box的值 |
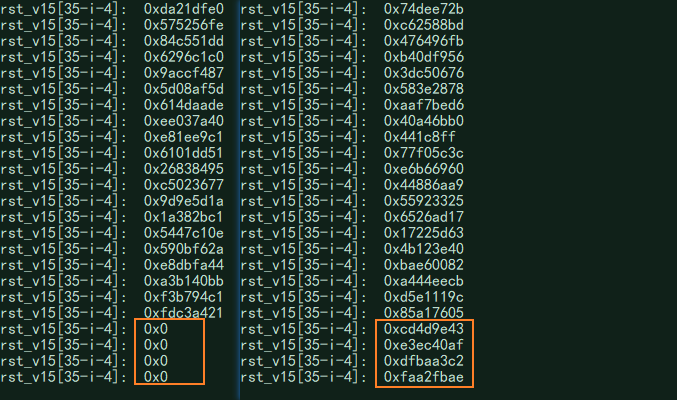
- 修改box后重新运行一遍解密程序,可以发现,用于匹配的字符串后半部分算出来刚好是0,也就是说,确实只用到了前16字节进行运算。然后我们拼接一下算出的结果,就可以得到”FAA2FBAEDFBAA3C2E3EC40AFCD4D9E43”,与”55555555555555555555555555555555”进行异或,就可以得到”AFF7AEFB8AEFF697B6B915FA9818CB16”。带入到程序中,成功运行

小结
在这次一步步摸索做题的过程中,通过不断调整思路,最终找到了题目的几个核心点,只可惜,最后输在了经验。失败总是好事,失败了可以总结可以反思,可以学到更多东西,可以发现自己的盲点,一开始败的很惨也没事,只需要再多败几次,就会比1年前的自己强上个很多倍了!






