前言
前一篇基于 64 位操作系统,对 glibc2.31 源码中 malloc 的部分进行了详细分析,本篇衔接前一篇接着 free 部分的源码分析
__libc_free 主流程
__libc_free() 的流程不复杂,这里圈出 4 个部分来看,以看的更为清晰:
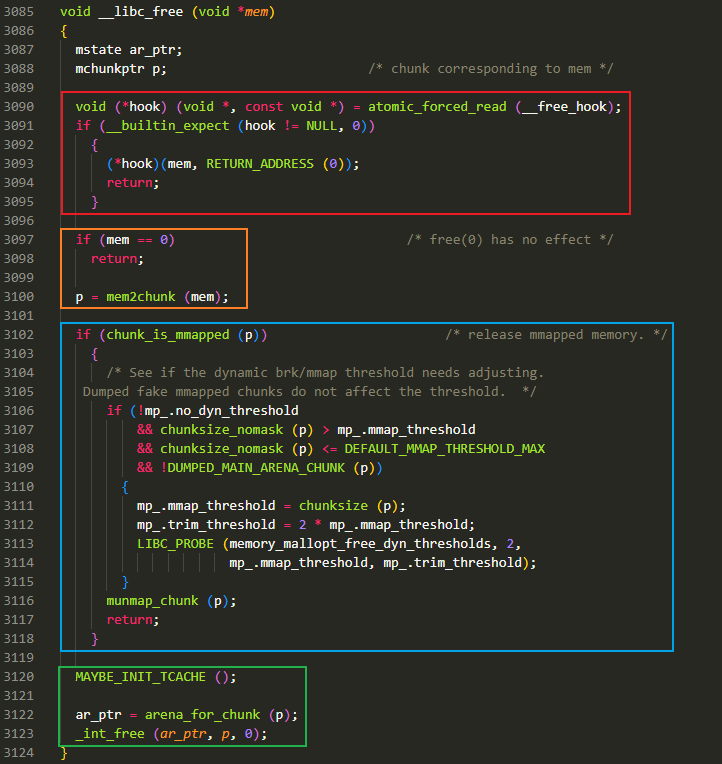
红色方框:
这部分是针对 hook 函数的处理,若存在则调用 hook 函数并返回;从 glibc2.34 版本开始,此处的 hook 处理已被删除
橙色方框:
第一处判断
mem == 0,实际上是对free(0)情况的处理;接下来调用宏mem2chunk将需要被 free 的指针转换为 chunk 的首地址,以方便后续处理蓝色方框:
这部分主要是进行映射内存(mapped memory,即通过
mmap()系统调用申请的内存)释放的处理,若开启了mmap()分配阈值动态调整机制(no_dyn_threshold 值为 0),则会根据 释放的内存大小动态调整 mmap 分配阈值(mmap_threshold)与 top chunk 的收缩阈值(trim_threshold)绿色方框:
先调用
MAYBE_INIT_TCACHE判断 tcache 是否存在,若不存在则进行 tcache 初始化,调用arena_for_chunk获取需要释放的 chunk 所在的分配区,然后调用_int_free()完成对该 chunk 的释放,此时传入的参数 p 为需要释放的 chunk
_int_free 主流程
初始校验
_int_free() 有 3 个参数,av 是 chunk 所在的分配区,p 是 chunk 的首地址,have_lock 是个锁标志,默认为 0。进入函数后先获取 chunk 大小,然后进行一系列 check:
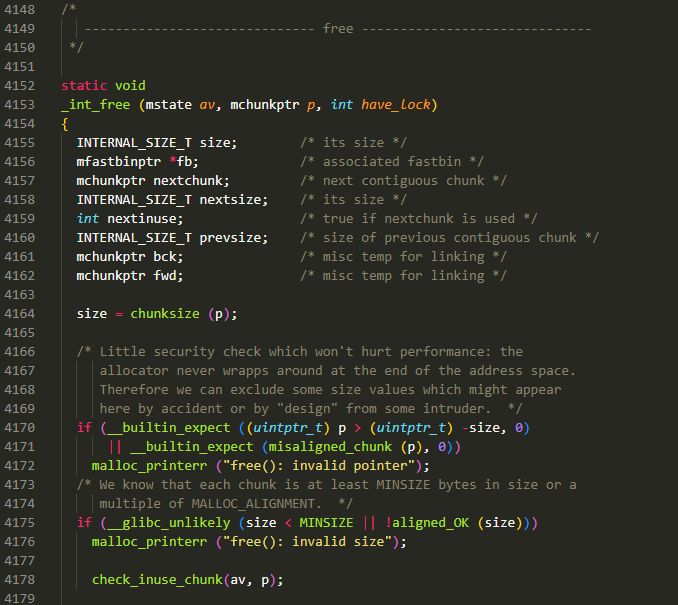
- check 1:
(int(p) > int(-size)) == 0,翻译过来就是 chunk 的地址不能比负的 size 大,size 往往是一个相对较小的数,例如 0x20,取负后就会变成一个很大的数,例如 0xffffffE0,在 Linux 进程地址空间中,这样的地址属于内核地址,若 chunk 地址在这个范围,很可能是被覆盖了,因此会进行报错处理chunk2mem(p) & 0xf == 0,这里我简化了这个宏,0xf 实际上是SIZE_SZ * 2 - 1的结果,这个值在 64 位下就是 0xf。经过 chunk2mem 则是获取原本指针的值,这个值经过chunk地址 + 2*SIZE_SZ计算的结果,而 chunk 地址本身是按照SIZE_SZ*2进行对齐的,因此经过chunk2mem计算后的地址,也应该是按照SIZE_SZ*2对齐的,那么该值在和 0xf 进行与运算时,得到的结果应该为 0,若不为 0,说明 chunk 地址未对齐,则应报错
- check 2:
size < MINSIZE,将要释放的 chunk 大小比 chunk 最小分配的大小 MINSIZE 还要小,显然是出错了aligned_OK(size) == 0,这个和上面的 check 类似,只不过这个是对 size 的对齐进行 check,上面那个是对 chunk 地址对齐进行 check
- check 3:
check_inuse_chunk,这个宏会进一步调用do_check_inuse_chunk(),该函数会检查 chunk 是否为正在使用的,即检查该 chunk 的后一块的 prev_inuse 位进行判断,防止 double free 的情况发生
Tcache 处理流程
如果开启了 tcache(glibc2.31 中默认开启),则会进入下面的代码块:
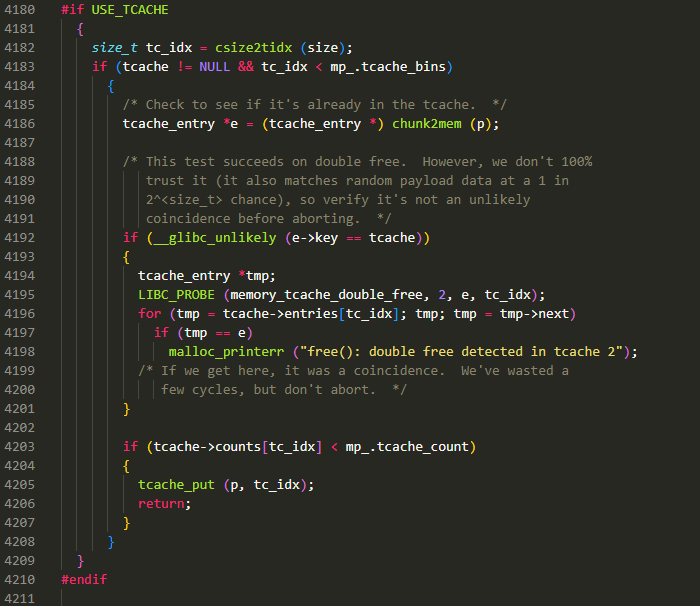
外层 check:
- 判断 tcache 是否已初始化
- 判断 tc_idx 是否在 tcache bin 数目的范围内(tcache bin 最多有 64 个,因此经过
csize2tidx计算得到的值应小于 64)
若满足上述两个条件,则调用
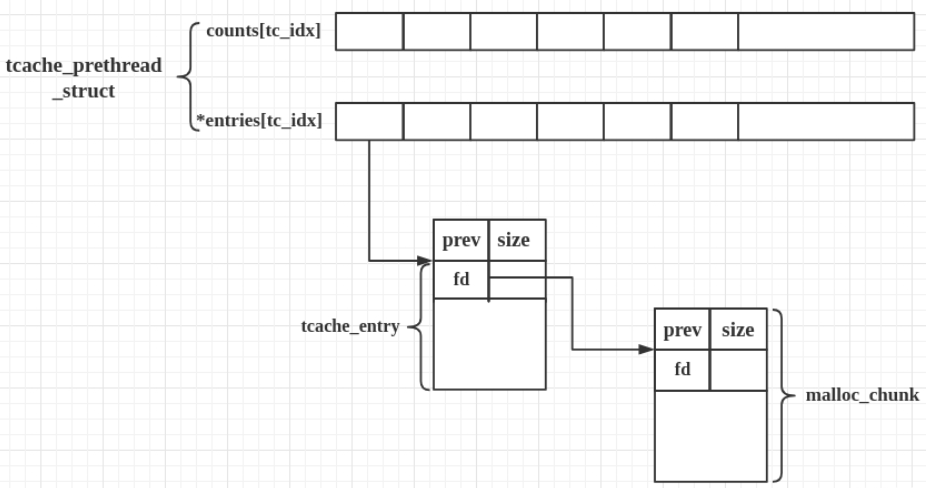
chunk2mem获取这个将要被 free 掉的 chunk 的 tcache_entry,为什么要这么做?因为 tcache_entry 本身就是 malloc_chunk 结构体,当 chunk 进入 tcache bin 中后,它使用了 malloc_chunk 结构体的 fd/bk 两个字段。这里通过
chunk2mem获取到 malloc_chunk 结构体的 fd 所在的地址,刚好就是当前 chunk 对应的 tcache_entry 的地址。可参考下面关于 tcache 结构关系的这张图。获取到 tcache_entry 后可用于接下来的判断。内层第一个 check:
- 判断 e->key 是否等于 tcache 首地址
在通过
tcache_put()将 chunk 放入 tcache bin 的过程中,会将 chunk 对应的 bk 字段(即 tcache_entry->key 字段)设置为 tcache 的首地址,这里若相等,说明该 chunk 可能已经进入 tcache bin 中,若继续释放可能会造成 double free。不过这里为了排除因为随机有效载荷的干扰,会进一步遍历该 tc_idx 对应的 tcache bin 上的所有 chunk,判断是否与当前将要释放的 chunk 相等,来确保结果的严谨内层第二个 check:
- 判断 tc_idx 对应的 tcache bin 中 chunk 的数量是否小于最大值
tcache bin 中最多包含 7 个相同大小的 chunk,若当前 tcache bin 中 chunk 的数量低于 7 个,那么 free 掉该大小的 chunk 就会进入该 tcache bin 中。这里若能通过该判断,则会调用
tcache_put()将 chunk 放入该 tc_idx 对应的 tcache bin 中
Fast Bin 处理流程
check 部分
如果对应大小的 tcache bin 满了,就会执行到这,这里是对 fast bin 处理的逻辑,可以分为两个部分来看,先来看 check 部分:
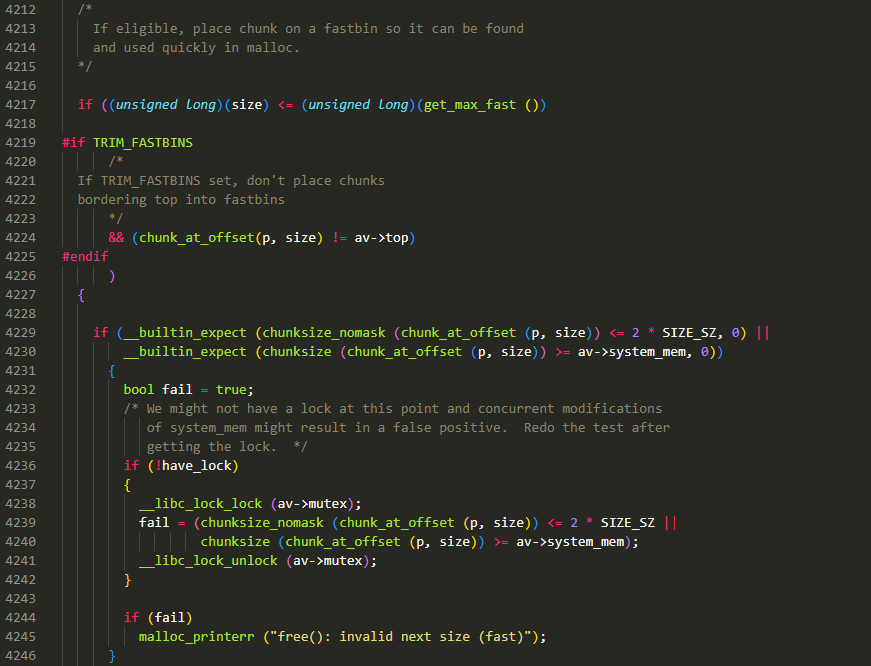
外层 check:
- 要 free 的 chunk 的大小是否位于 fast bin 范围内
- 开启了 TRIM_FASTBINS 模式下(默认为 0,不开启),则该 chunk 不能紧挨着 top chunk
满足上述条件,则进入 fast bin 处理流程
内层 check:
- chunk 不能小于 MINSIZE
- chunk 不能大于 system_mem
这俩属于对于 size 的常规检测,之前的分析中已经多次遇到。只是这里它处理的会更严谨些,为了排除多线程的干扰,会给 chunk 所属的分配区上锁后,重新进行一次判断,若这次判断还是出问题,则说明 size 确实是个非法的值,然后报错退出
free 部分
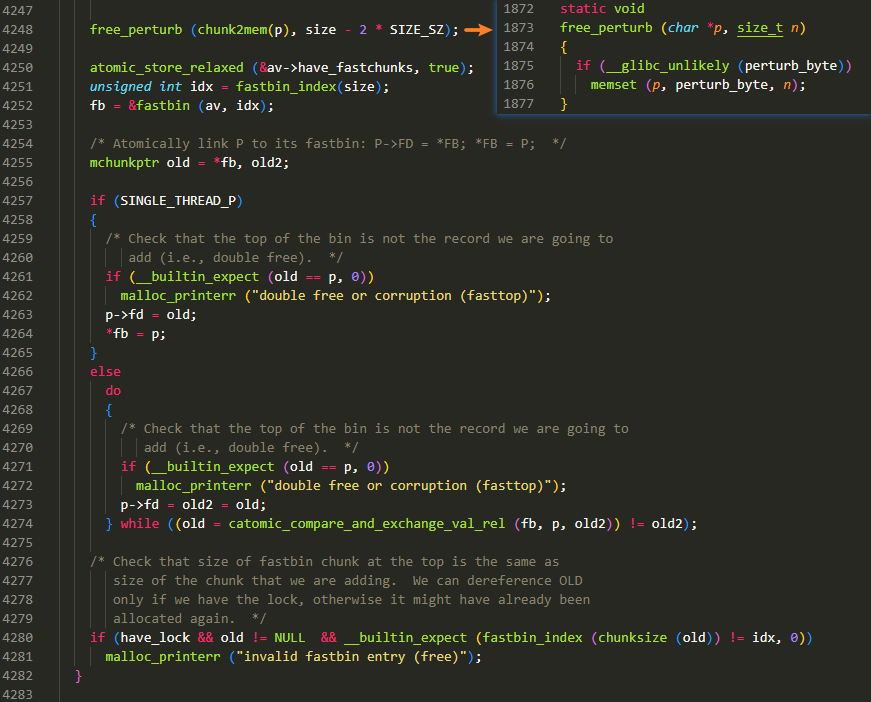
free_perturb()实现了一个memset操作,前提是需要设置用于填充缓冲区的值 perturb_byte,该值默认为 0,故不会进行memset操作,所以这里可以忽略atomic_store_relaxed()我没弄明白这个函数是干嘛的,在 glibc2.23 版本中,这里的语句是set_fastchunk(av),用来初始化 fast bin,所以我感觉这里起到的功能应该类似吧- 接下来拿到要被 free 的 chunk 在 fast bin 中的 idx 以及对应 bin 的链表头,然后开始进入 fast bin:
- 对于单线程的情况,直接用头插法将 chunk 放到链表头所指向的位置,到时候分配的时候,也是优先分配这个位置,因此 fast bin 是先进后出(FILO)
- 对于多线程的情况,则是通过 lock-free 的技术实现单向链表链入第一个 node 的操作,本质上和单线程的处理方式一致
- 上述两种情况,都会根据链入的 chunk 和原先该位置的 chunk 是否一致,来判断是否出现 double free 的情形
- 最后有一个 check,判断我们插入的 chunk 与原先顶部的 chunk 大小是否一致,因为 fast bin 要求每条 bin 上的 chunk 大小相同。不过这个 check 仅在分配区上锁的情况下才会进行
Bins 处理流程
check 部分
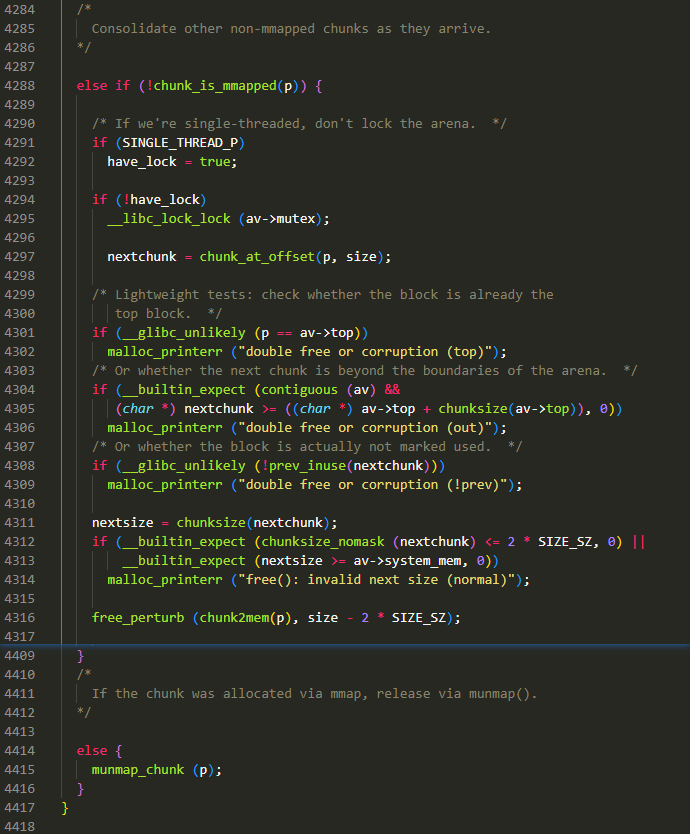
这里的 else if 对应前面 fast bin 判断处的 if 以及最末尾处的一个 else,逻辑如下:
- if: 在 fast bin 范围内,进入 fast bin 处理流程
- else if: 不是通过
mmap()系统调用申请的内存,则进入 bins 处理流程(unsorted bin,small bin,large bin 都位于 bins 中) - else: 直接调用
munmap_chunk()释放 chunk
进入 else if 语句,开始会对单线程 / 多线程进行判断,如果是多线程的场景,需要对分配区进行加锁。然后通过
chunk_at_offset获取到后一个 chunk 的地址接下来是一系列 check:
check 1:
p == top chunk,top chunk 只会被分割,不会处于 inuse 状态,若 free 的是 top chunk,说明出错了check 2:
contiguous(av),参考了xi@0ji233师傅,他说这里是检查分配区上的 flagsnextchunk...,下面这个校验太长了就不写了,主要是判断 nextchunk 的首地址,是否超过了 top chunk 的边界,若超过了,说明要被 free 的 chunk 自身的数据区也超过了 top chunk 的范围,也就出错了
check 3:
prev_inuse(nextchunk) == 0,这个就是判断自己是不是在使用中,因为此时还没进行 free,nextchunk 的 prev_inuse 应该设置为 1,若该值为 0,说明这个 chunk 已经是 free 状态了,就可能造成 double freecheck 4:
这里主要是对 nextchunk 的 size 进行 check,前文已多次出现,目的是防止在向后合并时出现问题
最后调用
free_perturb()进行memset,当然,还是大概率不会执行
向前合并
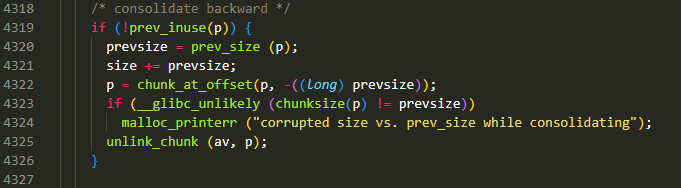
这里的逻辑是尝试(当前一个 chunk 处于 free 状态时就会进行合并)将当前 chunk 与前一个 chunk 进行合并,然而注释的英文却是 consolidate backward,不过无所谓,能理解它的意图就行,这里作简单解析:
- 通过当前 chunk 拿到 prevsize
- 将当前 chunk 的 size 与 prevsize 相加
- 将当前 chunk 的首地址设置为前一个 chunk 的首地址,这样就相当于合并了,不过此时还没有修改合并后 chunk 的 size 字段
- 检查一下前一个 chunk 合并前的大小
- 调用
unlink_chunk()将前一个 chunk 从链表(bins 上的链表都有可能)上断链,最后再注意一点,若发生了合并,此时的当前块,已经为合并后的 chunk,但是该 chunk 的 size 字段此时暂未修改
向后合并
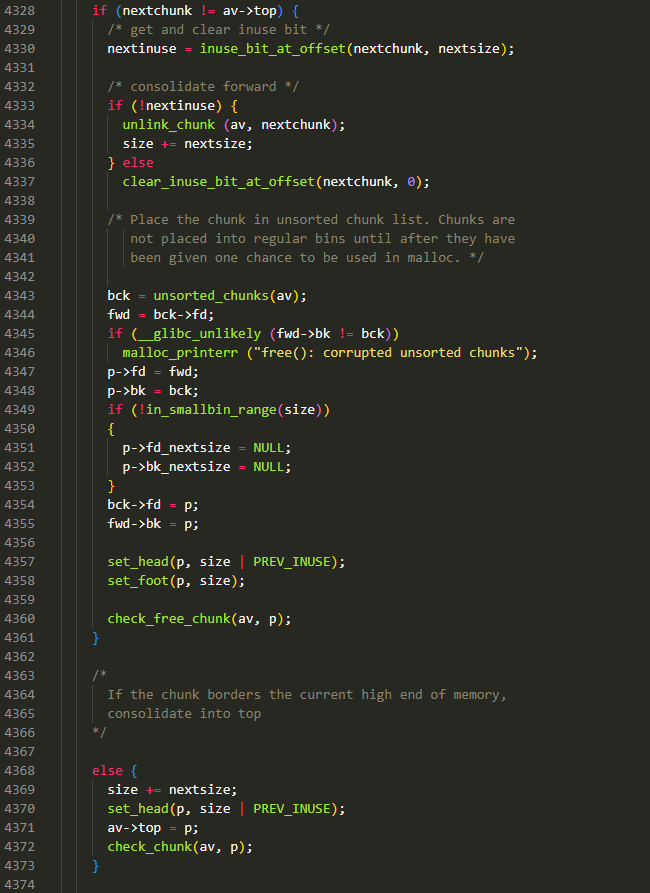
首先先判断后一个块是不是 top chunk:
- 如果是,进入 else 语句,直接修改当前块为 top chunk,然后设置 top chunk 的 size 为合并后的 size,设置分配区的指向新的 top chunk 地址
- 如果不是,那么判断一下 nextchunk 是否是 inuse 的:
- 如果是 inuse 的,那么将 nextchunk 的 prev_inuse 设置为 0,意思是不合并 nextchunk 了,并告诉 nextchunk 你前面的块是 free 的
- 如果不是 inuse 的,将 nextchunk 断链,然后将 nextsize 加到 size 上,表示 nextchunk 也要加入合并
- 接下来,将合并后的 chunk 链入到 unsorted bin 中,并根据情况设置 size,prev_size,fd_nextsize,bk_nextsize 等字段
堆收缩
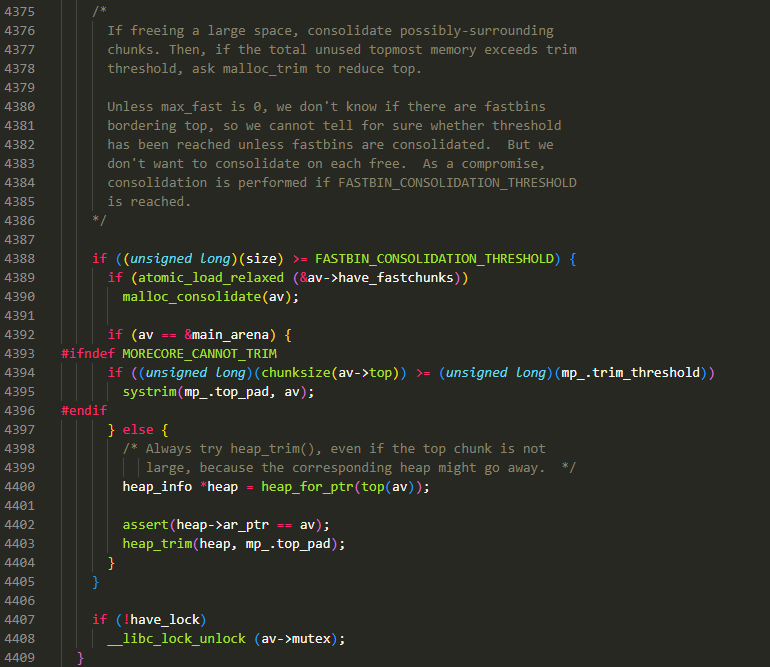
- 首先判断释放的内存大小是否超过了阈值 FASTBIN_CONSOLIDATION_THRESHOLD(0x10000),
- 如果没超过,则不作处理
- 如果超过了,那么会先触发 fast bin 合并机制
- 若 fast bin 存在,则调用
malloc_consolidate()将 fast bin 进行合并 - 然后作进一步判断:
- 如果 free 的 chunk 位于主配分区(main_arena),且未设置 MORECORE_CANNOT_TRIM(不允许收缩内存),且 top chunk 的大小超过了 top chunk 的收缩阈值,那么就会调用
systrim()收缩内存 - 如果 free 的 chunk 位于非主分配区(thread_arena),那么找到分配区(malloc_state)对应的堆(heap_info),然后调用
heap_trim()收缩堆
- 如果 free 的 chunk 位于主配分区(main_arena),且未设置 MORECORE_CANNOT_TRIM(不允许收缩内存),且 top chunk 的大小超过了 top chunk 的收缩阈值,那么就会调用
- 若 fast bin 存在,则调用
- 最后判断一下如果是多线程的 free 情形,则将先前对分配区加的锁给去掉